
The semiotics and composition grammar of mid-to-long form YouTube on the big screen
YouTube is now the dominant force on the largest screen in most homes, and this shift fundamentally rewrites the semiotic grammar of online video.
And it is so since December 2024, when TV officially surpassed mobile as the primary device for YouTube viewing in the United States by watch time, as confirmed by CEO Neal Mohan in his February 2025 annual letter.
Viewers now watch more than 1 billion hours of YouTube on television screens every day.
As of July 2025, YouTube commanded 13.4% of all U.S. TV viewing according to Nielsen's Media Distributor Gauge, widening its lead over second-place Disney (9.4%) by four full share points.
This migration to the living room restores the full communicative power of horizontal composition, reinvigorates classical film-semiotic structures, and demands that creators, brands, and analysts understand a visual grammar that operates at a fundamentally different scale than mobile-first short-form video.
This shift matters because it repositions YouTube content within viewing contexts historically governed by cinema and broadcast television; lean-back, co-viewed, and experienced on screens where compositional subtlety, depth staging, and narrative architecture can be fully perceived.
The implications cascade through every layer of video semiotics: from Kress and van Leeuwen's compositional metafunction regaining its full horizontal articulation, to Metz's syntagmatic categories finding new expression through YouTube's chapter marker system, to Barthes's hermeneutic code operating across twenty-minute arcs that would be impossible in short-form.
YouTube's migration to the living room in numbers
The data trail documenting YouTube's television ascendancy is unambiguous. Nielsen's monthly "The Gauge" report has tracked YouTube at the top of U.S. streaming charts for over two consecutive years.
The trajectory moved from 8.1% of total TV time in April 2023, to a then-record 9.7% in May 2024, to 13.4% by July 2025, and 12.5% in February 2026 followed by Netflix with 8.8.
YouTube now accounts for more than a quarter of all streaming viewership in the United States, operating in a market where streaming itself surpassed combined broadcast and cable for the first time in mid-2025, reaching 44.8% of total TV viewership.
The device-level shift is equally striking.
While global YouTube consumption still skews mobile (approximately 63% of watch time as of the most recent public breakdown), the U.S. pattern has inverted:
More than 150 million Americans watch YouTube on connected TVs monthly (source).
The number of top creators receiving the majority of their watch time on TV screens increased by more than 400% (source).
Creators earning a majority of their YouTube revenue from TV screens grew over 30% year-over-year by September 2024 (source).
YouTube's quarterly ad revenue crossed $11.3 billion in Q4 2025, with CTV campaigns driving more than 50 million average monthly conversions and delivering 4.5× higher return on ad spend than ads on other streaming services.
Viewing behavior diverges sharply across devices.
Television sessions run two to three times longer than mobile sessions (source). The 20-to-45-minute video range represents the sweet spot for TV consumption (source).
Critically, 65% of YouTube CTV watch time is spent on content exceeding 21 minutes (source), which is a figure that renders mid-to-long form the default grammar of YouTube's fastest-growing surface.
Mobile remains the domain of lean-forward, active consumption; television viewing is lean-back, often co-viewed with friends and family, and characterized by what YouTube's product team describes as "discovery mode", aka browsing and sampling through slower, remote-control-mediated navigation rather than the rapid thumb-scrolling of mobile feeds.
The migration of YouTube to connected TV fundamentally changes how discoverability works. Long-form video is no longer competing only inside YouTube’s recommendation system, but across Google Search, AI Overviews, multimodal search engines, and living-room browsing interfaces.
Advanced Web Ranking helps you monitor this evolving visibility landscape across both traditional rankings and AI-generated discovery experiences.
Try AWR free to understand how your video content appears across modern search environments.
