![Branded SEO Guide 2026 [Strategic Edition]](https://framerusercontent.com/images/KxDuiJ90izP5CJpAVcf0sEHLnto.png?width=1920&height=1080)
Branded SEO Guide 2026 – Strategic Edition
In the past 18 months, Search has undergone a fundamental transformation, and I don't say this as it was an already classic cliché but because it is real.
We've moved from a search environment defined by keyword relevance to one dictated by entity authority and generative synthesis.
Think of it like the difference between playing chess by looking at individual pieces versus understanding the entire board as a unified force field.
Until recently, the thesis that Google and other search engines inherently favor recognized brands was presented as mere observation, perhaps even folklore. But here's what we now know: this thesis remains fundamentally correct in 2026, yet the mechanics have shifted entirely.
The mechanisms through which this "brand bias" is enacted have transitioned from simple behavioral signals - the old "clicks equal love" narrative - to deep semantic architecture.
Let me ask you this: Is your brand merely a name on a SERP, or is it a node within a globally distributed knowledge graph, fully "translated" for both traditional search indices and large language model memory? Because that distinction now matters more than ever before.
In this guide, I evaluate the baseline of brand-centric SEO, update it with the findings of the 2025 core updates and the MUVERA retrieval revolution, and I will provide you with an actionable framework for the next phase of digital visibility.
We're not discussing best practices here. We're discussing the why behind the mechanics.
The Foundation of Brand Bias: Navboost and Behavioral Reliability
The journey toward understanding brand bias begins not with hype, but with evidence. Google prioritizes large brands; and this has evolved from a suspicion into documented technical reality through the revelation of the Navboost system.
Imagine Navboost as the ancient library of Alexandria, but instead of scrolls, it stores 13 months of user behavior. That's not hyperbole but it's literally how it functions.
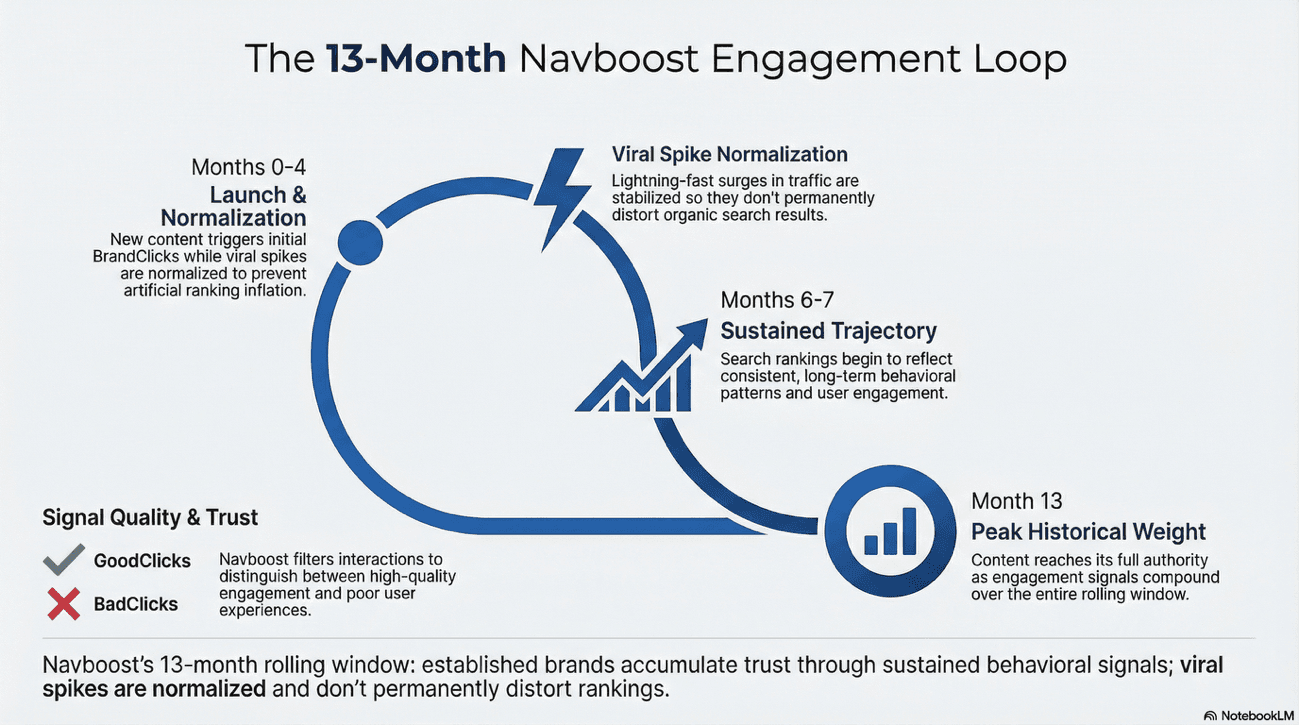
The 13-Month Engagement Loop: Trust Through Time
Navboost is not a real-time reactive system; it's a historical repository of user interaction data. It analyzes how users respond to specific results for a given query and continuously adjusts the information retrieval (IR) scores accordingly.
For brands, this creates a significant barrier to entry for new competitors: established brands benefit from over a year of accumulated "positive" clicks, making their positions in the SERP highly resilient to traditional on-page SEO changes.
Here's the mechanism: the system uses a technique called "squashing" (processed by the internal "Craps" module) to normalize click signals. This prevents sudden viral spikes - example, a viral subreddit post that drives 50,000 clicks in a day - from permanently distorting a domain's ranking unless that behavior is sustained over the full 13-month period.
This is precision engineering, not guesswork.
This technical nuance confirms a theory many of us have held for years: cross-channel brand amplification creates a "virtuous flywheel".
A brand that captures high visibility on YouTube or social platforms generates branded searches. These branded searches, in turn, provide the Navboost system with the high-intent click data necessary to maintain dominant organic positions for unbranded, generic queries.
It's a cycle; not vicious, but virtuous.
Google's Glue system (a companion to Navboost that focuses on deeper satisfaction metrics) further reinforces this behavioral feedback loop by tracking not just whether a user clicked, but how thoroughly they engaged with the content: scroll depth, dwell time, and whether they returned for additional searches on related topics.
Think of Glue as Navboost's quality auditor.
Signal Category | Data Point | Impact on Ranking |
|---|---|---|
Click Interactions | GoodClicks vs. BadClicks | Positive clicks (long dwell time) boost ranking; negative clicks (quick bounce) demote. |
Behavioral Depth | Dwell Time & Scroll Depth | Signals content satisfies user intent; critical for "completing the journey". |
Retrieval Filter | Candidate Culling | Navboost reduces potential results from tens of thousands to a few hundred based on historic satisfaction. |
Contextual Slicing | Device & Locale | Signals are "sliced" by device type and geography to ensure local relevance. |
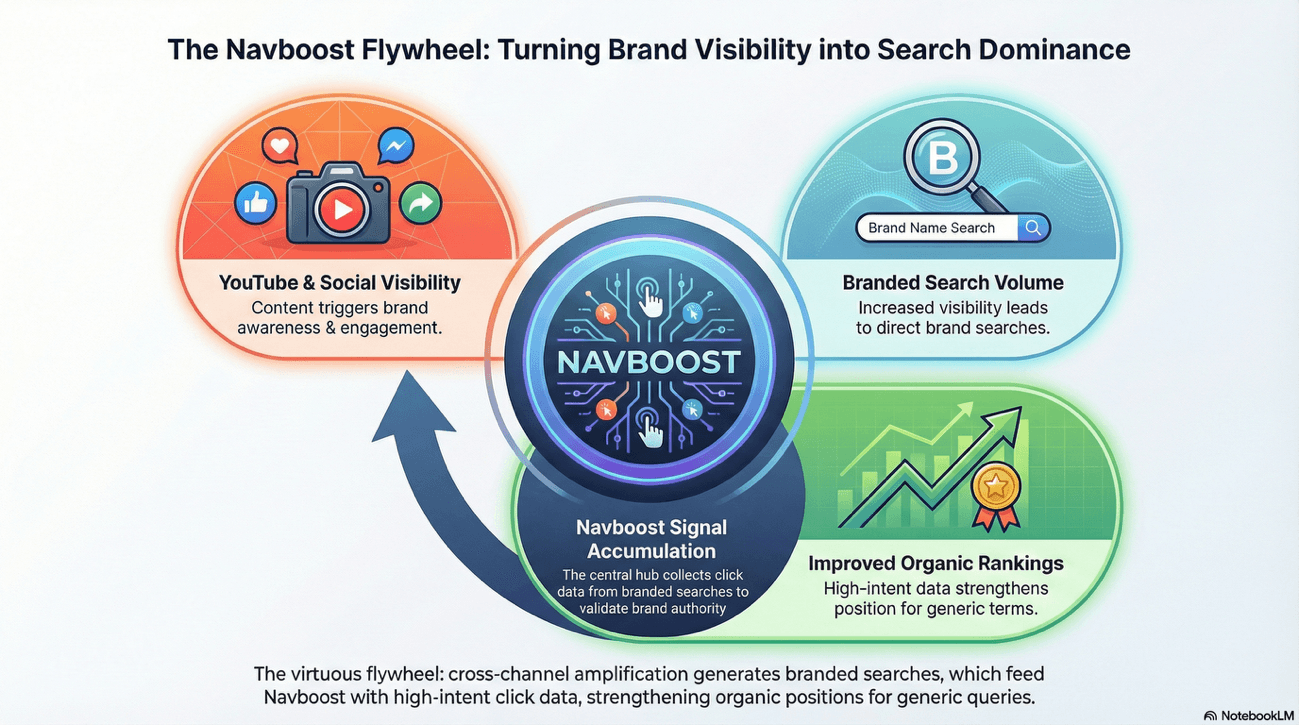
Audit and Satisfy the Branded Flywheel
Trust me: every branded search must lead to a "GoodClick" (long dwell time).
If users search for your brand + a specific problem and land on a generic homepage, they bounce. And when they bounce, they send a negative signal to Navboost. That signal compounds over 13 months.
Leveraging Google Trends as a Discovery Proxy for AI Intent
Here's a question I know you're thinking: "How do I find what AI systems will care about, not just what humans search for?"
Google Trends captures human search behavior, not internal AI retrieval paths. Yet it can serve as the most powerful discovery proxy for brand strategy.
The logic is elegant:
If a specific sub-topic (e.g., "DeepMind Genie 3 specs") is rising in human search interest, it is mathematically more likely to be selected as a "thematic seed" when a Large Language Model generates an internal sub-query expansion (the famous "Query Fan-Out") to answer a broader prompt about your brand.
