
This article is part of the Comprehensive Guide to Generative AI. Each chapter builds on the last to explain how modern AI retrieves, reasons over, and acts on information.
In this first chapter, I'll explain the inner mechanics of Large Language Models, and clarify how they process context and generate reasoning.
The Model: Architecture and Mechanics of the Large Language Model
The Large Language Model (LLM) represents the engine of the modern AI revolution. To understand its capabilities and limitations, one must first understand the granular mechanics of its operation, from the atomic units of text it processes to the high-dimensional spaces where it stores meaning.
The Large Language Model (LLM)
Alternative Nomenclature: Foundation Model, Generative Pre-trained Transformer (GPT), Neural Language Model.
The Conceptual Framework:
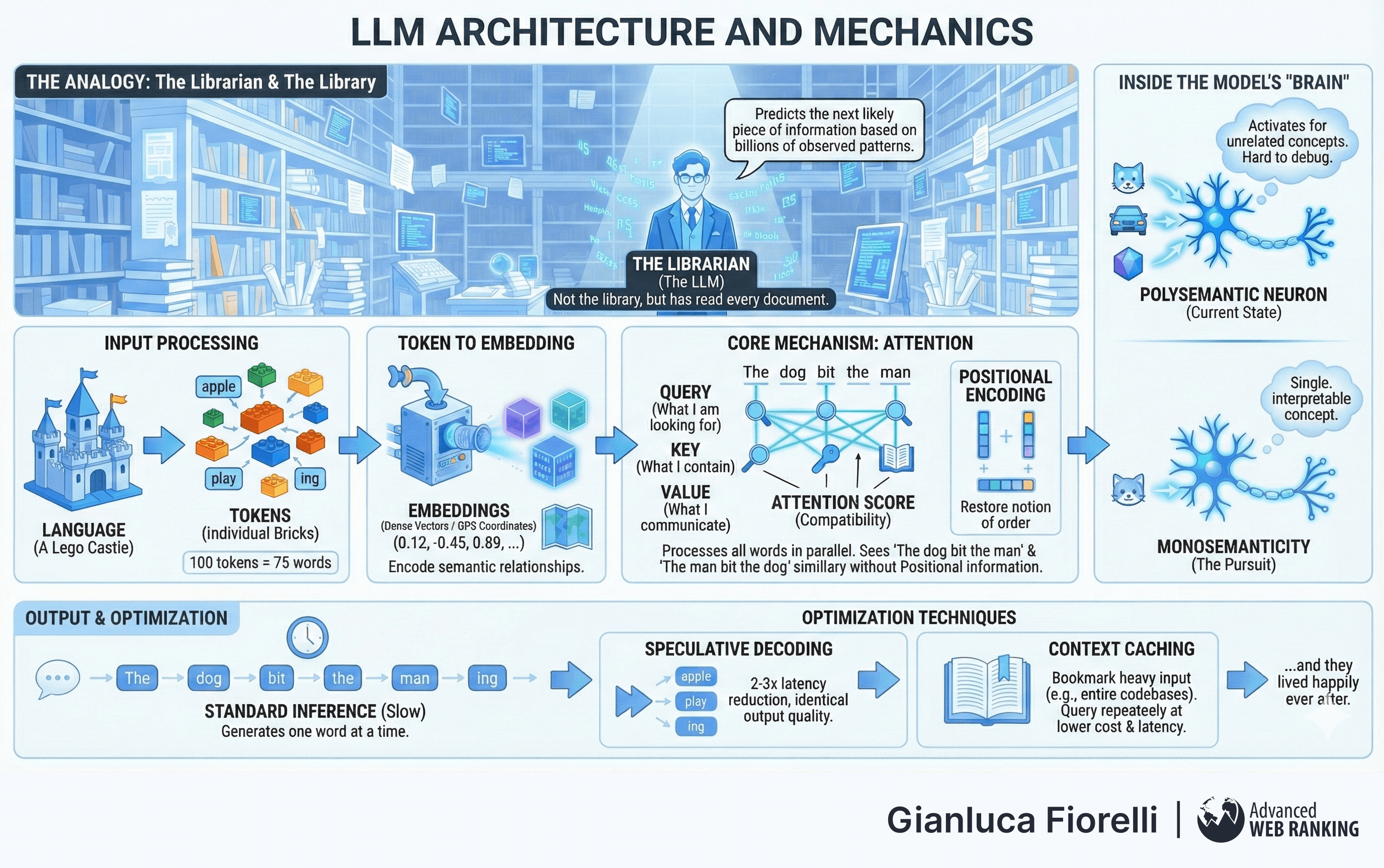
Imagine a library that houses a copy of nearly every book, article, conversation, and code snippet ever written. An LLM is not the library itself; rather, it is a librarian who has read every document in that collection.
This librarian possesses a distinct form of intelligence: they have read so much that they can predict, with startling accuracy, exactly how a sentence should end, how a Python script should conclude, or how a Socratic dialogue should proceed.
However, this librarian does not "know" facts in the human, experiential sense. Instead, they are a statistical engine, a probabilistic machine that predicts the next most likely piece of information based on the billions of patterns observed during training.
Inside the "Black Box":
Technically, an LLM is a deep neural network based on the Transformer architecture, trained on massive datasets to minimise the perplexity of predicting the next token in a sequence.
The designation "Large" refers to the parameter count; the billions of adjustable weights or connections within the model's "brain", which generally correlates with the model's reasoning capacity and ability to generalize across domains.