How horizontal composition regains its full grammar on the big screen
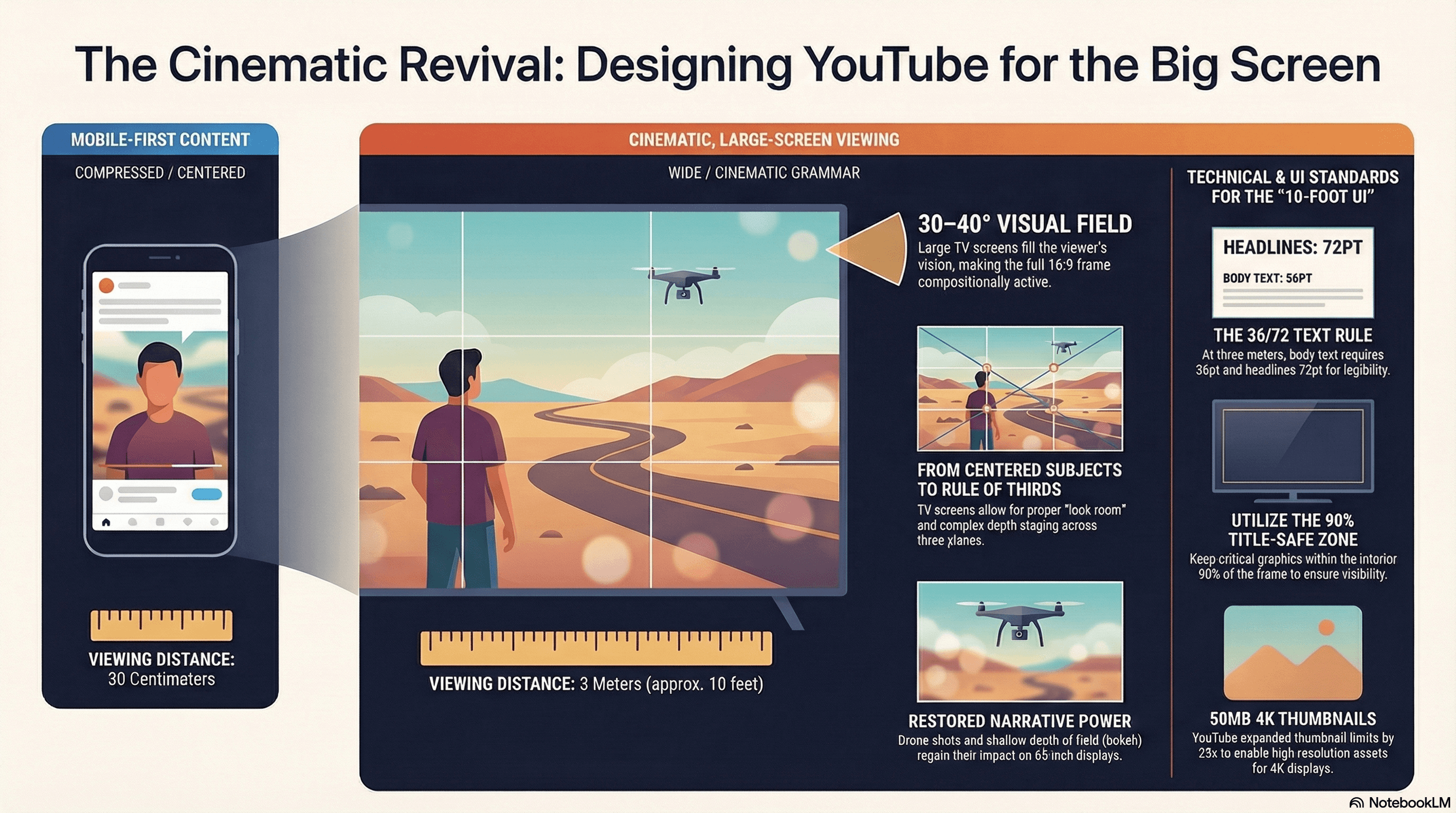
The perceptual difference between a 6-inch phone at 30 centimeters and a 65-inch television at three meters is not merely quantitative but grammatically transformative.
A large TV screen fills approximately 30–40 degrees of the viewer's visual field, approaching cinematic proportions. At this scale, the full 16:9 frame becomes compositionally active:
Wide establishing shots communicate spatial relationships.
Leading lines direct the eye through the thirds grid.