Think of it like this: The AI looks at human trends first, then asks deeper questions based on what humans are asking. You're reading the breadcrumbs humans leave behind to predict where the AI will dig.
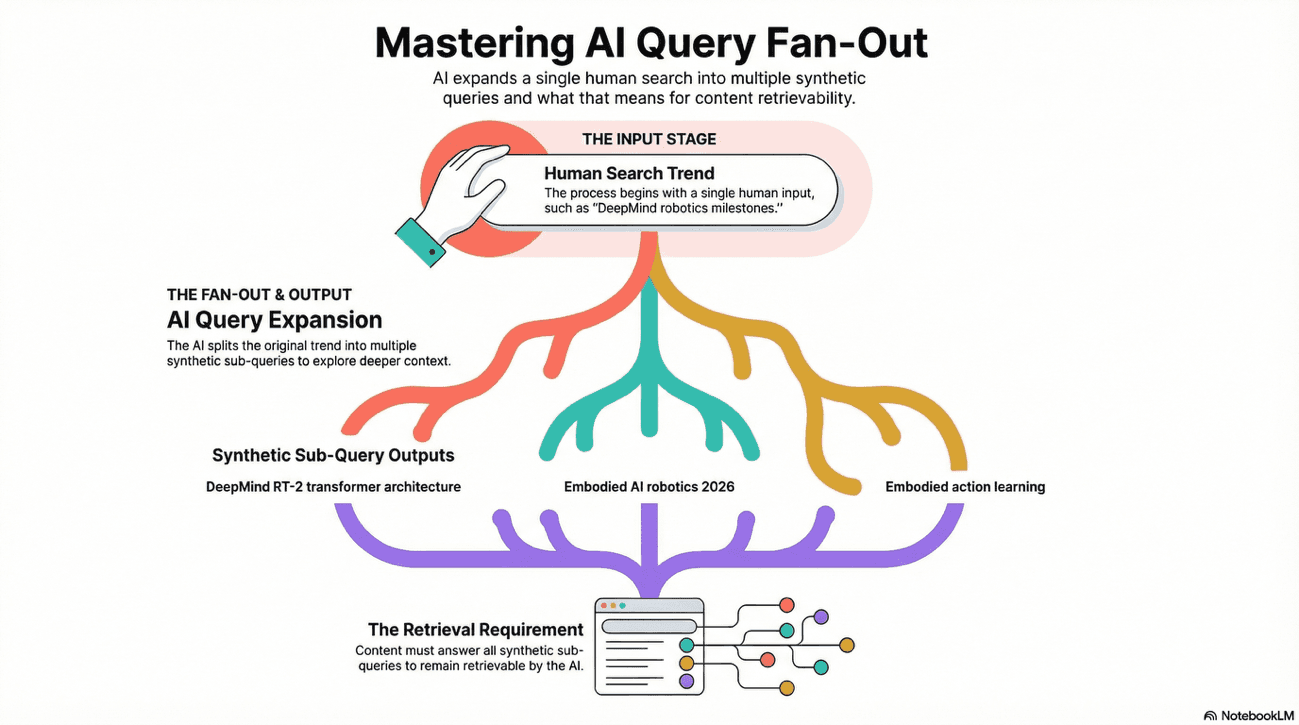
The Workflow: From Human Interest to Synthetic Retrieval
To avoid the manual exhaustion of clicking through the Trends UI, leverage the Google Trends API (Alpha) - officially rolled out in July 2025 - to build an automated "Intent Pipeline."
1. Programmatic Seed Discovery (Trends API)
Use the relatedQueries endpoint to monitor your brand and product names. Unlike the web UI, the API provides consistently scaled search interest across requests, allowing you to compare dozens of terms simultaneously without the 5-term limit.
Action: Filter for "Breakout" queries. These represent new entities or attributes being attached to your brand node in real-time. They're signals of emerging intent.
2. Bridging the Gap with AI Simulation
Once you identify a rising human search (e.g., "DeepMind robotics milestones"), feed that specific query into the Gemini API with google_search grounding enabled.
The Goal: Extract the webSearchQueries array from the metadata. This reveals the Query Fan-Out; the actual synthetic sub-queries Google's AI uses to ground its response (e.g., "Deepmind RT-2 transformer architecture," "Open X-Embodiment dataset impact").
3. Monosemantic Content Gap Analysis
Map the extracted synthetic queries against your current content. If the AI is fanning out into questions you haven't answered in a monosemantic block (75–225 words), you are effectively invisible to that specific retrieval path.
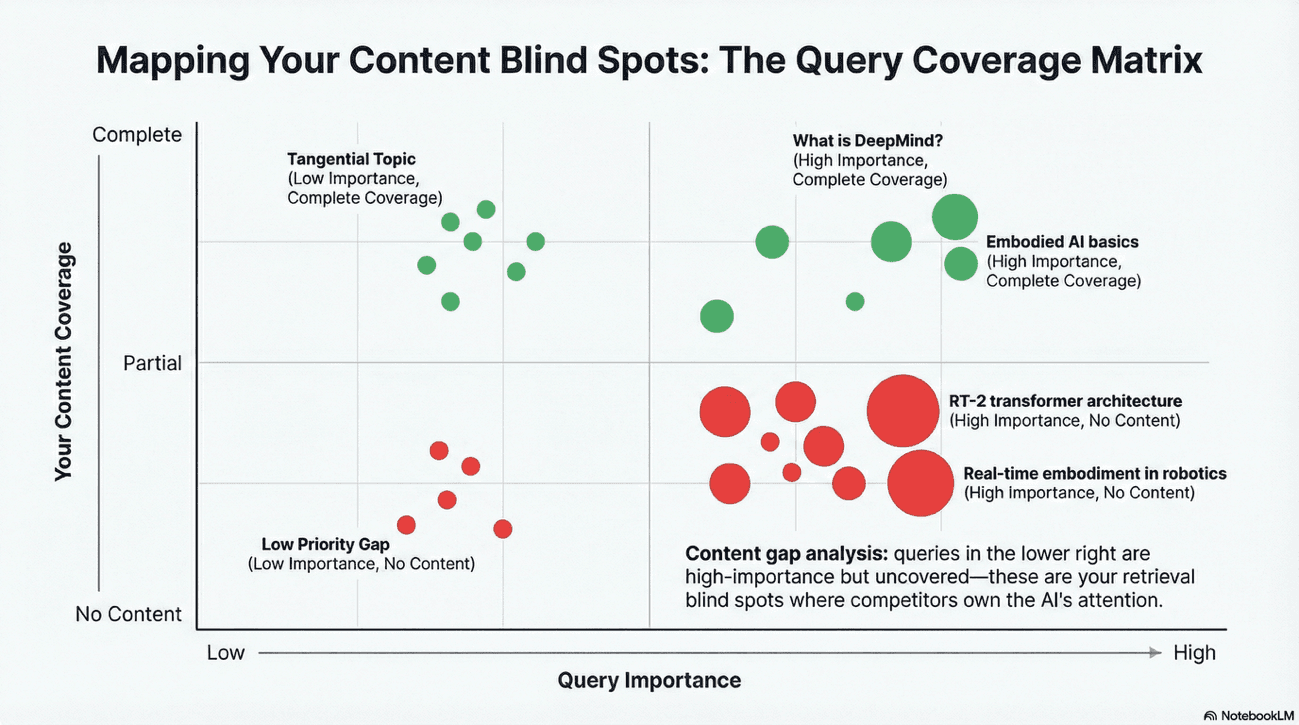
Example: Holding Company Strategy (Alphabet Inc.)
Step | Data Source | Output/Discovery |
|---|---|---|
| Google Trends API | Breakout Query: "Alphabet Waymo revenue split" |
| Gemini Grounding API | Synthetic Fan-Outs: "Waymo commercial expansion 2026," "Alphabet financial reporting by segment," "autonomous vehicle market share 2026." |
| Content Engineering | Create a dedicated, cited table comparing Waymo's growth vs. standard Google Search revenue to satisfy the "financial reporting" synthetic query. |
Implementation Strategy
Automate via Python: Use the official Google Trends API to pull timeline and relatedQueries data into a dashboard like Waikay.io or a custom Google Cloud instance. You're building a system, not doing manual work.
Predictive Velocity: Don't just react to what ranked yesterday. Use the API's 1,800-day rolling data to identify seasonal fan-out patterns (e.g., product launch windows) and prepare your "Answer Blocks" three months in advance. This is strategic, not reactive.
Verification Signals: Ensure your brand is mentioned alongside these "Breakout" terms on Reddit or YouTube. AI engines use these third-party platforms to verify the entity associations discovered in your Trends proxy analysis. The verification comes from the community, not from you.
The "Time to Value" Test: Above-the-Fold Engineering
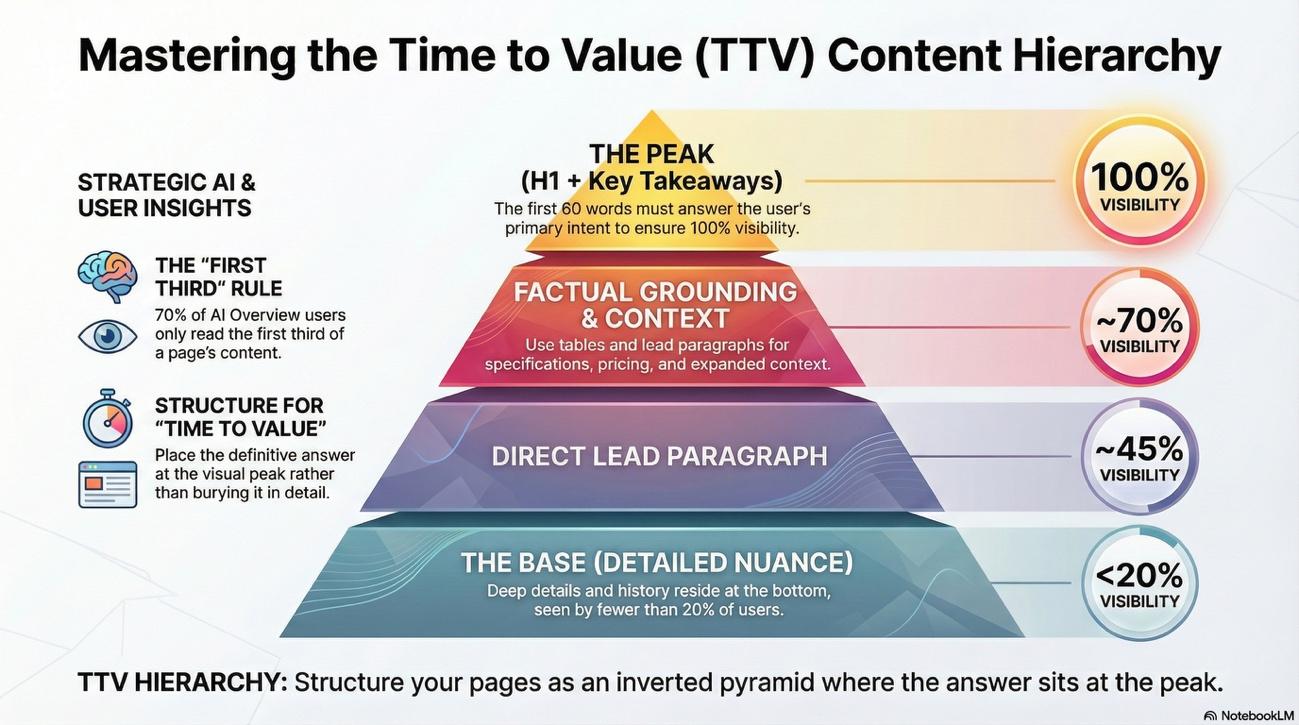
Here's something which has caught the attention of many practitioners: "Above the Fold" has transitioned from a design preference to a technical retrieval requirement.