For instance, a model like Llama 3, with 70 billion parameters, requires significant computational resources (such as high-end GPUs) just to run, a testament to the sheer scale of calculation required to generate even a single word.
The training process involves two distinct phases:
Pre-training, the "university education" where the model learns broad patterns, grammar, and world knowledge from vast, unsupervised datasets. This phase consumes millions of dollars in compute and months.
Fine-Tuning, akin to "job training," where the pre-trained model is specialised for specific tasks, such as following instructions or writing code, aka using smaller, curated datasets.
It is crucial to understand that the LLM is not a database of facts but a “reasoning” engine; its primary utility in enterprise contexts lies not in recalling training data (which may be outdated or hallucinatory) but in processing and synthesising new context provided at runtime.
Tokenisation and the Atomic Unit of Meaning
Alternative Nomenclature: Sub-word Units, Input IDs, Vocabulary Elements.
The Conceptual Framework:
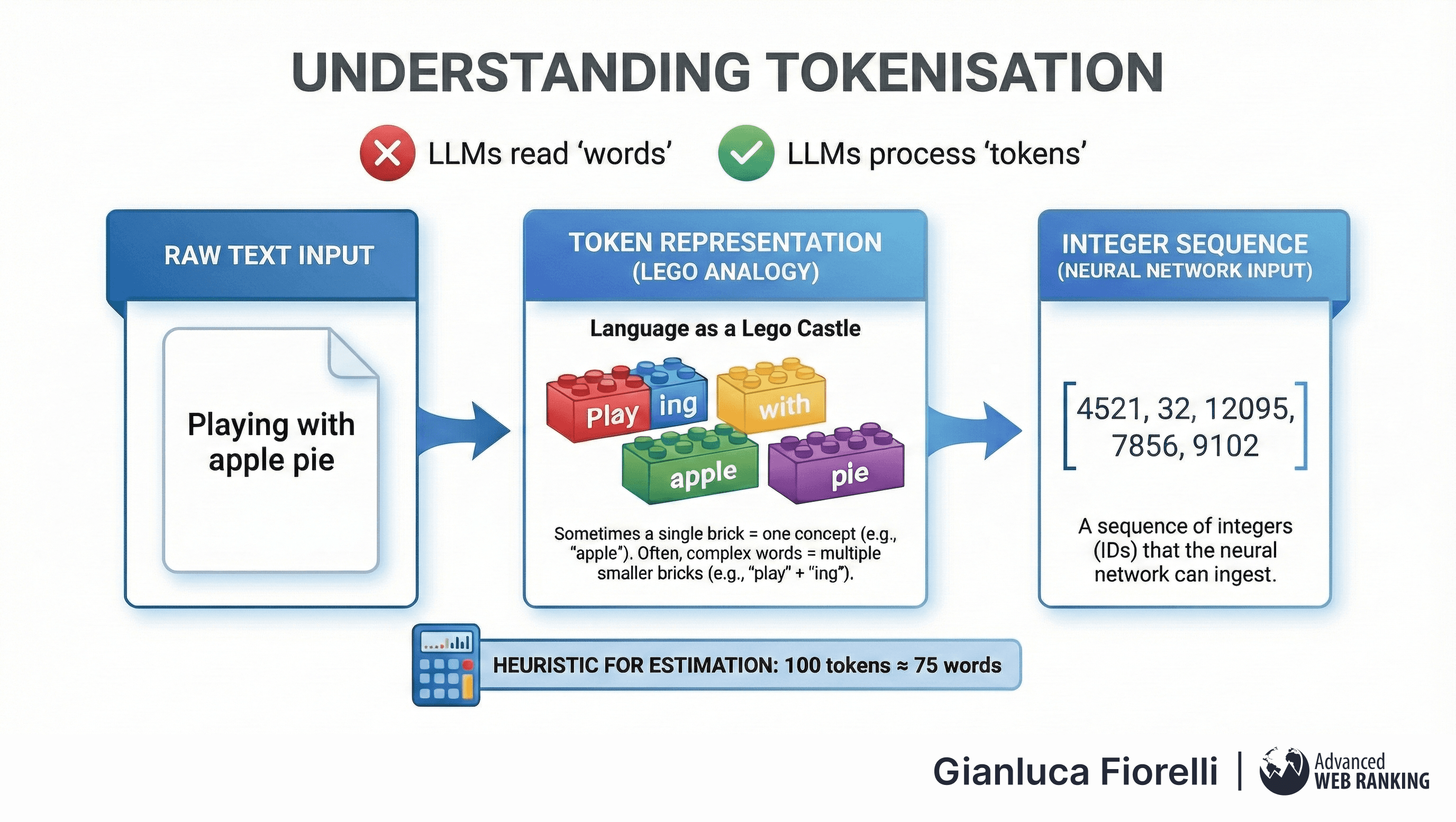
A pervasive misconception is that LLMs read "words."
In reality, they process "tokens."
If language were a Lego castle, tokens would be the individual bricks.
Sometimes a single brick represents a whole concept (like the word "apple"), but often, complex words are constructed from multiple smaller bricks (like "play" and "ing"). A useful heuristic for estimation is that 100 tokens equate to approximately 75 words.