Depth staging across foreground, midground, and background becomes legible and impactful.
On mobile, peripheral compositional elements — negative space, background detail, perspective geometry extending to frame edges — are functionally invisible. The centered, tightly framed subject that dominates mobile-optimized content represents a compositional compression necessitated by the medium, not a stylistic choice.
The return to television-scale viewing reinstates classical horizontal composition principles that YouTube creators had progressively abandoned during the mobile-first era.
Rule-of-thirds placement of talking-head subjects, with proper "look room" and "nose room," reads correctly on large screens where the full nine-quadrant grid is perceptible.
Shallow depth of field — the signature "premium" look achieved by creators like MKBHD shooting on RED cameras at wide apertures — transforms from a subtle distinction on a phone screen to a dramatic compositional statement on a 65-inch display, where bokeh occupies significant visual real estate.
Drone establishing shots in documentary-style content from creators like Johnny Harris and Casey Neistat regain their narrative power to establish location, mood, and scale.
The implications for text readability are particularly acute. Research on viewing distance and text legibility indicates that at the standard TV viewing distance of approximately three meters, minimum body text should be approximately 36 points, with headlines at 72 points. Amazon's Fire TV "10-foot UI" guidelines recommend 28 pixels minimum on 1080p screens as a floor, while Apple's tvOS guidelines specify that text must be designed for legibility at distance.
UX designers have noted that TV interface design aligns more closely with billboard design than with app design. For YouTube creators, this means lower thirds, graphic overlays, and on-screen text designed for mobile viewing may become illegible on television, or conversely, that text designed for TV legibility appears comically oversized on a phone.
The practical recommendation: clean sans-serif fonts, high-contrast color combinations, semi-transparent background plates, and placement within the title-safe interior 90% of the frame.
YouTube has responded to these quality demands with platform-level interventions. In 2025, the thumbnail file size limit was expanded from 2MB to 50MB, enabling full 4K-resolution thumbnails.
AI-powered "Super Resolution" now automatically upscales sub-1080p videos to HD for better presentation on 4K televisions.