Research indicates that approximately 70% of users read only the first third of AI Overviews before moving on.
If your brand's specific answer or value proposition is buried in the middle or end of your page, you are effectively invisible to the majority of generative search interactions.
Let me be transparent: this is where many brands fail. Not because they lack good information, but because they've optimized for the wrong audience.
The Mechanism: TTV and the "LastLongestClick"
Google's Navboost and Glue systems track the speed at which a user finds satisfaction.
Here's the scenario: A user clicks your result for a branded query but must scroll through 400 words of introductory "fluff" to find a solution. They'll likely "pogo-stick" back to the results page.
This behavior registers as a "BadClick", signaling to the algorithm that your page failed to satisfy the intent, leading to a long-term demotion for that query.
Conversely, providing an immediate answer secures the "LastLongestClick", which is a signal that identifies when a user finds satisfaction and stops searching. It indicates that yours was the final, satisfying destination for that user's journey.
This is one of the most powerful signals within the Navboost system, and frankly, it's overlooked by many teams focused on traditional SEO metrics.
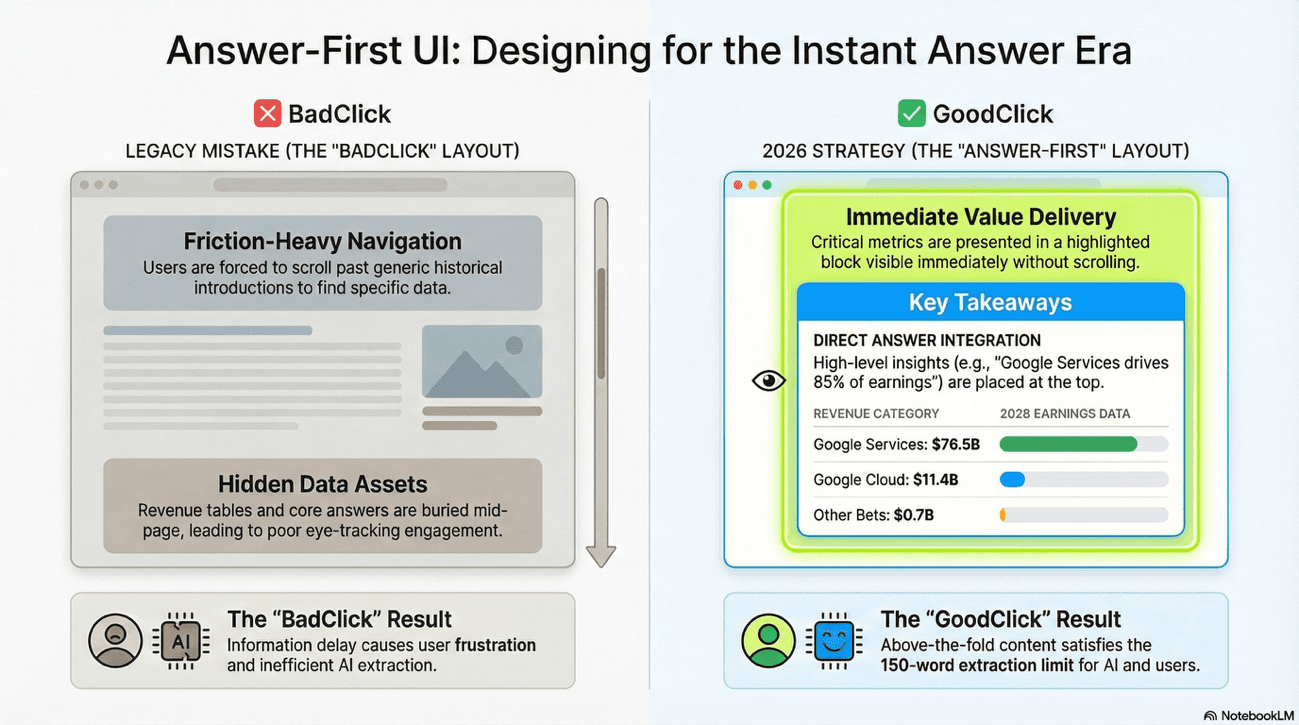
The Workflow: Designing for Immediate Extraction
To pass the "Time to Value" (TTV) test, you must structure your priority pages for "Answer-First" UI:
The "60-Word Rule": Rewrite page introductions to answer the primary intent immediately. This block should be formatted as a single, clear paragraph immediately following the H1. No preamble. No context-setting. Just the answer.
Key Takeaway Blocks: Implement a "Key Takeaways" summary block at the very top of the page. This serves as a focused "preview" that AI models prefer for direct extraction. Think of it as the classic "lead" (or "lede" or "standfirst") used in news articles (journalism knew this technique long before AI).
Factual Grounding Tables: For queries involving comparisons, pricing, or specifications, place a structured data table above the fold. LLMs retrieve these "hard" data blocks more reliably than they "infer" facts from narrative text. Numbers don't hallucinate; prose can.
Example: Holding Company Disambiguation (Alphabet Inc.)
If a user searches for "Alphabet Inc. subsidiary revenue," a legacy page might start with a long history of the holding company, its founding, its pivots; surely all interesting context, but completely useless for the user seeking quick financial data.
An "Answer-First" implementation would look like this:
H1: Alphabet Inc. Subsidiary Revenue 2026
Key Takeaways Block (Above the Fold):
Google Services: $76.5B
Google Cloud: $11.4B
Other Bets (Waymo/Verily): $0.7B
Direct Lead: Alphabet Inc.'s primary revenue is driven by Google Services, accounting for 85% of total earnings. Detailed breakdowns for Google DeepMind and Waymo are listed below.
Why this works: The AI agent can instantly extract the "grounding chunks" needed to answer the user's prompt without parsing the entire document. This reduces the risk of the AI "hallucinating" or selecting a competitor's more structured page as the primary source. You've won before the generation phase even begins.
Implementation Strategy
Audit via Grounding Queries: Use the Bing Webmaster Tools AI Performance Report to see the "Grounding Queries" that lead to your citations. If the AI is grounding its answer in a sentence from the bottom of your page, move that sentence to the top to improve your AI Search Visibility Score. This is data-driven optimization.
Bento Box UI: For complex topics, use a "Bento Box" layout—small, self-contained grids of information—to allow both users and AI bots to "chunk" the information visually and semantically. This is where design meets semantic engineering.
Verification: Use the Gemini Grounding API to test your URLs. If the API fails to extract the core answer in its groundingChunks metadata, your "Time to Value" is too low, and the page requires restructuring. Test before launch.
Securing the "LastLongestClick": Transitioning from Generic Documents to Intent-Specific Nodes
The "LastLongestClick", as hinted before, has emerged as one of the most powerful signals within the Navboost system. It identifies the specific result that successfully "terminated" a user's search journey for a given query.
Picture this: A user searches for "BrandName Refund Policy" and clicks a link that forces them to hunt through a 5,000-word legal document. They'll likely "pogo-stick" back to the results, frustrated and unsatisfied, as we observed previously.
This registers as a "BadClick", signaling to Google that your page failed to satisfy the intent. Repeat this pattern across thousands of users, and your page gets demoted.
We SEOs have been making this mistake for years: treating legal and policy pages as (always ignored) static documents rather than as semantic nodes in a satisfaction network.
The Mechanism: Intent Completion vs. Intent Initiation
Here's the distinction: Google rewards content that "completes the journey," not just content that "starts" it.
When you create a dedicated, high-intent landing page for a specific sub-query, you are optimizing for TTV (Time to Value). By providing the exact answer immediately, you ensure the user stops searching, thereby securing the "LastLongestClick" signal and reinforcing your brand's authority for that entire topical cluster.
The Workflow: Designing for Intent Satisfaction
To successfully implement this strategy, you must move away from treating legal or technical policies as "static files" and start treating them as "intent-satisfaction nodes", aka distinct, focused pages that solve one problem and one problem only:
Decompose Branded Navigational Queries: Identify the top 10 "intent modifiers" attached to your brand name in Search Console (e.g., "login," "returns," "pricing," "API docs"). These are your high-intent entry points.
Monosemantic Landing Pages: Create a unique URL for each modifier. Do not rely on "anchor links" within a single long page; AI engines and Navboost prefer distinct URLs that align perfectly with a single intent. Fragmentation is intentional here.
The "100-Word Rule": Ensure the absolute answer to the specific query is the first thing the user sees. It should be a standalone, monosemantic block of 75–225 words that can be easily "chunked" by an LLM. Precision over volume.
Example: Refund Policy Implementation
The Legacy Mistake: A user searches for "BrandName refund timeline." They're sent to brand.com/terms-and-conditions, which is a massive PDF or a long text wall. They bounce in 5 seconds because they can't find the "timeline" easily and because, let’s be honest, who does love to read the classic “tiny characters” mammoth-sized pages?
The Strategy: Create brand.com/refunds like this:
H1: BrandName Refund Policy & Timeline.
The Intent-Block (Above the Fold): "Refunds are processed within 3-5 business days of receiving your return. To be eligible, items must be sent back within 30 days of purchase. Start your return process [Link] here."
Structured Data: Use FAQPage schema for this specific block to help AI assistants extract the timeline for direct answers.