Inside the “Black Box”:
Tokenisation is the discrete process of converting raw text strings into a sequence of integers (IDs) that the neural network can ingest. The choice of tokeniser - the algorithm that determines how text is chopped up - has profound implications for model performance and cost:
Efficiency and Cost: Because LLM providers typically charge by the token, the efficiency of the tokeniser determines the economic viability of a prompt. A more efficient tokeniser packs more semantic meaning into fewer tokens, effectively increasing the "context window" (the amount of text the model can see).
Artefacts and Blind Spots: The disconnect between human visual reading and machine token processing leads to "tokenisation artefacts." For example, an LLM might struggle to reverse the word "Lollipop" or count its letters accurately because it perceives "Lollipop" as a single token ID, rather than a sequence of eight letters. It sees the concept, not the spelling.
Implications for Development:
Understanding tokenisation is critical for managing the Context Window, the maximum number of tokens a model can process at once.
This window acts as the model's "short-term memory."
Just as a desk has limited space for open books, a model has a limited capacity for tokens. Exceeding this limit forces the truncation of input, leading to a loss of context and coherence.
Embeddings: The Geometry of Language
Alternative Nomenclature: Vector Representations, Semantic Vectors, Dense Vectors.
The Conceptual Framework:
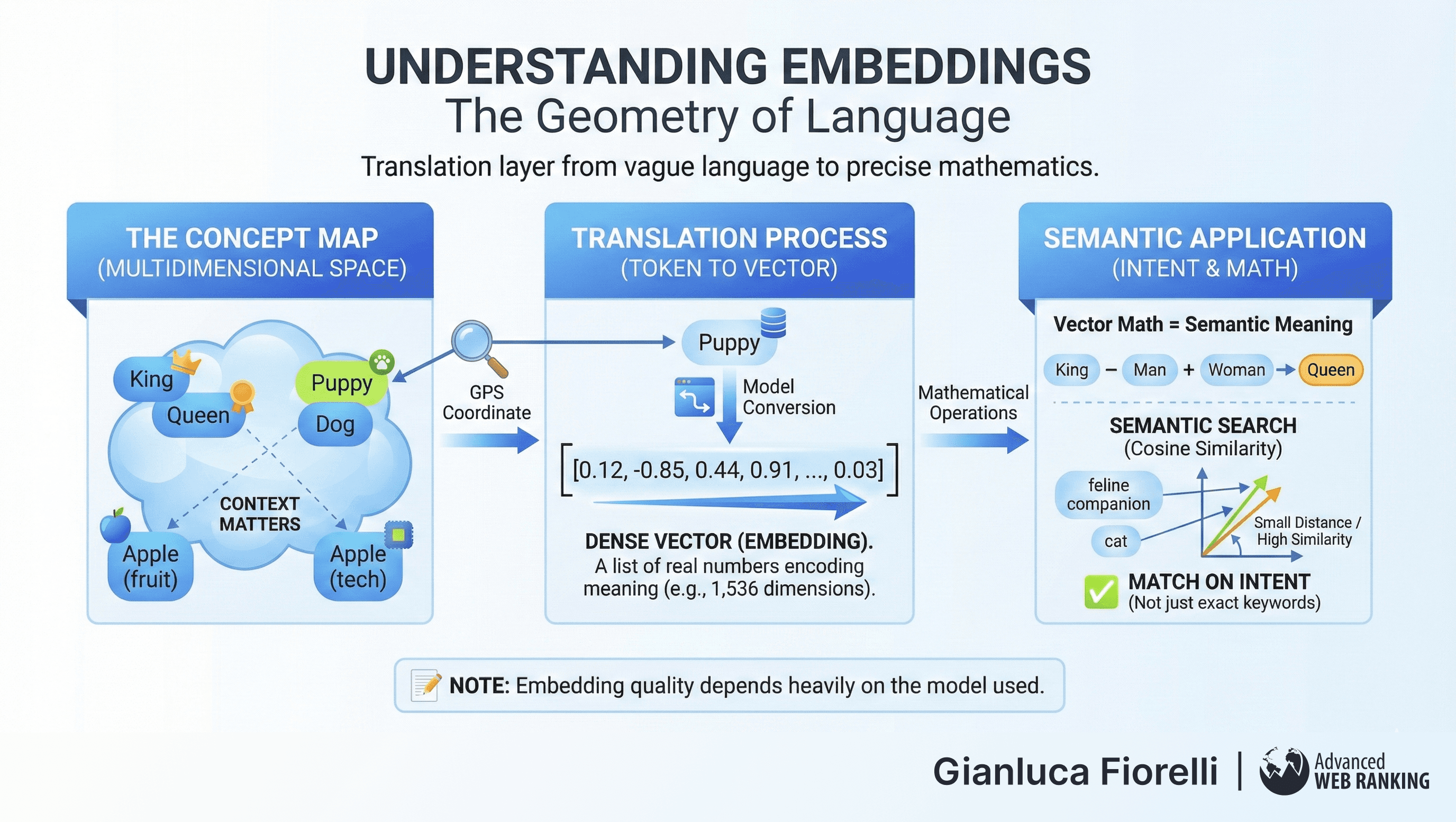
Embeddings are the translation layer between vague human language and precise mathematical calculation.
Imagine a massive, multidimensional map of all human concepts. On this map, concepts with similar meanings are located geographically close to one another. "King" stands next to "Queen," "Puppy" plays near "Dog," and "Apple" (the fruit) is far away from "Apple" (the tech company), depending on the context.