The platform also introduced a "Shows on TV" feature allowing creators to organize long-running series into seasons with a Netflix-style episode-select interface, immersive auto-playing channel previews, and a redesigned watch page with streamlined controls and a dedicated description panel that opens without obscuring the video.
The migration of YouTube to connected TV fundamentally changes how discoverability works. Long-form video is no longer competing only inside YouTube’s recommendation system, but across Google Search, AI Overviews, multimodal search engines, and living-room browsing interfaces.
Advanced Web Ranking helps you monitor this evolving visibility landscape across both traditional rankings and AI-generated discovery experiences.
Try AWR free to understand how your video content appears across modern search environments.
Kress and van Leeuwen's visual grammar at full horizontal capacity
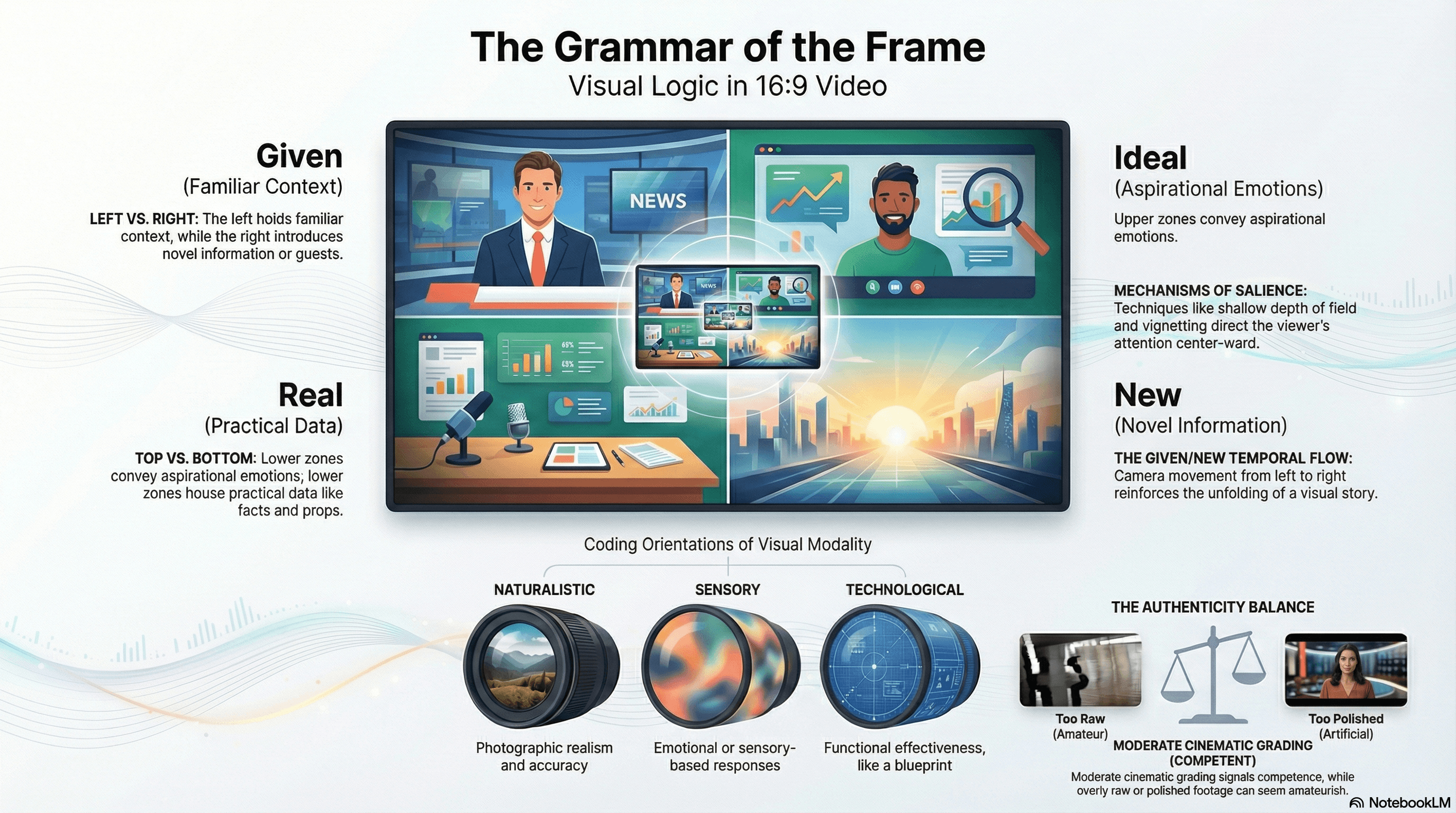
Gunther Kress and Theo van Leeuwen's framework from Reading Images: The Grammar of Visual Design — identifying representational, interactive, and compositional metafunctions in visual communication — regains its full analytical power when applied to 16:9 video consumed on large screens.
Their compositional metafunction, organized around three interrelated systems of information value, salience, and framing, operates with a spatial precision that small-screen viewing cannot support.
The Given/New axis — left-positioned elements carrying established, familiar information and right-positioned elements carrying novel, key information, derived from Western left-to-right reading conventions — becomes fully operative in television-scale horizontal video.
In the talking-head format, many YouTubers position themselves in the left third of the frame as the "Given" (the familiar, established presenter), while graphics, products, or demonstrations appear in the right portion as the "New" information being introduced.
Interview formats follow this convention: interviewer (Given) screen-left, interviewee (New) screen-right.
Documentary-style content from creators like Johnny Harris places establishing context in the left visual field of map graphics, with new findings or revelations occupying the right.
In moving image, the Given/New axis becomes temporal as well as spatial — camera movement from left to right can reinforce the informational flow, and the sequential unfolding of a video builds "Given" context that frames subsequent "New" revelations.
The Ideal/Real axis — top-positioned elements carrying generalized, aspirational, emotionally appealing content and bottom-positioned elements carrying specific, practical, grounded information — maps directly onto YouTube's visual conventions.