Why this works: The user finds the "3-5 days" answer in seconds and stops searching. Navboost records this as a highly successful interaction. Furthermore, if an AI agent performs a Query Fan-Out for "How long do BrandName refunds take?", your dedicated /refunds page provides a perfect, grounded passage to cite.
As a side effect, this is the kind of page Google Merchant asks you to prominently link to from the PDPs and in your Merchant profile.
Doing so, you've optimized for satisfaction, not for SEO.
Implementation Checklist
Audit Navigation: Ensure these high-intent pages are linked directly from your footer or help center so they earn sufficient internal "PageRank" to be crawled as distinct entities. Links are votes; make sure they're cast.
Verify Grounding: Use the Gemini Grounding API to test the URL. If the AI extracts your refund timeline as a groundingChunk, your "LastLongestClick" strategy is working. Measure it.
Monitor Search Console: Track the "Average Engagement Time" for these specific landing pages. A rise in engagement time alongside a stable CTR indicates you have successfully captured the user satisfaction signal. This is your proof.
The Evolution of Zero-Click Search
The impact of zero-click behavior has intensified significantly in the past 12/16 months.
The Datos/Sparktoro research reflects that zero-click searches now account for 34% of traditional Google searches, but this figure spikes to 43% when an AI Overview (AIO) is present and reaches a staggering 93% within Google's dedicated AI Mode.
This shift necessitates a re-evaluation of brand strategy, not a minor adjustment, but a fundamental reorientation. The goal is no longer just to drive a click to the website, but to ensure that the brand is the "source" or the "answer" displayed directly on the SERP.
Visibility in 2026 is measured by influence within the search interfaces themselves, making brand name recognition and trust more valuable than the actual traffic volume, which is increasingly mediated by AI synthesis.
Snippet Engineering for Zero-Click Branded Visibility
What to do: Since users may never leave the SERP, your brand must "win the impression" by becoming the primary source for the AI Overview or Featured Snippet and other SERP Features:
Source-First Formatting: Structure your most authoritative definitions as 40–60 word blocks. This is the optimal length for AIO extraction. Brevity paired with precision.
Action Example: Instead of a long intro, start your "What is [Product]" page with: "[Product] is a [Category] designed to solve [Problem]." This clear entity-first sentence is 3x more likely to be cited as the grounding source in a summary. The AI prefers clarity over context.
The 2025 "Great Clarity Cleanup": Rigorous Entity Validation
One of the most significant developments missing from the perspective held until recently is the massive contraction of the Knowledge Graph that happened in June 2025.
During this "Great Clarity Cleanup," Google removed approximately 3 billion entities, representing a 6.26% reduction of its total understanding of the world.
This update fundamentally changed the requirements for a brand to be recognized as a "named entity".
The Demise of Ambiguous "Thing" Entities
The recommendation held until recently (simply "improve your presence" in the Knowledge Graph by creating profiles on secondary tiers like Crunchbase or Glassdoor) is now insufficient.
In 2025, Google actively targeted "multityped" and ambiguous entities. The removal of over 8 billion "Thing" classifications signals a shift toward "unityped" clarity.
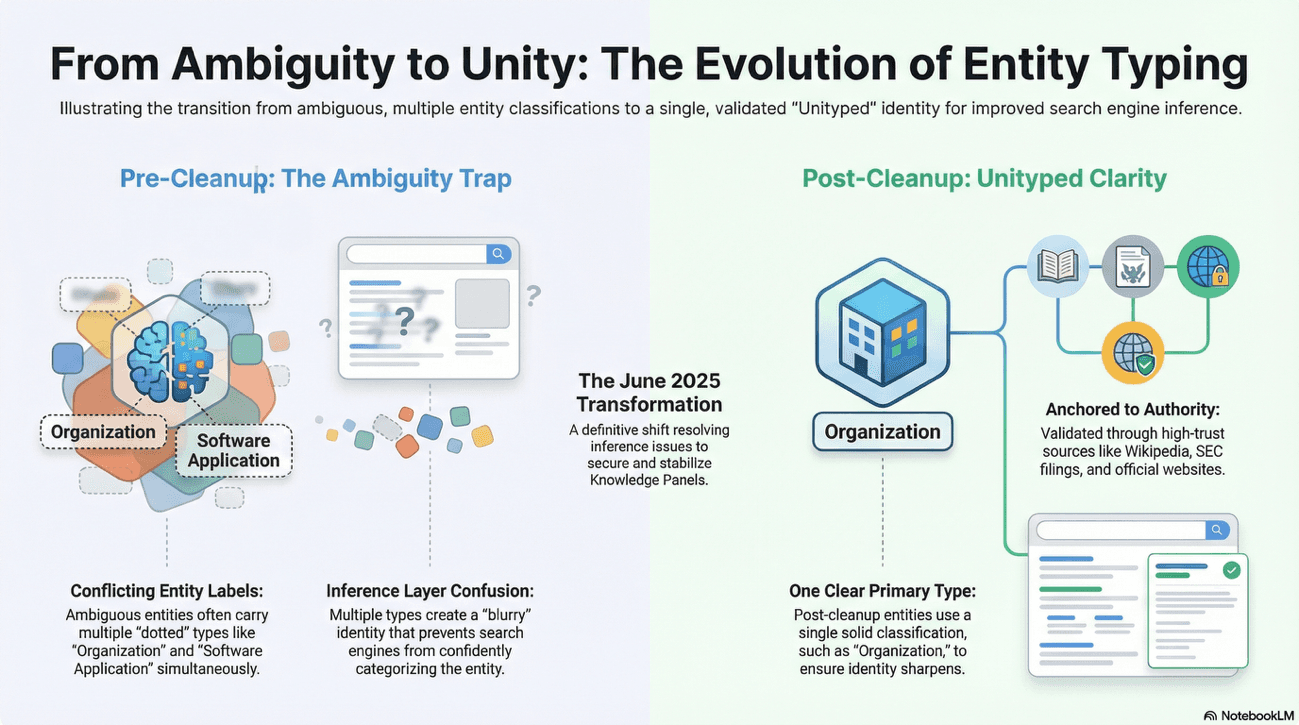
Here's the mechanical reason: multityped entities created confusion in the Knowledge Graph's inference layer.
When the AI couldn't determine what type of entity it was dealing with, it couldn't reliably ground citations in that entity's information. The cleanup forces unambiguous categorization, ensuring that every entity has a single, primary type and clear boundaries.
To survive the purge, an entity must have unambiguous links to a specific category (e.g., Organization, Person, or Product) supported by consistent external validation.
Cleanup Factor | Until Recently Baseline | 2026 Requirement |
|---|---|---|
Entity Typing | Ambiguous "Thing" status was an easy entry point. | Entities must be "unityped" (e.g., strictly an Organization) for confidence. |
Validation Sources | Social media and second-gen tiers were enough. | Requires high-authority validation (Wikipedia, Wikidata, major news). |
E-E-A-T Focus | Expertise was a general content goal. | Specific focus on "Person" entities with verified credentials and "knowsAbout" links. |
Relationship Mapping | Mentions were sufficient. | Requires "entity-linking" to authoritative definitions and other established entities. |
Reclaiming and Validating Your Knowledge Node
What to do: Use the Google Knowledge Graph Search API (or tools like SerpApi or Audits.com) to check your brand's "Confidence Score:”
The Reclamation: If a Knowledge Panel appears for your brand, and you don’t own it, you must "Claim" it immediately. This process links your Google Account to the entity, allowing you to suggest corrections and prevent "Perception Drift" (where the AI associates you with the wrong industry). Control your own narrative.
Action Example: If your SerpApi analysis shows your brand type as "Thing," you must update your sameAs links in your Schema to point only to authoritative, category-validated sources (like an official SEC filing or a Wikipedia page) to force a re-classification to "Organization." Force clarity through structured data.
The Strategic Elevation of Person Entities
The 2025 cleanup also saw a three-fold increase in the scrutiny of "Person" entities. Google is now aggressively removing secondary classifications from person entities to ensure there is no doubt regarding their expertise.
This directly updates any earlier thinking on allies and author credibility.
SEO must now prioritize the creation of robust, unityped identities for the people behind the content.
Author bio pages are no longer just for user trust; they are critical for "algorithmic knowledge" where a person's identity must be clearly linked to an organization via structured data.
Think of it as the difference between a Wikipedia byline and a verified credential system. One is informational; the other is architectural.
Implementing "Person" Expertise Signals
What to do: Transition from anonymous "Editorial Team" bylines to verified expert profiles:
Specific Property Implementation: Use the knowsAbout property in your Person schema to list specific topics the author is an expert in. This isn't just metadata but algorithmic credibility.
Action Example:
{
"@context": "https://schema.org",
"@type": "Person",
"@id": "https://www.games-workshop.com/authors/darren-latham#person",
"name": "Darren Latham",
"additionalName": "Daz",
"jobTitle": "Warhammer Miniatures Designer Content Lead",
"worksFor": {
"@type": "Organization",
"@id": "https://www.games-workshop.com/#organization",
"name": "Games Workshop Ltd"
},
"knowsAbout": [
"Mini Painting",
"Eavy Metal Painting",
"Sculpting",
"Fine Arts"
],
"sameAs": [
"https://www.instagram.com/darrenlatham/",
"https://www.youtube.com/@darrenlatham"
]
}
This forces the AI to associate the content's quality with Darren Latham's pre-existing entity authority. You're building credibility bridges and not simply publishing content.