An embedding is simply the GPS coordinates (a list of numbers) for a specific piece of text on this map.
Inside the “Black Box”:
When a model processes text, it converts tokens into embeddings—dense vectors of real numbers (e.g., arrays of 1,536 or 3,072 dimensions). These vectors encode semantic relationships such that mathematical operations on the vectors correspond to semantic operations on the concepts. The classic example of vector arithmetic is:
This algebraic consistency allows systems to measure the "distance" between two sentences (using metrics like Cosine Similarity) to determine if they are talking about the same topic, even if they use completely different words.
Operational Relevance:
Embeddings are the backbone of modern search (Dense Retrieval).
Unlike keyword search, which matches exact strings, embedding-based search matches intent.
A query for "feline companion" will map to a vector close to "cat," allowing the system to retrieve relevant results without a single shared word.
However, the quality of these embeddings depends heavily on the model used; general-purpose embeddings may fail to capture the nuance of specialised domains like law or medicine, necessitating domain-specific tuning.
The Attention Mechanism
Alternative Nomenclature: Self-Attention, Multi-Head Attention.
The Conceptual Framework:
The true breakthrough of the Transformer architecture is the Attention Mechanism.
To understand it, visualise a noisy cocktail party where dozens of conversations are happening simultaneously. To make sense of one conversation, you must dynamically "tune out" the background noise and focus intensely on specific words to understand the context. If you hear the sentence, "The bank of the river was flooded," your brain pays "attention" to the word "river" to clarify that "bank" refers to land, not a financial institution.
Inside the “Black Box”:
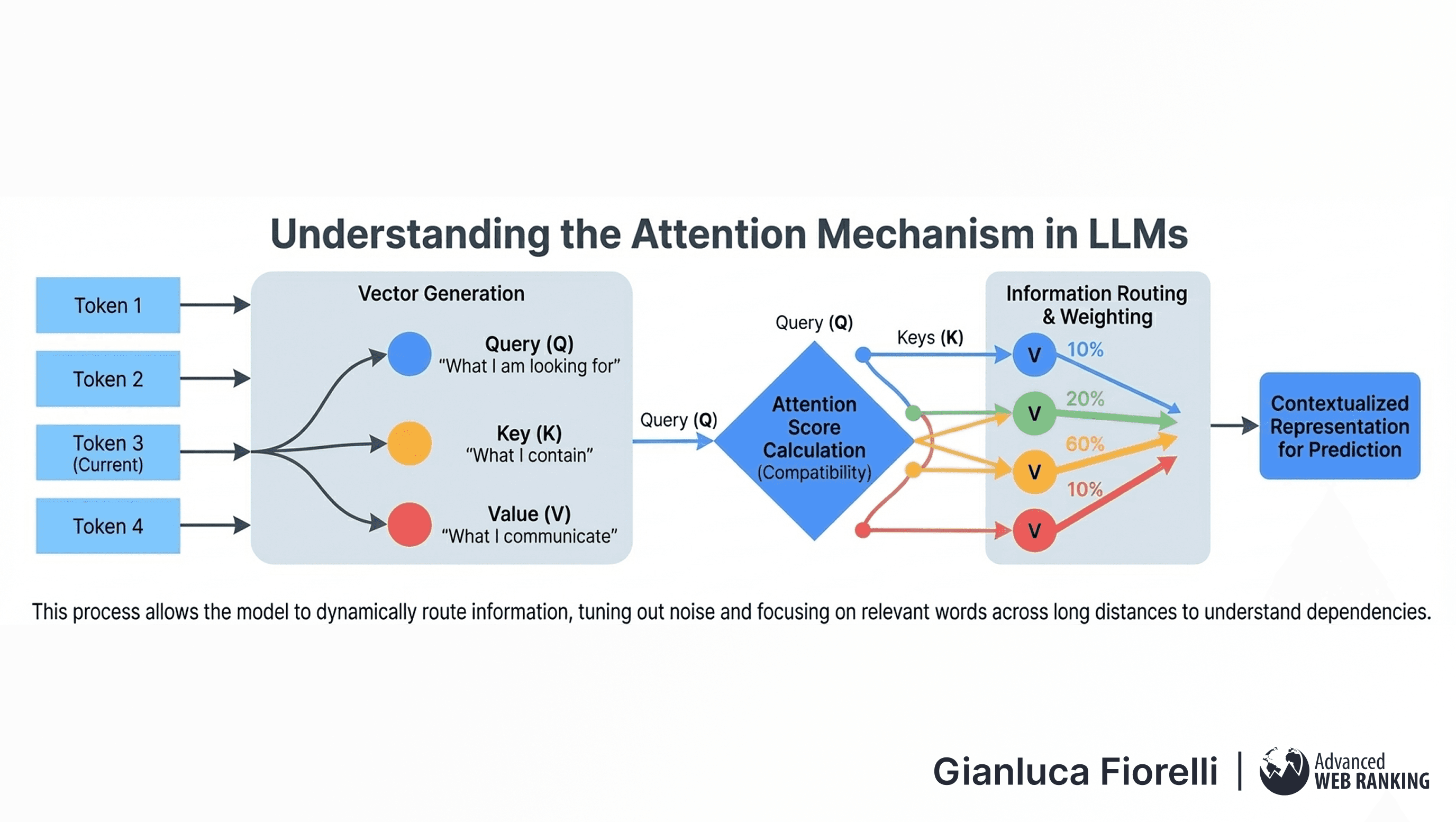
In an LLM, Attention allows every token in a sequence to "look at" every other token to gather context before generating a prediction. For each token, the model generates three vectors: a Query (what I am looking for), a Key (what I contain), and a Value (what I communicate).
