
This article is part of the Comprehensive Guide to Generative AI. Each chapter builds on the last to explain how modern AI retrieves, reasons over, and acts on information.
After looking at how AI agents reason, plan and act, this chapter explains how LLMs access external knowledge through neural search and retrieval architectures.
The Library: Neural Search and Retrieval Architectures
The final pillar of the taxonomy addresses the critical challenge of Memory.
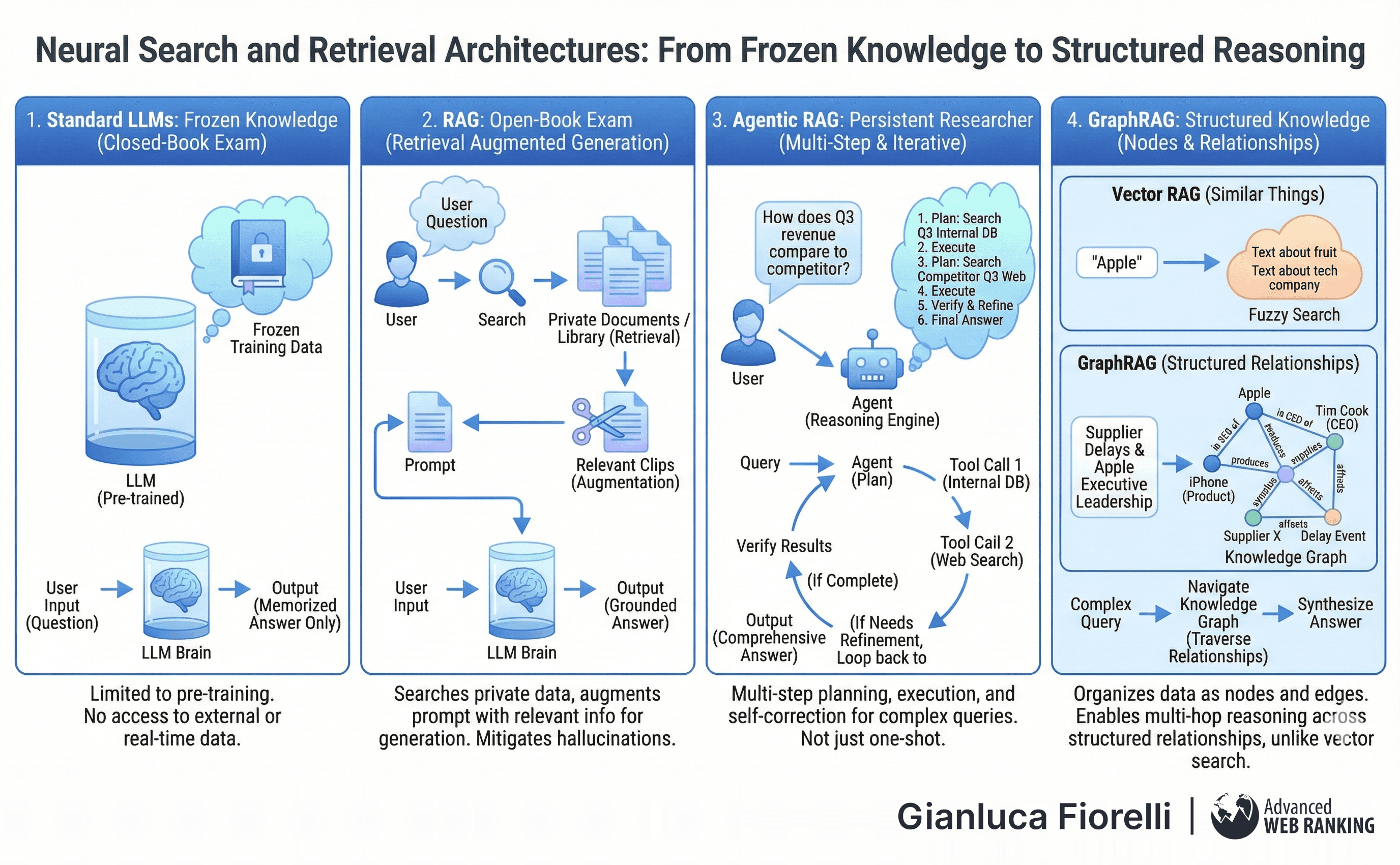
LLMs have frozen training data; to be useful in an enterprise, they must access private, real-time data. This is the domain of Retrieval Augmented Generation (RAG) and Neural Search.
Retrieval Augmented Generation (RAG)
Alternative Nomenclature: Vector RAG, Naive RAG.
The Conceptual Framework:
Standard LLMs are like taking a closed-book exam; the model can only rely on what it memorised during pre-training.
