
This article is part of the Comprehensive Guide to Generative AI. Each chapter builds on the last to explain how modern AI retrieves, reasons over, and acts on information.
As optimization shifts from rankings to being retrieved, reasoned over, and cited by AI systems, this chapter explains why technical SEO remains the foundation of visibility in AI-powered search and retrieval.
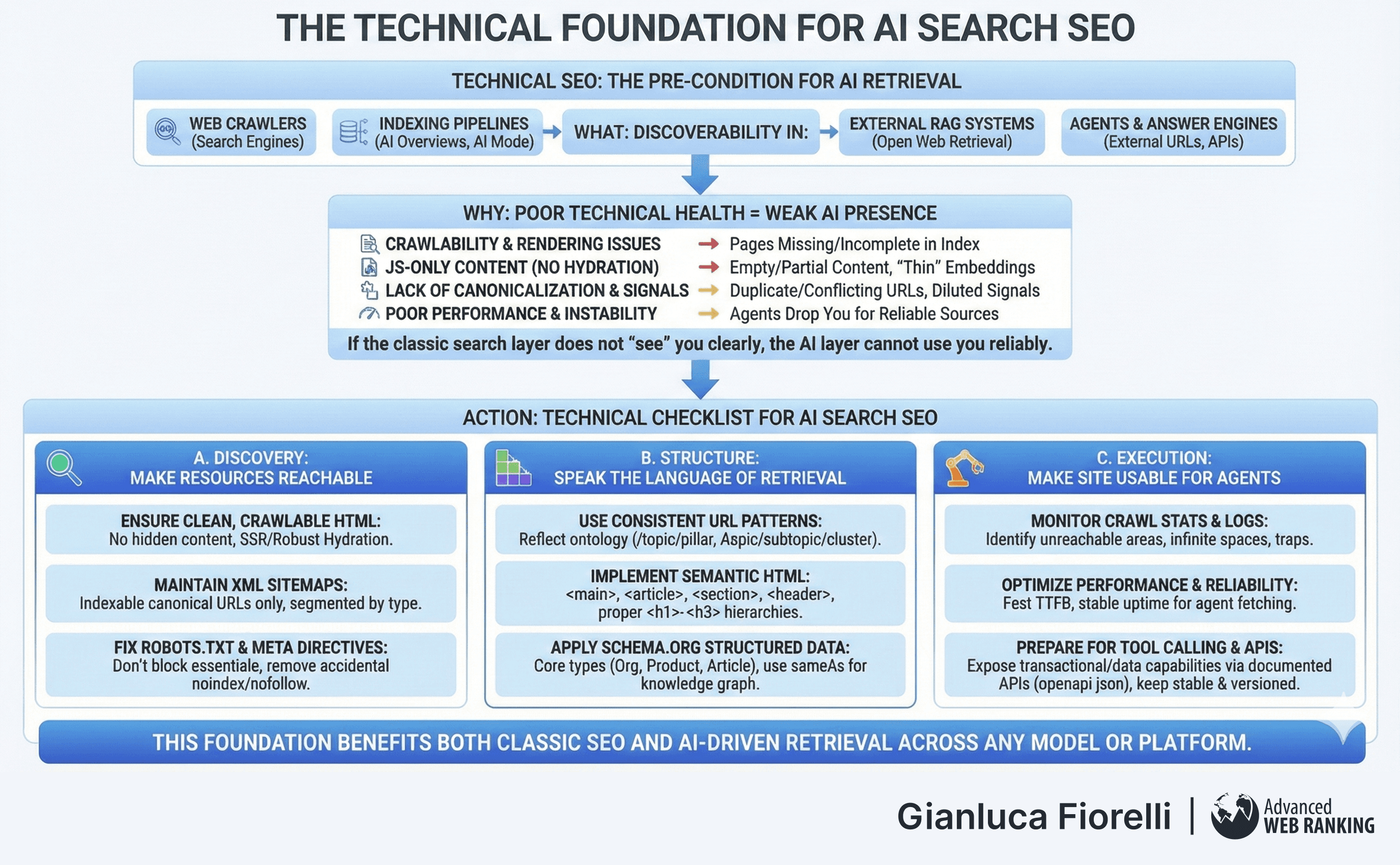
What: Technical SEO as the Pre-Condition for AI Retrieval
Technical SEO is the precondition for discoverability in:
Web crawlers that feed search engines.