The model calculates a compatibility score (Attention Score) between the Query of the current token and the Keys of all other tokens. This score determines how much "Attention" to pay to each word.
This process allows the model to route information dynamically across long distances in the text, understanding dependencies that might be separated by thousands of words.
Systemic Impact:
Attention is powerful but computationally expensive. The complexity of this operation is quadratic (O(n^2)), meaning that doubling the length of the input text quadruples the computational work required.
This is the primary bottleneck preventing infinite context windows and serves as the fundamental constraint designers must navigate when building RAG systems.
Positional Encoding
Alternative Nomenclature: Rotary Embeddings (RoPE), Relative Position Representations.
The Conceptual Framework:
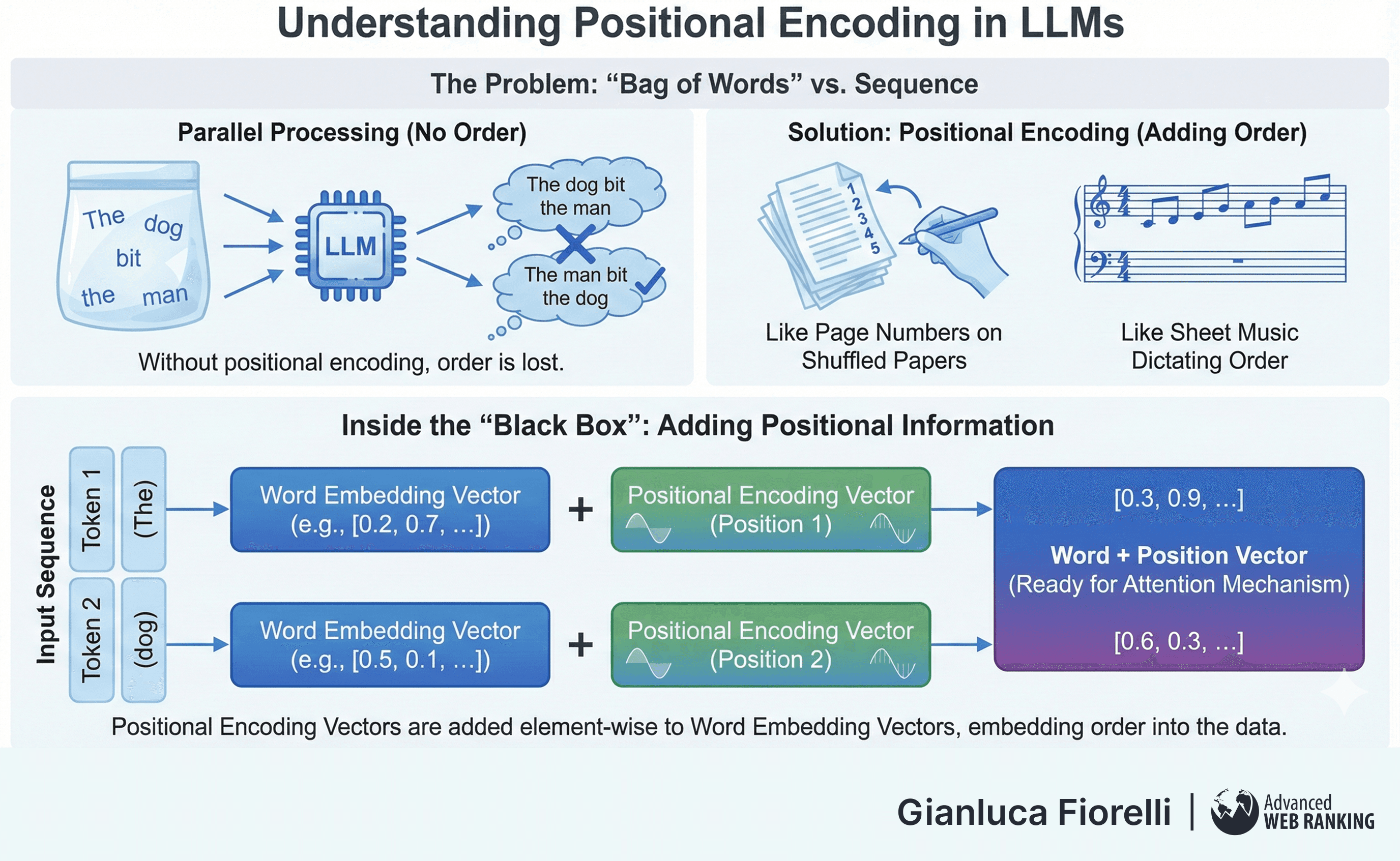
One peculiarity of the Attention mechanism is that it processes all words in parallel, viewing the sentence as a "bag of words" rather than a sequence.
Without intervention, the model would see no difference between "The dog bit the man" and "The man bit the dog."
Positional Encoding is the solution because it is akin to adding page numbers or timestamps to a shuffled stack of papers or providing a musician with sheet music that dictates the order of notes, not just which notes to play.
Inside the “Black Box”:
To restore the notion of order, vectors containing positional information are added to the word embeddings. Early models used fixed sinusoidal functions (sine and cosine waves of different frequencies) to create unique signatures for each position.