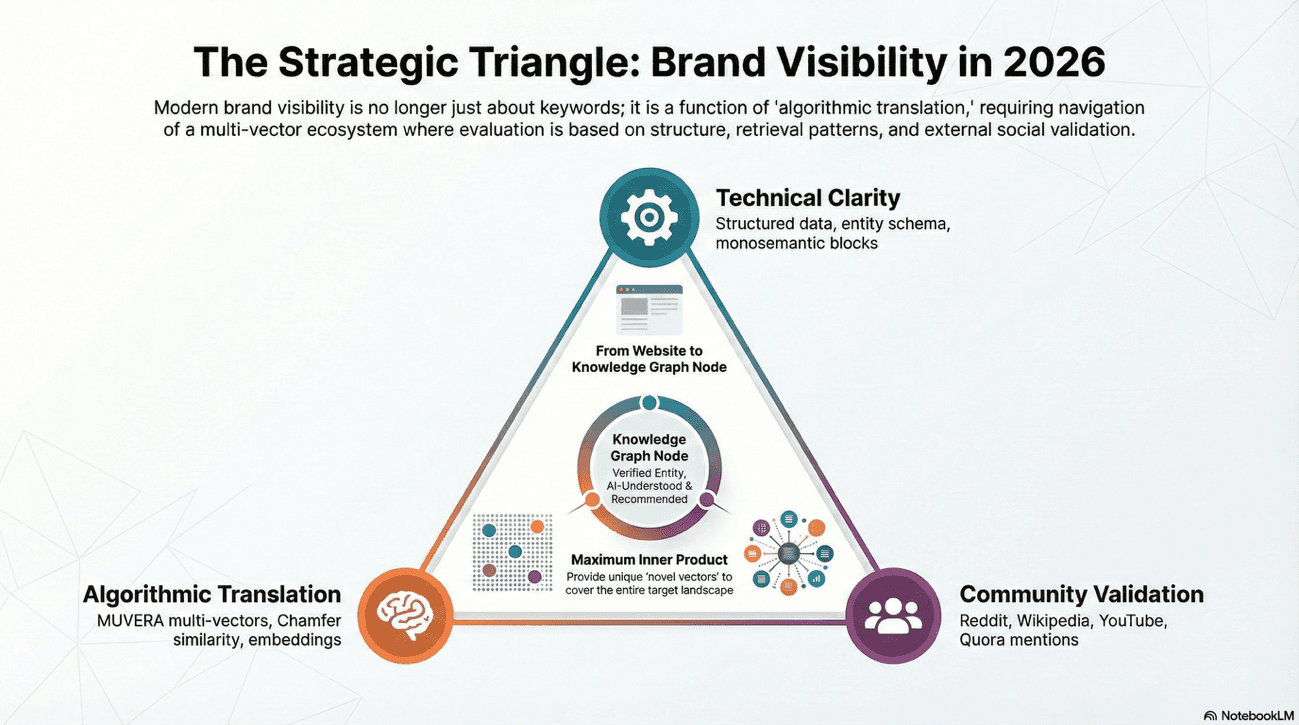
MUVERA and the Multi-Vector Retrieval Revolution
The most profound technological shift occurring between the perspective held until recently and the actual landscape is the deployment of MUVERA (Multi-Vector Retrieval Architecture).
In June 2025, Google transitioned from traditional keyword matching to a semantic-first approach that evaluates queries through multiple dimensions simultaneously.
Imagine MUVERA as the difference between playing chess by looking at individual pieces versus understanding the entire board as a unified force field. It's a paradigm shift, not a tactical update.
Implementation Reality and the Retrievability Gatekeeper
While the technical specifications of MUVERA - such as Fixed Dimensional Encoding (FDE) - are heavily documented, its official status in live search remains a point of industry debate. Google representative Gary Illyes clarified in late 2025 that while he did not confirm MUVERA's specific architecture is in production, the system uses "something similar" to handle high-dimensional retrieval.
This technology acts as a "retrievability gatekeeper," determining which documents even reach the ranking layer by compressing complex multi-vector data to achieve 90% lower latency and a 10% boost in relevance. It's the filter before the filter.
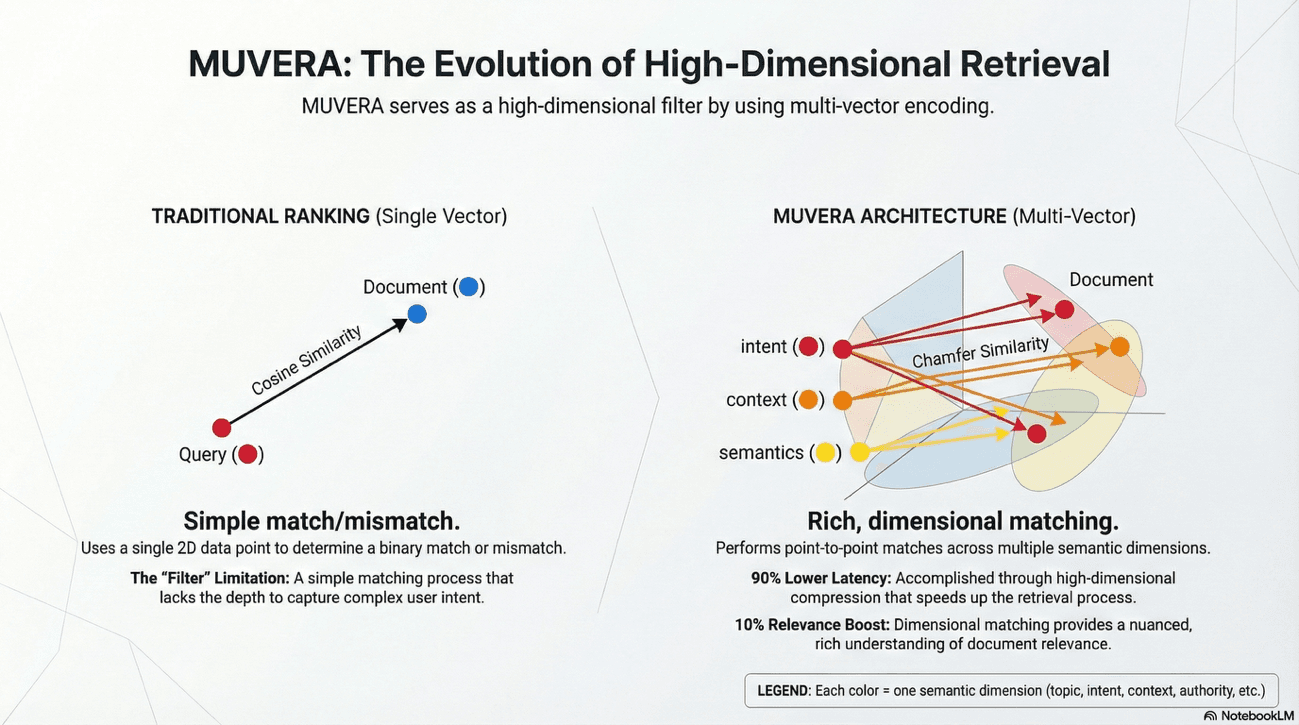
From Keywords to High-Dimensional Embeddings
MUVERA represents document relevance through multi-vector embeddings rather than a single vector.
For the brand strategist, this means traditional keyword-centric tactics are obsolete. In other words, they're simply less effective than semantic positioning.
MUVERA specifically evaluates the "semantic richness" and "topical depth" of content.
A page that merely repeats a keyword cannot match the multiple vectors that a comprehensive resource provides.
The "beneficial purpose" described until recently is now measured by how well a brand's entire content ecosystem covers the related aspects of a topic.
Chamfer Similarity and Content Coverage
A core technical component of MUVERA is the use of the Chamfer similarity measure, which assesses how information in one multi-vector embedding is found within another to capture complex, multi-intent queries.
$$\text{Chamfer Similarity}(Q, D) = \sum_{q \in Q} \max_{d \in D} \text{cos}(\theta_{q,d})$$
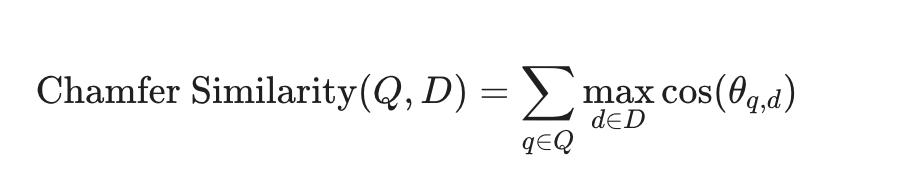
Chamfer similarity rewards documents that contain answers to multiple aspects of a query simultaneously. If a user's prompt requires answers across five related dimensions, your document must address all five to achieve a high Chamfer score.
It's not about hitting one bullseye but covering the entire target landscape.
To rank and being visible now, a brand's content must provide the "Maximum Inner Product" across these vectors.
This is effectively a mathematical confirmation of the advice held until recently to avoid "indistinguishable" content; if a piece of content does not provide unique "information gain" (new vectors), it will be filtered out by the precision culling of the retrieval layer.
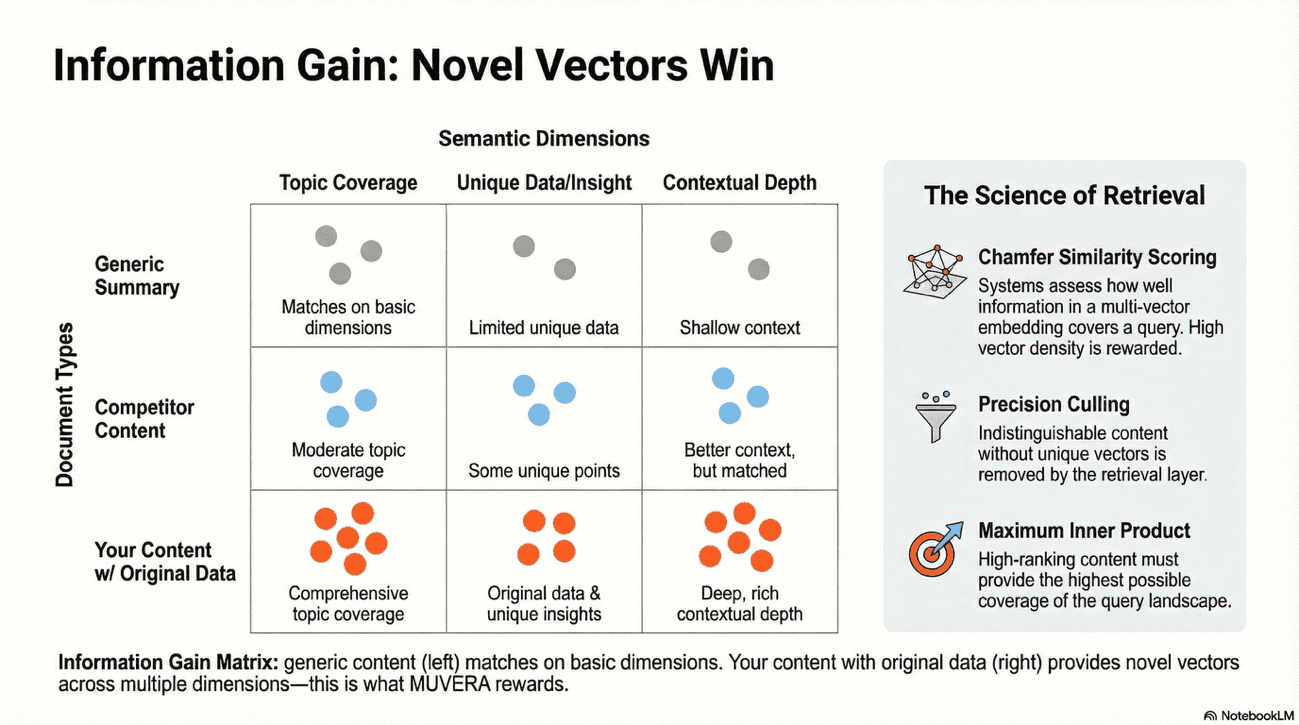
Information Gain Audit
What to do: Don't write what everyone else is writing. MUVERA rewards "Novel Vectors", aka original perspectives, unique data, proprietary insights.