The presenter's face in the upper frame portion occupies the Ideal zone (persona, authority, emotional connection), while the body and any desk or props in the lower portion occupy the Real zone.
Lower thirds literally inhabit the Real territory — the practical, informational data of names, titles, and facts.
YouTube thumbnails consistently place aspirational hooks (dramatic expressions, exciting imagery) in the upper portion and specifics (text, product details) in the lower portion.
Salience — the differential visual weight created through size, color, focus, tonal contrast, and foregrounding — is the compositional system most deliberately manipulated by professional YouTube creators:
Shallow depth of field isolates the subject through sharpness against blur.
Cinematic color grading creates salience through warm skin tones against cooler backgrounds.
Vignetting, a technique explicitly used in post-production, darkens frame edges to direct attention center-ward.
These tools function as salience mechanisms that reward the larger canvas of television viewing, where subtle gradations of focus and color are perceptible in ways they simply are not on a phone.
The concept of visual modality — the degree to which a visual claims to represent truth or reality — is particularly productive for analyzing YouTube's distinctive aesthetic.
Kress and van Leeuwen identify four coding orientations:
Naturalistic (photographic realism).
Sensory (emotional/sensory response)
Technological (blueprint effectiveness).
Abstract (essential qualities).
YouTube content operates in a hybrid genre-specific coding orientation where moderate color grading, clean lighting, and clear resolution signal a combination of authenticity and competence. Excessive cinematic treatment reads as "trying too hard" or "inauthentic," while too-raw footage reads as "amateur."
Ravelli and Van Leeuwen noted in a 2018 Visual Communication article that in the digital age, "familiar markers of modality are being creatively reconfigured" by new technological affordances.
Andrew Burn's concept of the "kineikonic mode" extends the Kress and van Leeuwen framework to moving image, analyzing how film and video construct meaning through the interaction of image, sound, gesture, and editing, which is a framework directly applicable to YouTube's multimodal composition.
The migration of YouTube to connected TV fundamentally changes how discoverability works. Long-form video is no longer competing only inside YouTube’s recommendation system, but across Google Search, AI Overviews, multimodal search engines, and living-room browsing interfaces.