RAG transforms this into an open-book exam. When a user asks a question, the system first searches a library of private documents (Retrieval), finds the relevant pages, clips them to the user's prompt (Augmentation), and then instructs the model to answer using only that information (Generation).
Inside the “Black Box”:
The RAG pipeline consists of three stages:
Ingestion: Documents are sliced into chunks and converted into embeddings.
Retrieval: The user's query is embedded, and a vector database performs a K-Nearest Neighbour (KNN) search to find the most semantically similar chunks.
Generation: The retrieved chunks are injected into the LLM's context window.This architecture is the industry standard for mitigating hallucinations, as it grounds the model in verifiable facts. It is generally cheaper and more flexible than fine-tuning for knowledge injection.
Agentic RAG
Alternative Nomenclature: Agentic Search, Autonomous Retrieval.
The Conceptual Framework:
Standard RAG is a "one-shot" tool: one query, one search, one answer. If the search fails, the system fails. Agentic RAG acts like a persistent researcher. If asked, "How does our Q3 revenue compare to our competitor's?", it recognises the need for a multi-step strategy. It might first search internal databases for "Q3 revenue," then use a web search tool for "Competitor Q3 revenue."
If the initial search yields vague results, it rewrites the query and tries again. It plans, executes, and verifies.
Inside the “Black Box”:
Agentic RAG inserts an LLM "reasoning engine" at the start of the pipeline.
This agent can perform Multi-hop Retrieval (finding document A, which links to document B) and Self-Correction (evaluating if the retrieved data actually answers the question).
While it introduces higher latency due to the reasoning loops, it provides significantly higher accuracy for complex, ambiguous queries.
GraphRAG
Alternative Nomenclature: Knowledge Graph RAG, Structured Retrieval.
The Conceptual Framework:
Vector RAG finds similar things.
If you search for "Apple," it finds text about apples. However, it struggles with structural relationships.
GraphRAG organises data into a network of nodes and edges (a Knowledge Graph). It explicitly maps that "Tim Cook" is the CEO of "Apple," which produces the "iPhone."
If a user asks, "How do supplier delays affect Apple's executive leadership?", Vector RAG might fail because the answer requires traversing a chain of relationships across multiple documents. GraphRAG navigates this web to synthesise an answer.
Inside the “Black Box”:
GraphRAG excels at "Global Summarisation" questions (e.g., "What are the main themes in this dataset?"), which stump vector search.
It uses community detection algorithms to cluster related nodes and generates summaries at different levels of abstraction.
While vectors are about Recall, graphs are about Reasoning. The most powerful systems today are Hybrid, utilising vectors for fuzzy search and graphs for structured navigation.