Original Data Blocks: Include unique statistics, proprietary survey results, or specific case study data in your content. If you have internal data, use it. If not, conduct research that produces it.
Action Example: If writing about "SEO Trends," don't just list them. Include a table of your own internal data showing CTR changes you've observed. This "Information Gain" provides the model with a unique vector that makes your page more "retrievable" than a generic summary. You're not competing on topic; you're competing on insight.
Strategic Translation: Structured Data and Knowledge Graphs
The philosophy that structured data is a system of "labels" - has become a strategic imperative now. However, the implementation has moved from page-level markup to the construction of a "Content Knowledge Graph."
This is the difference between tagging and mapping. When mapping, you're building a semantic network, and not just annotating pages.
Advanced Entity Relationship Mapping
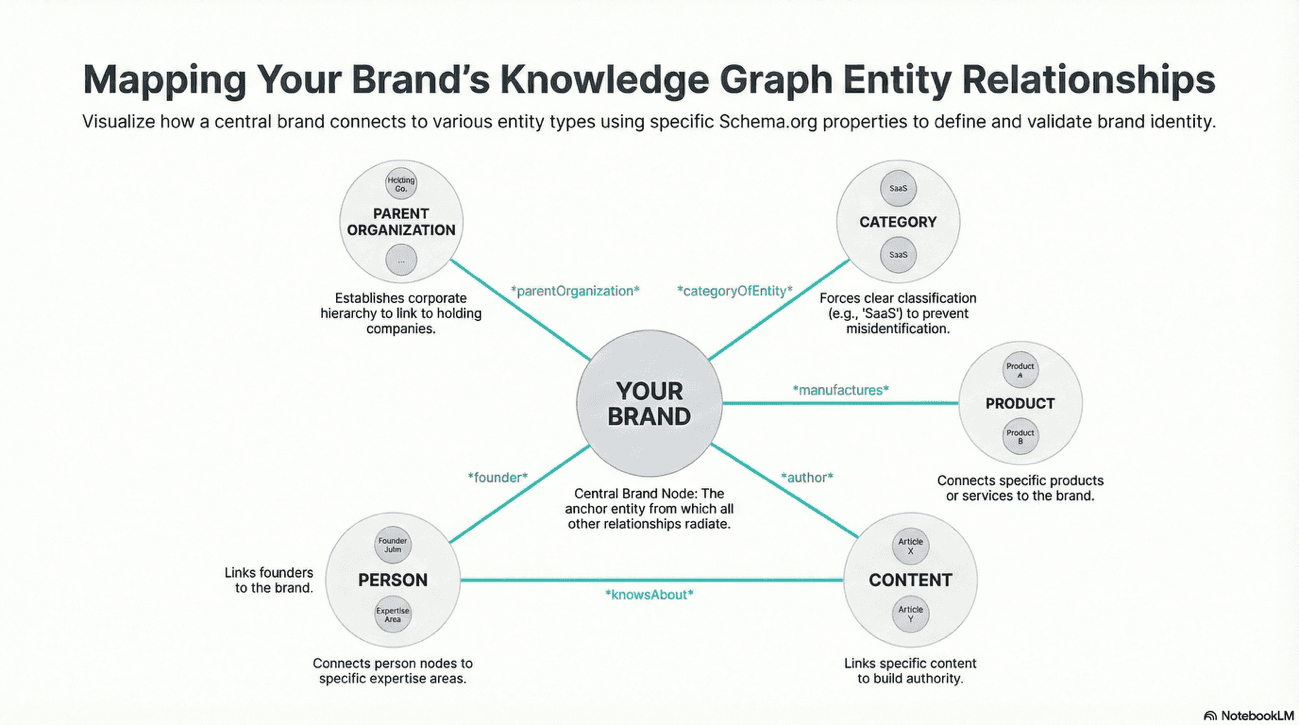
A brand's structured data must now map the "entity lineage" of the organization. This involves creating a connected web of data where an Organization manufactures a Product, which is featured on a WebPage, and with a Review by an Author, who is a Person with specific credentials.
Now, sites with comprehensive Organization schema are 3.7 times more likely to earn a Knowledge Panel.
These connections allow Google's entity resolution system to connect disparate mentions of your brand across the web into a single, authoritative entity node. Without this mapping, a mention of your product on Reddit might not resolve back to your organization's Knowledge Panel. Structured data transforms scattered brand mentions into a unified entity understanding—it's the connective tissue of the semantic web.
Schema Type | Critical Property 2026 | Purpose |
|---|---|---|
Organization | sameAs | Links brand to social profiles, Wikipedia, and official registries for entity reconciliation. |
Person | knowsAbout | Explicitly declares topic expertise to support E-E-A-T. |
Product | brand | Connects a specific product to the parent organization entity. |
Article | author | Nested Person schema that validates human creation in an AI-heavy world |
FAQPage | mainEntity | Structured Q&A format that AI systems prefer for direct answer extraction. |

Schema Example: Holding Company JSON-LD
What to do: To establish a clear hierarchy (e.g., Alphabet > Google > DeepMind), you must use the parentOrganization and subOrganization properties with unique @id pointers to prevent entity fragmentation.
Example (Holding Company Structure):
{
"@context": "https://schema.org",
"@graph": [
{
"@type": "Corporation",
"@id": "https://www.abc.xyz/#organization",
"name": "Alphabet Inc.",
"subOrganization": [
{ "@id": "https://www.google.com/#organization" },
{ "@id": "https://www.deepmind.com/#organization" }
]
},
{
"@type": "Organization",
"@id": "https://www.google.com/#organization",
"name": "Google",
"parentOrganization": { "@id": "https://www.abc.xyz/#organization" },
"url": "https://www.google.com"
},
{
"@type": "Organization",
"@id": "https://www.deepmind.com/#organization",
"name": "Google DeepMind",
"parentOrganization": { "@id": "https://www.abc.xyz/#organization" },
"url": "https://www.deepmind.com"
}
]
}
Why this works: The use of @id allows Google to treat these as distinct but connected entities, ensuring that the "Brand Bias" of the parent company (Alphabet) correctly flows down to the authority scores of the sub-brands. You're building entity authority pyramids.
Content Engineering: Monosemanticity and Chunking for Branded SEO
The "quality" of content, as discussed until recently, has been redefined by the technical requirements of LLM retrieval systems.
In 2025, the concept of "Monosemanticity" (usually referred to, albeit incorrectly, as "clarity") has emerged as a primary "retrieval signal" for AI search.
This is where technical precision meets readability. Let me explain why this matters.
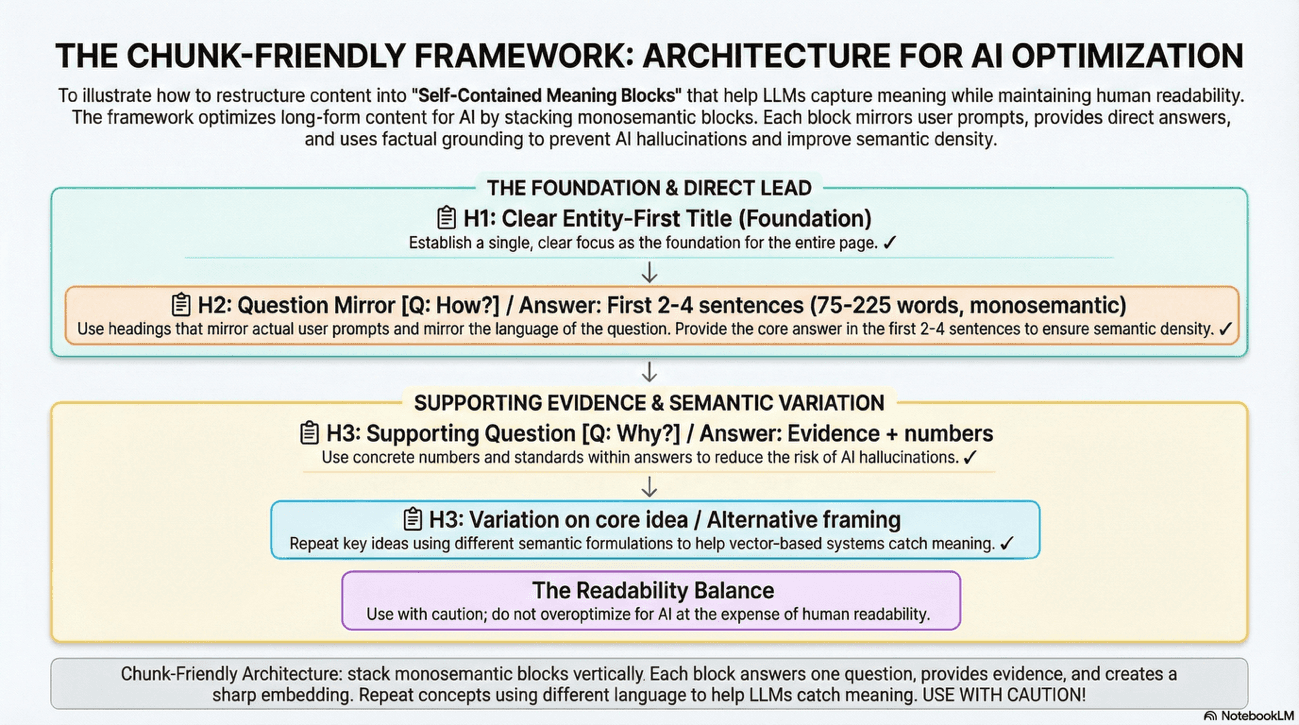
The "One Block = One Idea" Content Rule
LLMs do not read entire pages; they ingest and "chunk" information into segments of approximately 75 to 225 words. For a brand's content to be successfully retrieved, each chunk must have a clear, consistent, and singular meaning; a property known as monosemanticity.
LLMs chunk information into segments of 75–225 words because this range represents the optimal "semantic density", which are large enough to capture complete ideas, small enough to avoid information diffusion in embedding space.
Content that is "diluted" with metaphors, jokes, or lyrical digressions is often overlooked by embedding algorithms because its vector representation becomes too noisy.
You're writing for machines, but you're also still writing for humans. The balance matters.