Advanced Web Ranking helps you monitor this evolving visibility landscape across both traditional rankings and AI-generated discovery experiences.
Try AWR free to understand how your video content appears across modern search environments.
The narrative architecture of retention editing
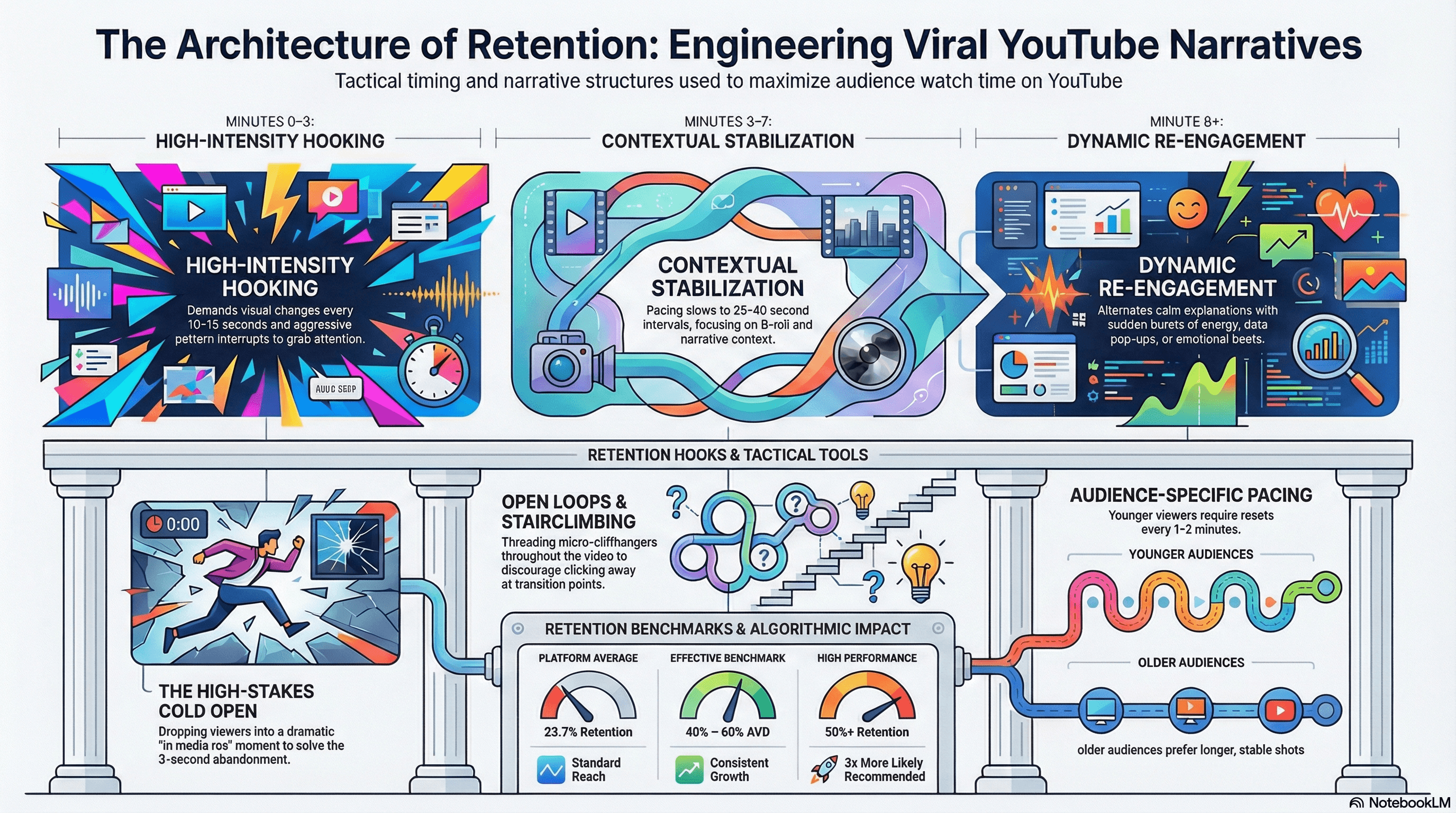
YouTube's audience retention graph has become the single most influential force shaping the editing grammar of mid-to-long form video.
"Retention editing" — the strategic deployment of cuts, visual variety, and narrative devices to maximize the percentage of a video that viewers watch — operates as an algorithmically incentivized semiotic grammar with identifiable conventions.
Platform-wide average retention sits at approximately 23.7%, with only 16.8% of videos surpassing 50% retention (source). The benchmark for effective long-form content is 40–60% average view duration (source), with videos achieving 50% or higher being approximately three times more likely to receive algorithmic recommendation.
As YouTube strategist Paddy Galloway has observed, "An extra 10% audience retention can be the difference between a video getting 100k views or 1 million."
The temporal structure of retention editing follows a characteristic rhythm mapped by AIR Media-Tech's analysis of thousands of long-form channels:
Minutes zero through three demand high energy with frequent visual changes every 10–15 seconds, pattern interrupts, and aggressive hooks.
Minutes three through seven stabilize with fewer cuts and more contextual B-roll at 25–40-second spacing.
After minute eight, the grammar shifts to alternating calm explanation with short bursts of energy as reaction inserts, data pop-ups, and emotional beats.
This rhythm mirrors attention flow: stimulate, calm, re-engage.
Critically, this framework is audience-dependent: younger viewers (13–24) require visual change every 15–25 seconds and attention resets every one to two minutes, while audiences over 25 prefer shots held 20–40 seconds with cuts only at topic or tone shifts. Over-editing actively decreases retention for older demographics.
The cold open has emerged as the dominant opening structure.
Borrowed from cinematic technique, the cold open begins in media res, aka dropping the viewer into a dramatic moment from later in the video before backtracking to the beginning.