Modern LLMs utilise more advanced techniques like Rotary Positional Embeddings (RoPE), which encode position by rotating the vector in geometric space.
This allows the model to understand relative distances as, for instance, knowing that "King" and "Queen" are related not just by meaning, but by their proximity in the text structure.
This mechanism is what enables the parallelisation of training (unlike older RNNs) while retaining the sequential nature of language.
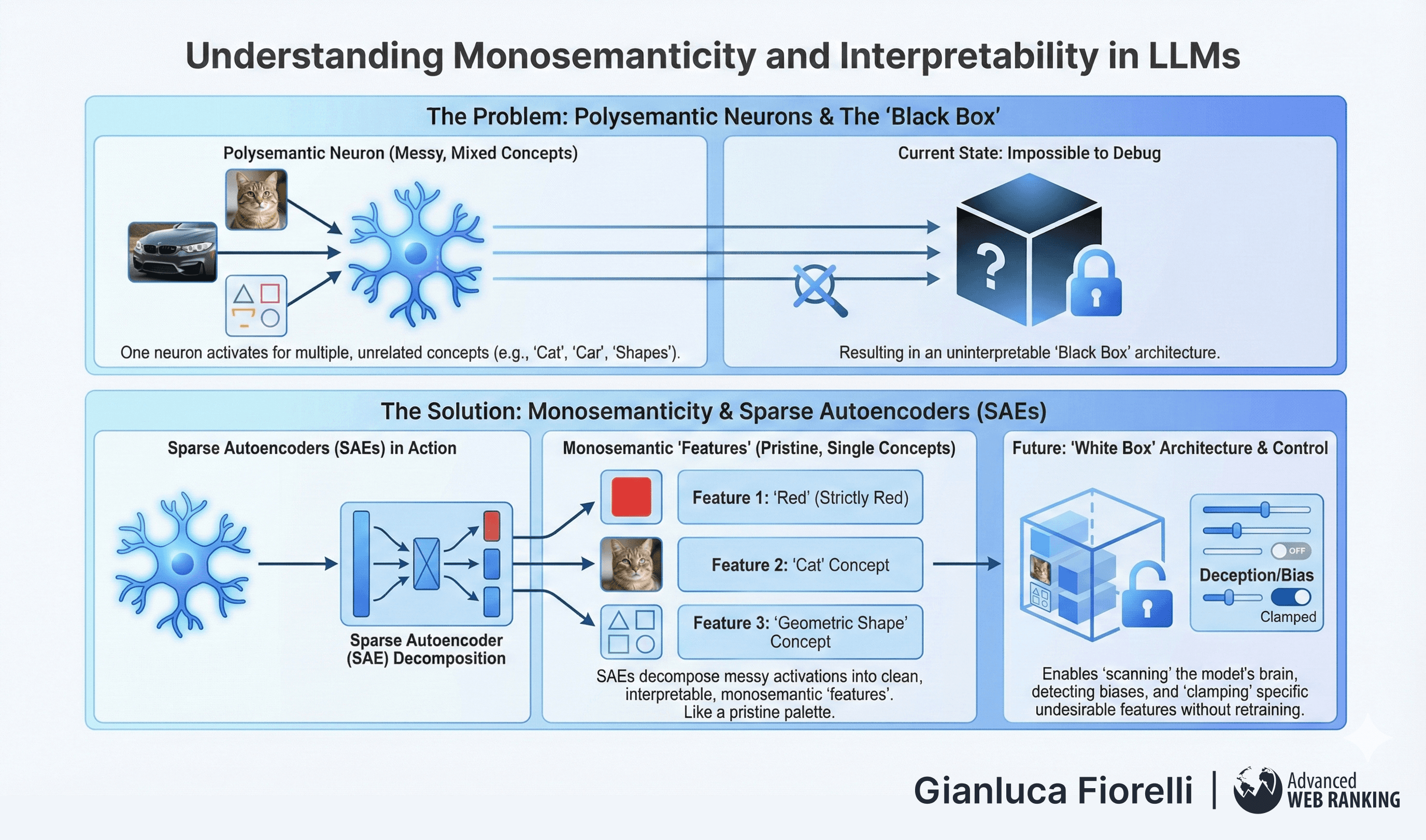
Monosemanticity and Interpretability
Alternative Nomenclature: Sparse Autoencoder Features, Dictionary Learning.
The Conceptual Framework:
For years, neural networks have been "black boxes."
A single neuron in an LLM is typically "polysemantic," meaning it activates for unrelated concepts; perhaps firing for images of cats, the front of cars, and geometric shapes simultaneously.
This makes debugging the "mind" of the model impossible.
Monosemanticity is the pursuit of a "white box" architecture where every component represents a single, interpretable concept. It is the difference between painting with muddy, mixed colours and having a pristine palette where "Red" is strictly "Red".
Inside the “Black Box”:
Researchers at labs like Anthropic use techniques called Sparse Autoencoders (SAEs) to decompose the messy, polysemantic activations of neurons into clean, monosemantic "features."
By training a dictionary of features that is larger than the number of neurons, they can disentangle these concepts. They have identified specific features that activate only for concepts like "The Golden Gate Bridge," "Base64 code," or "Deception".
This breakthrough suggests a future where we can "scan" a model's brain to see if it is being deceptive or biased, and potentially "clamp" (turn off) specific undesirable features without retraining the entire model.
It transforms AI safety from behavioural testing to mechanistic auditing.