The Chunk-Friendly Framework for Branded Content
What to do: Restructure your long-form articles into "Self-Contained Meaning Blocks:"
Question-Based Headings: Use H2 and H3 tags, better if they mirror actual user “prompts” (e.g., "How does calculate [Metric]?"). Mirror the language of the question.
Direct Leads: Provide the core answer in the first 2-4 sentences of a section, avoiding long introductions. Get to the point.
Factual Grounding: Use concrete numbers and references to standards to reduce the risk of AI hallucinations during the generation phase. Numbers are anchors; they keep AI from drifting into invention.
Repetition with Variation: Unlike traditional SEO which avoids redundancy, LLM optimization encourages repeating key ideas using different semantic formulations to help vector-based systems catch the meaning from multiple angles. Say it once, say it again differently, say it a third way.
At the same time, though, remember that you also write for human readers, so pay attention not to "overoptimize" for chunking because you would end up creating AI Slop or simply awful-to-read content.
Remember: chunkability cannot prevail at the expense of readability. Balance is the keyword when writing.
If not well executed, “AI Copywriting” can lead to a sort of “keyword stuffing 2.0”, which can be detrimental for classic search, as we know well. As the classic pharma ads are obliged to say, “Use with caution”.
The "Search Everywhere" Paradigm: Multi-Channel Brand Citation Stability
The concept of the brand "flywheel" has expanded into a "Search Everywhere" imperative. If visibility was already a multi-platform endeavor, now it is even more so.
If you're still thinking in silos - "SEO is here, social is there" - you're already behind. The future is integrated.
The Influence of Community and UGC on Branded SEO
During training, LLMs ingest massive datasets where third-party community sites (Reddit, Wikipedia, Quora, YouTube) vastly outnumber brand-controlled content.
This creates a statistical bias in how models reason about information: a brand claiming "best product" appears in isolation on brand.com; a user on Reddit describing the same product appears as part of a larger conversational pattern across thousands of similar discussions.
When the LLM is asked to generate an answer, it interpolates across this training distribution. If your product appears authentically across multiple independent contexts, the model treats it as more reliable "ground truth" than a single canonical claim. This mechanism operates in parallel to Navboost, not as a replacement for it.
Navboost optimizes ranking via on-site behavioral signals (clicks, dwell time, scroll depth). Community signals, by contrast, influence how an LLM contextualizes and reasons about your brand during generation.
Specifically:
During retrieval, the AI preferentially selects sources that appear across multiple platforms.
During generation, the model's understanding of your competitive position is shaped by how users position you relative to alternatives in community discussions.
The aspects users emphasize on Reddit or Quora become weighting signals for which of your features the AI prioritizes in responses.
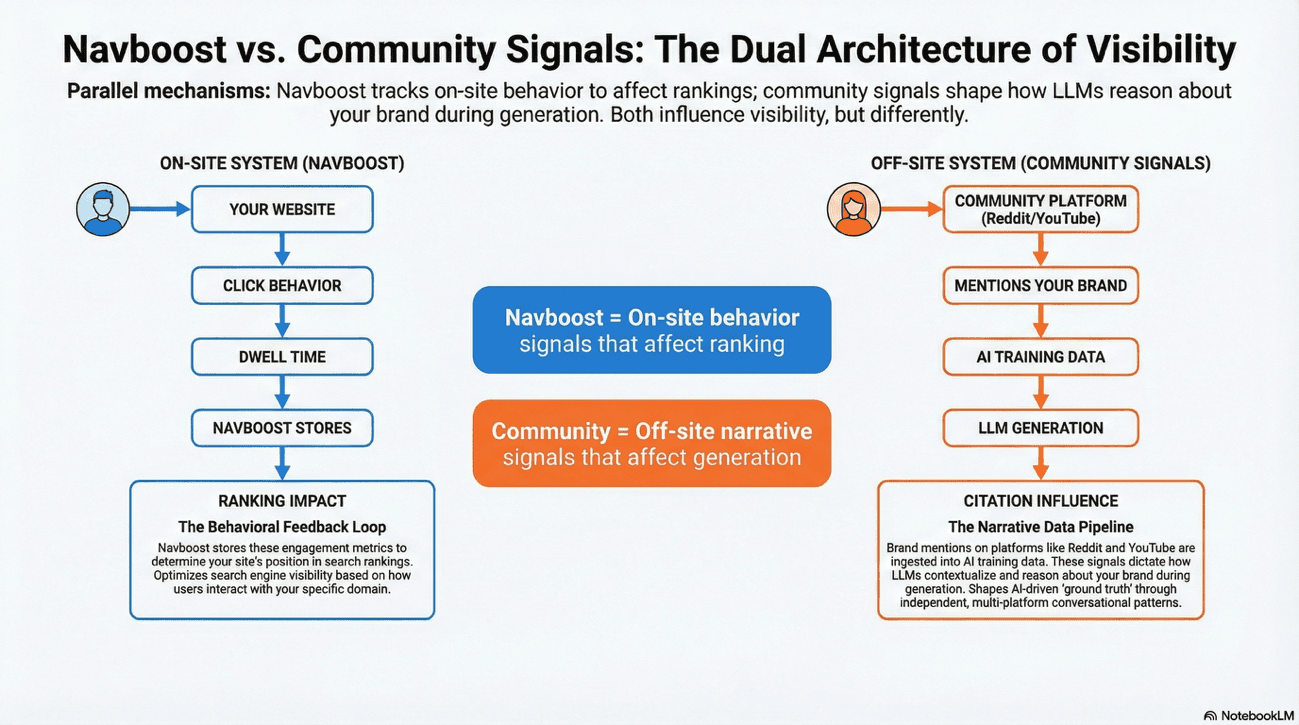
To influence both systems simultaneously, you must "win" behavioral validation on third-party platforms the same way you win it on-site. When Reddit users repeatedly mention your brand alongside industry problems they've solved, or when YouTube creators demonstrate your product in action, those interactions don't directly affect your SERP ranking, but they do shape how the AI reasons about your brand during the generation phase of retrieval.
This is citation influence, a separate, parallel mechanism to Navboost. It's not about clicks; it's about how the model has learned to associate your brand with solutions.
The platforms themselves serve different functions in this process:
Platform | Training Signal | Use Case in AI Discovery |
|---|---|---|
Authentic problem-solving and peer validation | Users describing real use-cases, comparisons, and solutions involving your brand. AI models weight these as genuine because they appear in unmoderated, cost-free environments. | |
Wikipedia and Wikidata | Entity legitimacy and category definition | Foundational verification that your brand exists, its category, and its relationship to adjacent entities. LLMs use Wikipedia as an anchor point for entity resolution. |
YouTube | Multimodal authority and demonstration | Visual context that validates claims. A creator showing your product solving a problem provides evidence the AI can reference when grounding answers. |
Quora | High-intent, niche-specific Q&A | Direct answers to situational and edge-case questions. LLMs prioritize Quora responses for specific, technical questions where generic answers fail. |
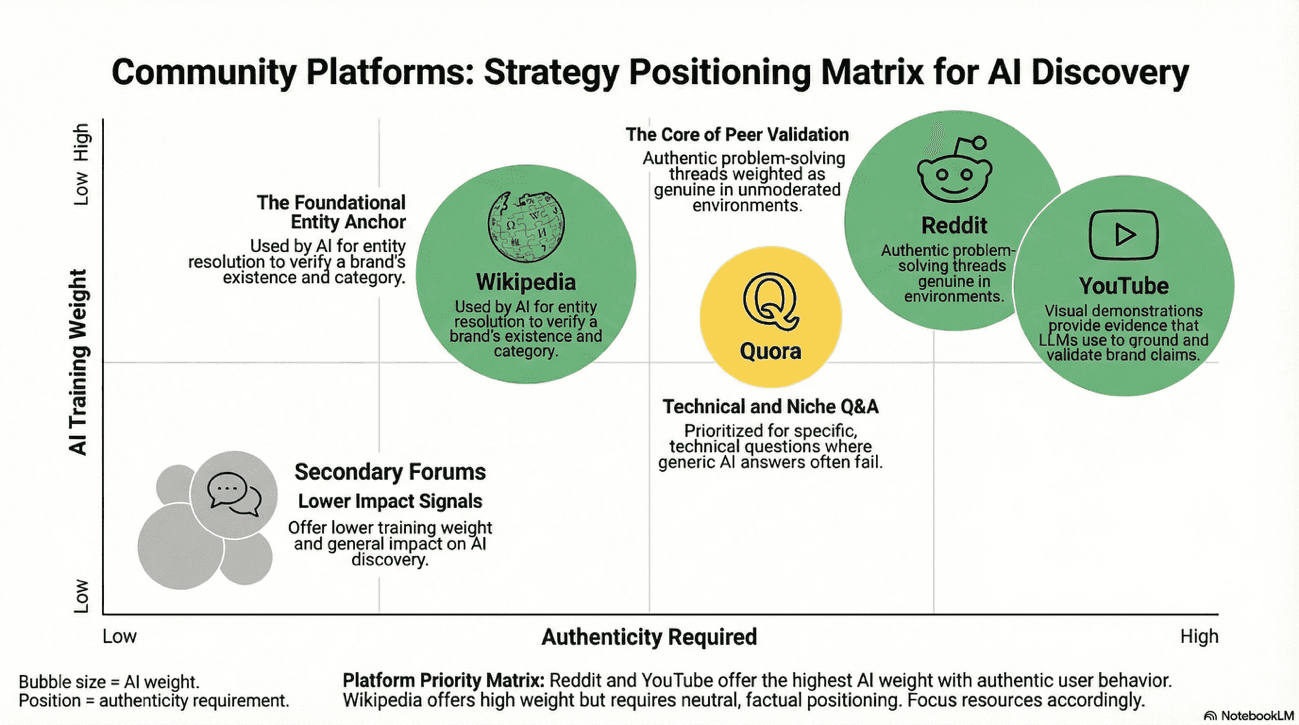
What You Can Do: Multi-Channel Branded SEO Execution
Treat third-party platforms not as separate "social media strategy" but as an extension of your brand's retrievability infrastructure. The goal is not viral reach but consistent, authentic brand presence in the contexts where your audience naturally discusses problems your product solves:
Reddit: Monitor relevant subreddits for recurring questions your brand addresses. Encourage (but do not orchestrate) customers to share their solutions. Authenticity is detectable.
Wikipedia: If your brand warrants a Wikipedia page, maintain accuracy and neutrality. Don't edit your own page (Wikipedia has a strict “Conflict of Interest (COI)” policy). If you are cited within related articles, ensure that information is correct and the categorization is accurate (e.g., if you're a logistics SaaS, ensure you're mentioned in the "Supply Chain Software" category article). Use the Wikipedia API to monitor references.