This activates what Barthes would recognize as the hermeneutic code: an enigma is posed before the narrative has been established.
The opening five to fifteen seconds represent the highest-stakes retention battleground, with 50–60% of viewers who abandon a video doing so within the first three seconds.
Beyond the cold open, creators deploy direct promise hooks ("In this video, I'll show you..."), provocative questions, shocking statistics, and challenge or stakes hooks — each designed to create what the creator economy calls a "curiosity gap" that compels continued viewing.
Open loops function as sustained hermeneutic structures threaded throughout the video.
A creator previews something coming later ("I'll show you the trick that changed everything... but first"), creating micro-cliffhangers that discourage click-away at each potential abandonment point.
The "staircasing" effect builds segment by segment, creating a sense that something larger is approaching.
Combined with escalation (as in Hot Ones' increasing spice levels), this structures the entire video around forward momentum. Pattern interrupts — camera angle changes, B-roll cutaways, on-screen graphics, sound effect punctuation, location changes — function as attention-reset mechanisms. When Buffer added systematic pattern interrupts to previously flat videos, they reported that "audience retention skyrocketed."
Chapter markers as explicit syntagmatic segmentation
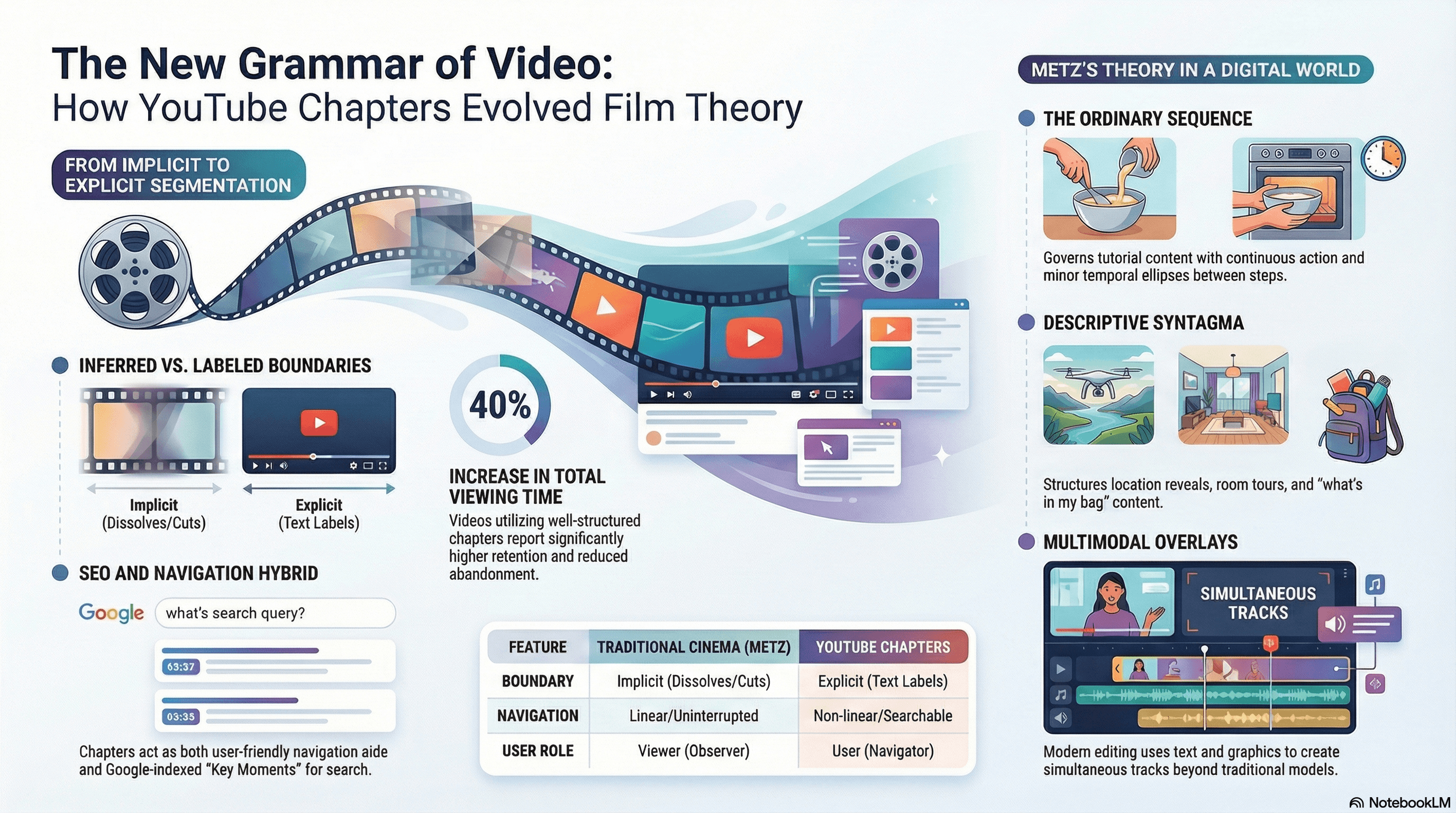
YouTube's chapter marker system (the timestamps), introduced in May 2020, creates an unprecedented form of explicit syntagmatic segmentation that has no direct equivalent in cinema or broadcast television.
Where Christian Metz's grande syntagmatique — his taxonomy of eight autonomous segment types structuring cinematic narrative — requires viewers to infer syntagmatic boundaries through punctuation marks like dissolves, fades, and cuts, YouTube chapter markers textually label and delineate autonomous segments with named titles visible on the progress bar.
This creates a hybrid between classical cinematic syntagmatics and the explicit navigation of written text. Chapters function simultaneously as navigational aids (viewers skip to specific segments, reducing frustration-based abandonment), structural markers (visually segmenting the progress bar into titled sections), and SEO enhancers (Google surfaces specific video segments as "Key Moments" in search results).
Videos with well-structured chapters reportedly experience a 40% increase in total viewing time, though this figure should be treated as directional rather than peer-reviewed.