Speculative Decoding
Alternative Nomenclature: Draft-Target Decoding, Speculative Sampling.
The Conceptual Framework:
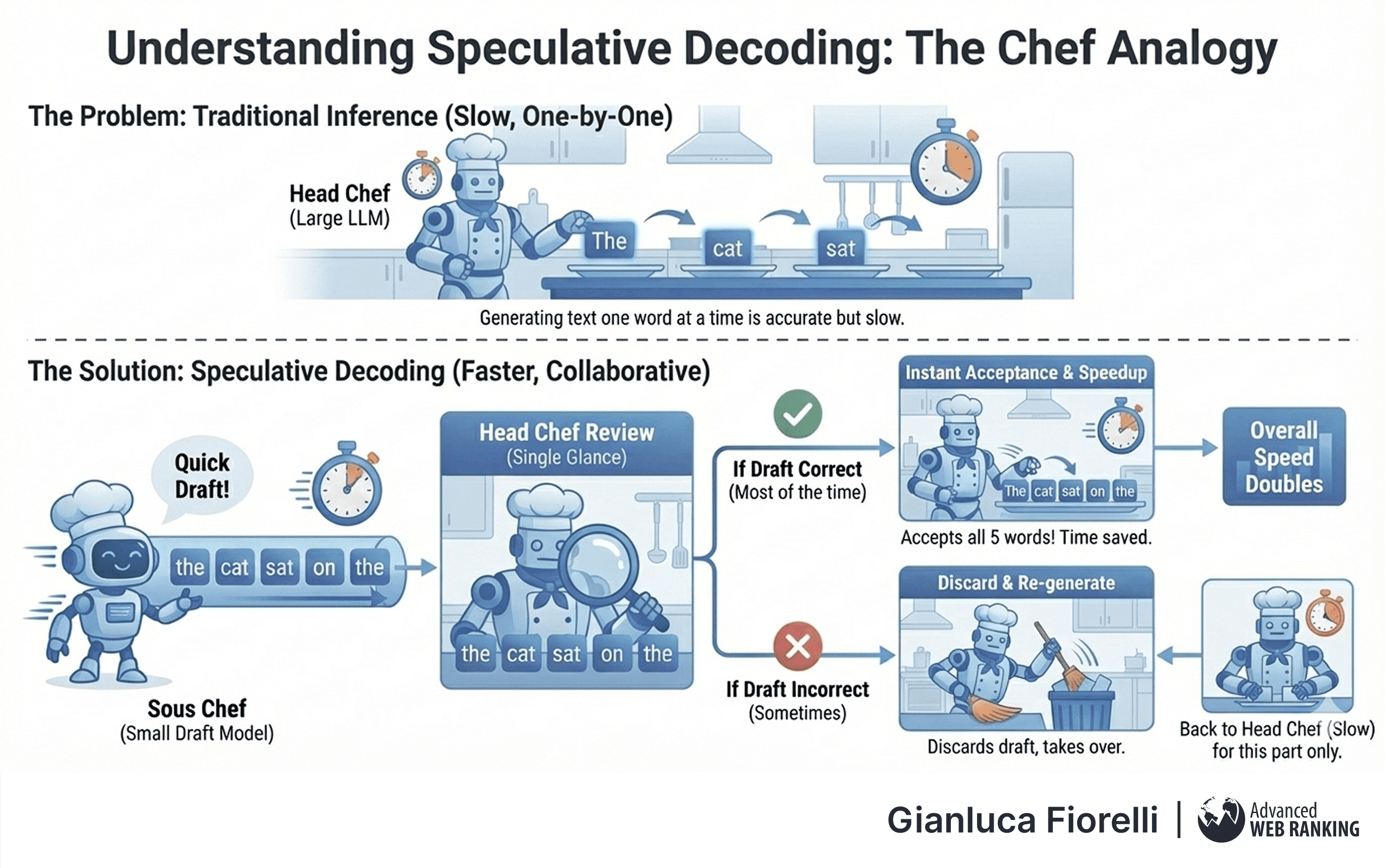
Inference (the process of generating text) is often slow because LLMs must generate one word at a time.
Speculative Decoding is an optimisation technique analogous to a Head Chef working with a Sous Chef.
The Head Chef (the main, large model) is brilliant but slow. The Sous Chef (a smaller, faster draft model) is quick but prone to errors.
In this workflow, the Sous Chef rapidly guesses the next five words of a sentence. The Head Chef then reviews this draft in a single glance.
If the words are correct (e.g., "the," "cat," "sat," "on"), the Head Chef accepts them instantly, saving the time of generating them from scratch.
If the Sous Chef errs, the Head Chef discards the draft and takes over. Because the Sous Chef is right most of the time for simple phrasing, the overall speed of the kitchen doubles.
Inside the “Black Box”:
This technique exploits the memory bandwidth bottleneck of GPUs.
Loading the massive weights of the Head Chef model takes time; once loaded, processing 5 tokens in parallel takes roughly the same time as processing 1. Therefore, verifying the draft tokens is computationally "free" compared to generating them sequentially.
If the probability distribution of the draft model aligns with the target model, the tokens are accepted.
This results in 2-3x latency reduction with mathematically identical output quality to the large model.
Context Caching
Alternative Nomenclature: KV Caching, Prefix Caching.