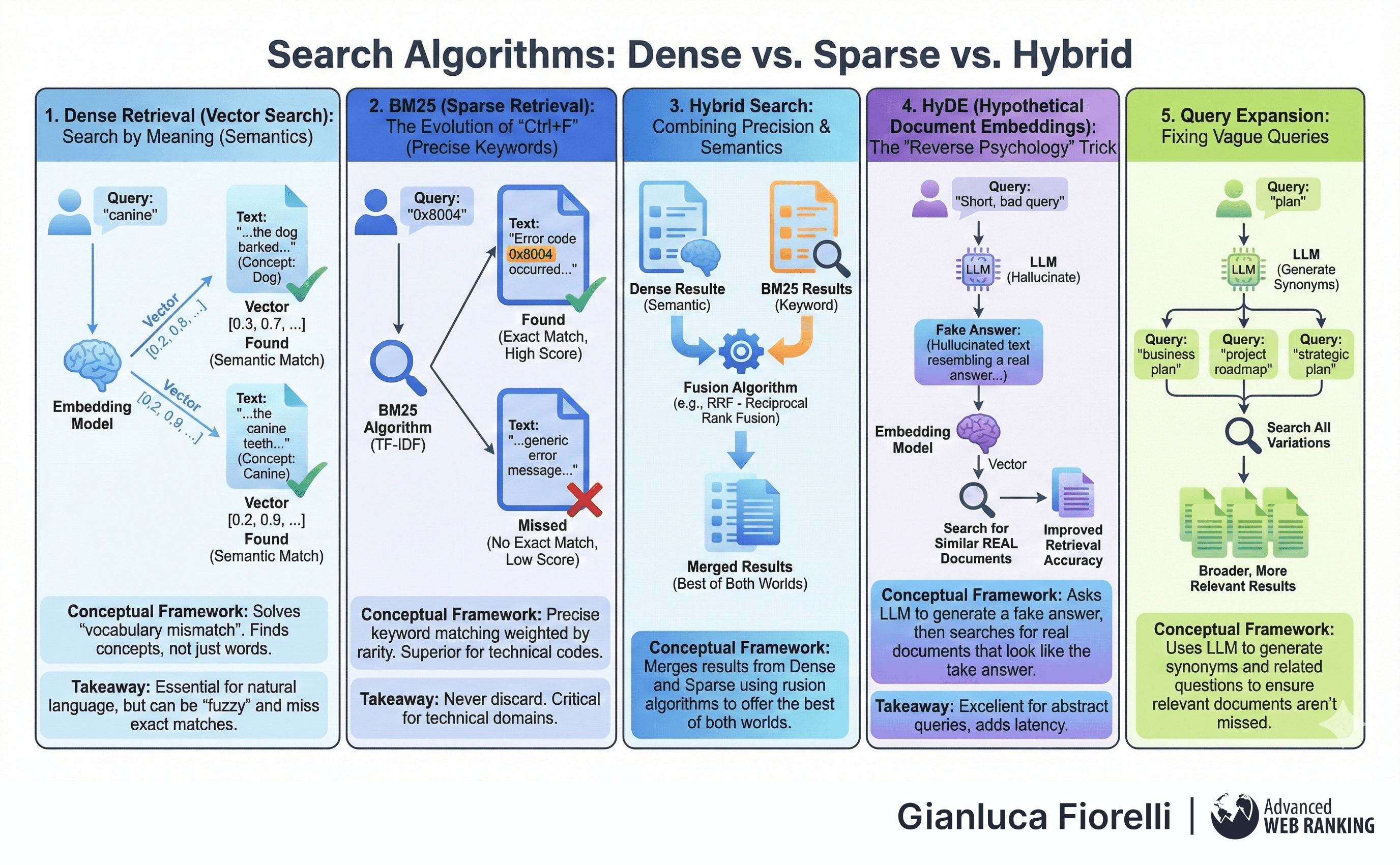
Search Algorithms: Dense vs. Sparse vs. Hybrid
To implement RAG, one must choose a search algorithm. This choice dictates what information is found and what is missed.
Dense Retrieval (Vector Search)
Conceptual Framework:
This is search by meaning (semantics).
A keyword search for "canine" misses documents containing "dog." Dense retrieval, using embeddings, finds the concept of "dog" even if the word "canine" is never used.
It solves the "vocabulary mismatch" problem.
Takeaway: Essential for natural language queries, but can be "fuzzy" and miss exact matches like part numbers.
BM25 (Sparse Retrieval)
Conceptual Framework:
This is the evolution of "Ctrl+F."
It looks for precise keyword matches, weighting them by rarity (TF-IDF).
If you search for the specific error code "0x8004," BM25 is far superior to vector search, which might just return generic "error" documents.
Takeaway: Never discard BM25. It is critical for technical domains.
Hybrid Search
Conceptual Framework:
Hybrid search combines the precision of BM25 with the semantic understanding of Dense Retrieval.
It uses algorithms like Reciprocal Rank Fusion (RRF) to merge the results, offering the best of both worlds.
HyDE (Hypothetical Document Embeddings)
Conceptual Framework:
HyDE is a clever "reverse psychology" trick.
Users often write short, bad queries.
Instead of searching for the query, HyDE:
Asks an LLM to hallucinate a fake answer to that query.
It then searches for real documents that look like the fake answer.
Because a "fake answer" structurally resembles a "real answer" more than a "question" does, retrieval accuracy often improves dramatically.
Takeaway: Excellent for abstract queries, though it adds latency.
Query Expansion
Conceptual Framework:
To fix vague user queries, the system uses an LLM to generate synonyms and related questions.
A query for "plan" is expanded into "business plan," "project roadmap," and "strategic plan."
Searching for all variations ensures that relevant documents aren't missed just because the user guessed the wrong keyword.
Read the next chapter > The Strategy: SEO for AI Search

Article by
Gianluca Fiorelli
With almost 20 years of experience in web marketing, Gianluca Fiorelli is a Strategic and International SEO Consultant who helps businesses improve their visibility and performance on organic search. Gianluca collaborated with clients from various industries and regions, such as Glassdoor, Idealista, Rastreator.com, Outsystems, Chess.com, SIXT Ride, Vegetables by Bayer, Visit California, Gamepix, James Edition and many others.
A very active member of the SEO community, Gianluca daily shares his insights and best practices on SEO, content, Search marketing strategy and the evolution of Search on social media channels such as X, Bluesky and LinkedIn and through the blog on his website: IloveSEO.net.