Indexing pipelines used by AI Overviews, AI Mode, Web Guide, and similar features.
External RAG systems that use the open web as a retrieval layer.
Agents and answer engines that call external URLs or APIs.
If your site is hard to crawl, slow, unstable, or opaque to machines, you are simply not present in the document pools and indexes from which AI systems select their sources.
Why: Poor Technical Health = Weak AI Presence
Across Google, Bing/Copilot, ChatGPT browsing, Gemini’s web access, Perplexity, and custom RAG systems, technical issues have similar effects:
Crawlability & rendering issues → Pages are missing or incomplete in the underlying index; they cannot be retrieved as candidates for answers.
JavaScript-only content without proper hydration or fallbacks → Agents and retrievers may see empty or partial content, leading to “thin” or irrelevant embeddings.
Lack of canonicalization & structured signals → Duplicate or conflicting URLs dilute the embedding and entity signals associated with your brand.
Poor performance & instability → Agents and answer engines that call your pages/tools may drop you in favour of more reliable sources.
In other words, if the classic search layer does not “see” you clearly, the AI layer cannot use you reliably.
Action: Technical Checklist for AI Search SEO
You can organise the technical foundation into three blocks: Discovery, Structure, and Execution.
A. Discovery: make every important resource reachable
Ensure clean, crawlable HTML versions of your key content:
Avoid hiding core content behind interactions that require JS events.
Use server-side rendering or robust hydration for critical pages.
Maintain XML sitemaps that reflect your actual canonical URL set:
Include only indexable, canonical URLs.
Segment sitemaps by content type (products, categories, guides, etc.).
Fix robots.txt and meta directives:
Avoid blocking resources (JS, CSS, images) essential for rendering and understanding.
Remove accidental noindex or nofollow on important pages.
B. Structure: speak the language of retrieval systems
Use consistent URL patterns that reflect your ontology and taxonomy:
/topic/ → pillar; /topic/subtopic/ → cluster; use predictable, human-readable slugs.
Implement semantic HTML:
<main>, <article>, <section>, <header>… to define meaningful content regions.
Proper <h1>–<h3> hierarchies that align with entity/intent structure.
Apply schema.org structured data:
Core types: Organization, Product, Service, Article, FAQPage, HowTo, BreadcrumbList, etc.
Use sameAs to connect your brand to official profiles and key knowledge graph nodes.
C. Execution: make the site usable for agents and tools
Monitor crawl stats and logs:
Identify unreachable areas, infinite spaces (facets without guards), and crawling traps.
Optimise performance and reliability:
Fast TTFB and stable uptime matter when agents fetch and evaluate your pages during generation.
Prepare for tool calling and APIs:
If you have transactional or data capabilities (search, configurators, pricing), expose them via documented APIs (openapi.json) that an agent can learn from.
Keep these APIs stable and versioned; unstable tools quickly lose trust in agent ecosystems.
This foundation benefits both classic SEO and AI-driven retrieval across any model or platform.
Read the next chapter > Content and AI Search

Article by
Gianluca Fiorelli
With almost 20 years of experience in web marketing, Gianluca Fiorelli is a Strategic and International SEO Consultant who helps businesses improve their visibility and performance on organic search. Gianluca collaborated with clients from various industries and regions, such as Glassdoor, Idealista, Rastreator.com, Outsystems, Chess.com, SIXT Ride, Vegetables by Bayer, Visit California, Gamepix, James Edition and many others.
A very active member of the SEO community, Gianluca daily shares his insights and best practices on SEO, content, Search marketing strategy and the evolution of Search on social media channels such as X, Bluesky and LinkedIn and through the blog on his website: IloveSEO.net.