The Conceptual Framework:
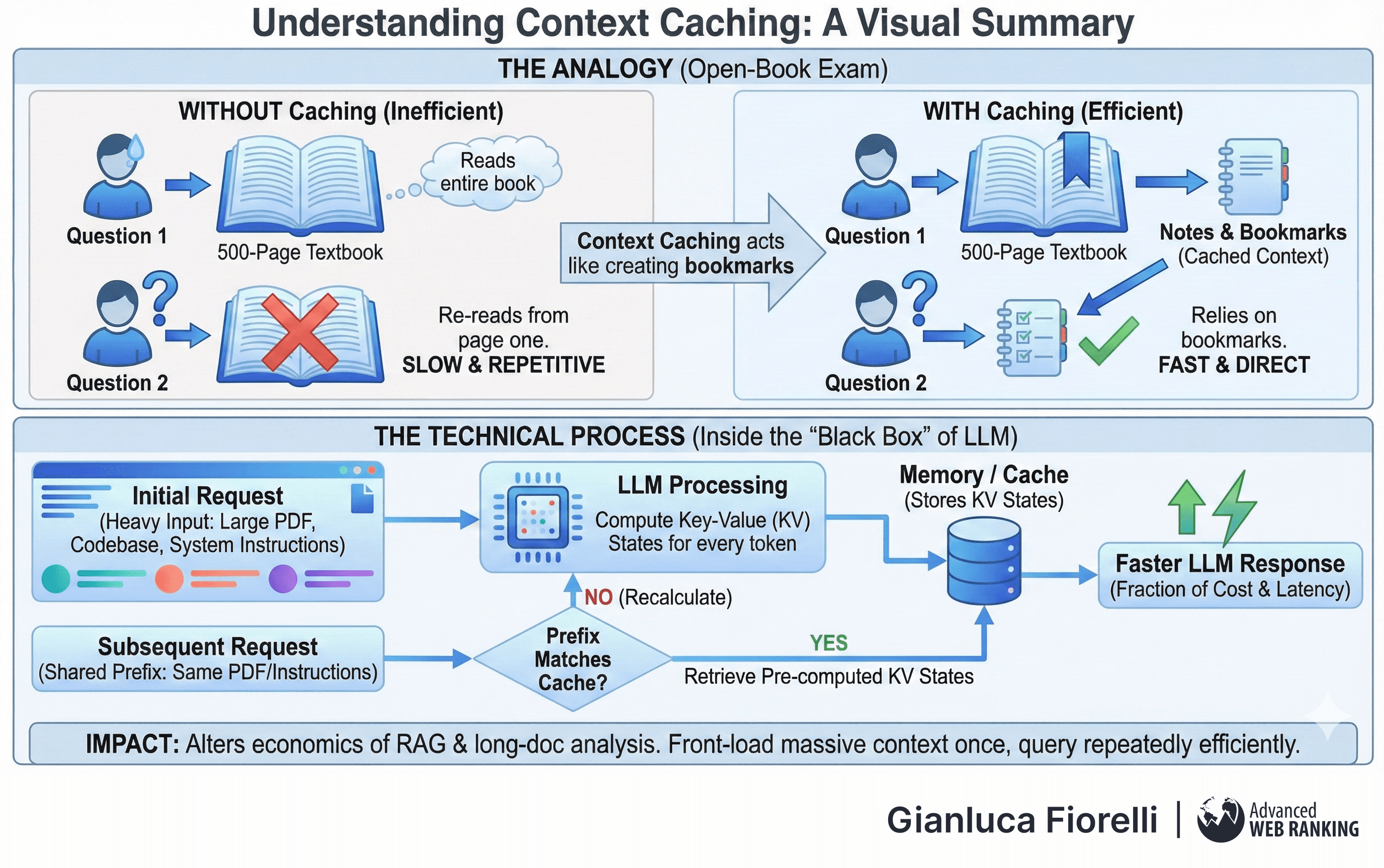
Imagine a student taking an open-book exam where the textbook is 500 pages long.
For the first question, they must read the entire book.
For the second question, however, it would be inefficient to read the book again from page one.
Instead, they rely on the notes and bookmarks they created during the first pass.
Context Caching allows an LLM to "bookmark" the processing of heavy input documents.
Inside the “Black Box”:
When an LLM processes a prompt, it computes Key and Value (KV) states for every token.
Context Caching stores these KV states in memory.
When a subsequent request arrives that shares the same prefix (e.g., the same system instructions or the same uploaded PDF), the model retrieves the pre-computed states rather than recalculating them.
This innovation fundamentally alters the economics of RAG and long-document analysis. It allows developers to front-load massive amounts of context (like entire codebases or legal libraries) into the prompt once and then query that context repeatedly at a fraction of the cost and latency.
Read the next chapter > The Agent: Reasoning, Planning, and Action

Article by
Gianluca Fiorelli
With almost 20 years of experience in web marketing, Gianluca Fiorelli is a Strategic and International SEO Consultant who helps businesses improve their visibility and performance on organic search. Gianluca collaborated with clients from various industries and regions, such as Glassdoor, Idealista, Rastreator.com, Outsystems, Chess.com, SIXT Ride, Vegetables by Bayer, Visit California, Gamepix, James Edition and many others.
A very active member of the SEO community, Gianluca daily shares his insights and best practices on SEO, content, Search marketing strategy and the evolution of Search on social media channels such as X, Bluesky and LinkedIn and through the blog on his website: IloveSEO.net.