YouTube: Commission or partner with creators who authentically use your product. The transcript becomes a "verification signal": the AI extracts solutions and context from the video's natural language, not from a branded script. Authenticity matters because embeddings can detect coached language. Use real creators with real opinions.
Quora: Answer specific, long-tail questions your audience searches for but rarely finds satisfying answers to. This is not about promoting your brand but about answering the question so thoroughly that the AI, when grounding a response, has no better source to cite. Become the expert the AI refers to.
The result: your brand becomes retrievable not because of a single citation percentage, but because the AI's training data naturally associates you with solutions, verified across independent sources.
Multi-Channel Semantic Mentions
What to do: Mention your brand in the correct semantic context across third-party platforms to associate your name with unbranded keywords:
UGC Seeding: Encourage customers to use your brand name alongside industry terms on Reddit. Not "use our product"; but "use our product to solve [real problem]."
Video-Led Authority: Integrate video into your topic clusters. Multimodal AI analyzes video context to provide more engaging, cited answers.
Action Example: Partner with a YouTube creator to review your product. The transcript of that video becomes a "verification signal" that AI engines use to confirm your brand's authority. The creator's authentic voice is worth more than a thousand brand taglines.
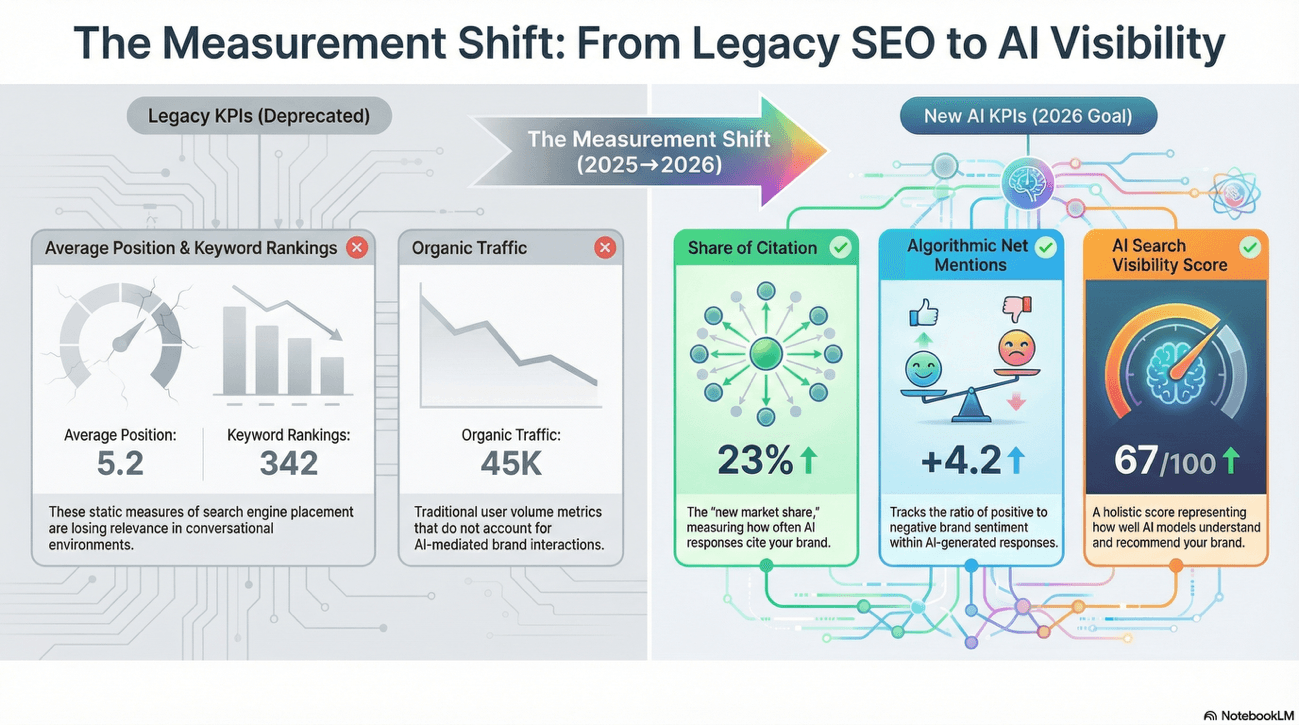
Measurement: From Rankings to Share of Citation in Branded SEO
The most significant break from the traditional SEO playbook is the limitation of rank-tracking as a primary KPI. As zero-click interactions dominate, the metric of "average position" has lost its predictive value.
If you're still only reporting average rankings to your stakeholders, you're telling a story about the past, not the future.
Brand Visibility Metrics for 2026
Share of Citation: Measures the percentage of AI responses for a target query set that cite the brand. This is the new "market share" for branded SEO. Share of Citation is best measured by sampling 50–100 target queries monthly and checking AI responses across ChatGPT, Gemini, and Copilot. Tools like Advanced Web Rankings or Waikay.io automate this, but there’s still value in manual sampling provides ground truth.
Algorithmic Net Mentions (ORM): This tracks the technical ratio of positive to negative brand mentions within AI responses. This is essential for protecting the brand narrative in a conversational search environment. One bad mention in an AI Overview can damage your reputation at scale.
AI Search Visibility Score: Use aggregate sampling to obtain a stable score (out of 100) representing how well different models understand and recommend your brand. This is holistic and not about one AI or one query set.
First-Party Performance Reporting for Branded SEO
What to do: Remember to give the due attention to official reports:
GSC Branded Queries Filter (Nov 2025): Use this filter in Google Search Console to isolate performance for your brand and product names. This is necessary because "AI Mode" engagement is now mixed into your totals, making it difficult to measure brand equity without the filter. You need clarity; this provides it.
Bing Webmaster Tools AI Performance Report (Feb 2026): Monitor the "Grounding Queries" log. This reveals exactly which natural-language prompts Copilot used to retrieve your content, allowing you to fill content gaps you previously missed. It's like reading the AI's mind.

A Strategic Roadmap for Brand-Search Integration
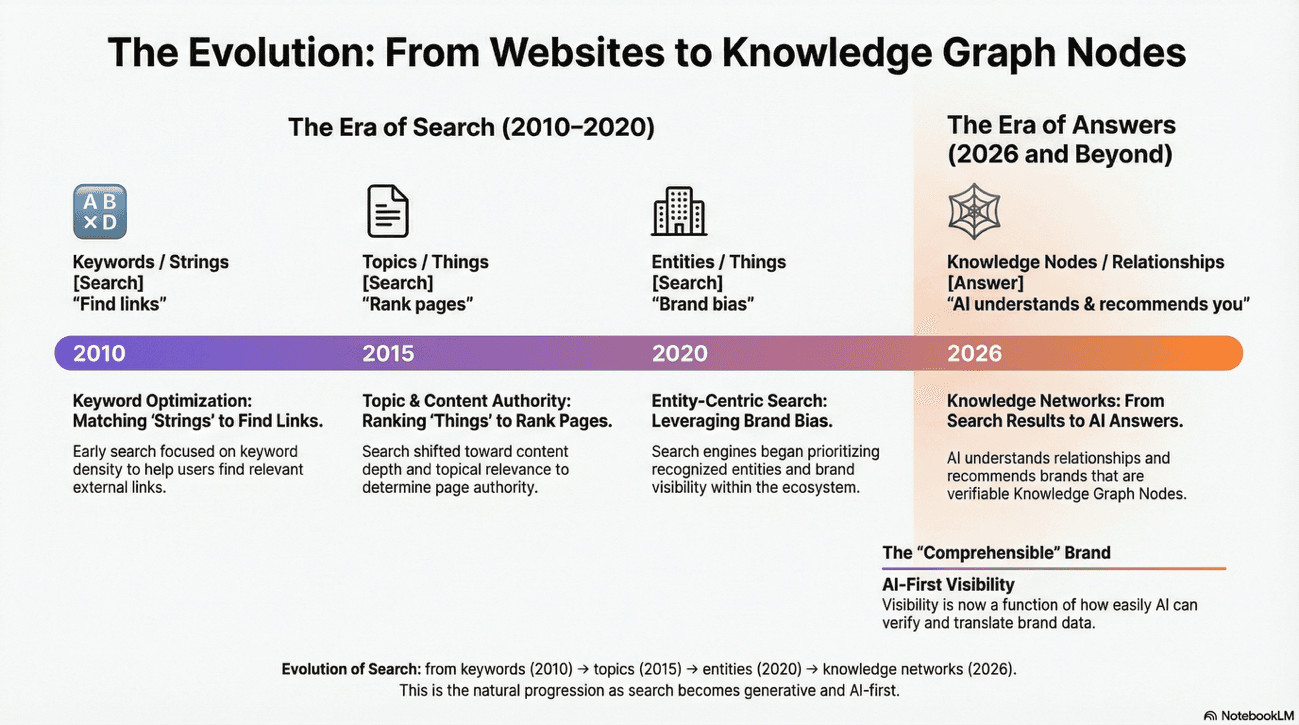
The baseline for brand visibility remains correct in its central premise - brand bias is the core of modern search - but it was incomplete in its understanding of the infrastructure of that bias. Now, brand visibility is a function of algorithmic translation.
The path toward visibility now requires navigating a multi-vector, entity-centric ecosystem where the winner is the brand that is most "comprehensible" and "verifiable" to artificial intelligence.
By adopting this brand-centric, AI-aware approach, organizations can transition from being mere "websites" to becoming recognized "Knowledge Graph Nodes", ensuring they remain visible and trusted in an era where the answer is more important than the link.
A final note
This guide is a living framework, not a static playbook. The landscape will continue to evolve, but the principles - clarity, authenticity, and semantic depth - will endure.
Build for the machine; optimize for the human. Master both, and you'll own the future of branded search.

Article by
Gianluca Fiorelli
With almost 20 years of experience in web marketing, Gianluca Fiorelli is a Strategic and International SEO Consultant who helps businesses improve their visibility and performance on organic search. Gianluca collaborated with clients from various industries and regions, such as Glassdoor, Idealista, Rastreator.com, Outsystems, Chess.com, SIXT Ride, Vegetables by Bayer, Visit California, Gamepix, James Edition and many others.
A very active member of the SEO community, Gianluca daily shares his insights and best practices on SEO, content, Search marketing strategy and the evolution of Search on social media channels such as X, Bluesky and LinkedIn and through the blog on his website: IloveSEO.net.