The migration of YouTube to connected TV fundamentally changes how discoverability works. Long-form video is no longer competing only inside YouTube’s recommendation system, but across Google Search, AI Overviews, multimodal search engines, and living-room browsing interfaces.
Advanced Web Ranking helps you monitor this evolving visibility landscape across both traditional rankings and AI-generated discovery experiences.
Try AWR free to understand how your video content appears across modern search environments.
YouTube began testing automated machine-learning-based chapters in late 2020, using text recognition to auto-generate segments, which is a further step toward computationally mediated syntagmatic structure.
Each of Metz's eight syntagmatic types finds expression in long-form YouTube content:
The autonomous shot appears in YouTube intros, outros, and pre-roll hook teasers, which are standalone segments independent of the surrounding narrative.
The parallel syntagma structures multi-topic videos and essay-style content that alternate between thematic threads without precise chronological relationship.
The bracketing syntagma manifests in compilation reels, B-roll montages set to music, and "day in my life" vlogs that assemble shots representing a topic without chronological order.
The descriptive syntagma governs room tours, location reveals, and "what's in my bag" content.
The alternating syntagma drives YouTube documentaries that cross-cut between interview subjects, between present-day footage and archival material.
The scene — continuous time and space — dominates talking-head content.
The episodic sequence structures challenge progressions and transformation videos that compress chronological development into summary form.
The ordinary sequence governs tutorial content with continuous action and minor temporal ellipses between steps.
The critical departure from classical syntagmatics lies in YouTube's normalization of transgressive devices:
Jump cuts are standard rather than disruptive.
Direct address to camera breaks the fourth wall as convention rather than exception.
Multi-modal overlay (on-screen text, graphics, lower thirds) creates simultaneous syntagmatic tracks that have no equivalent in Metz's single-channel model.
Bateman's 2007 extension of Metz — proposing a grande paradigmatique that adds a paradigmatic axis to the syntagmatic — provides a more adequate framework for analyzing YouTube's multi-layered editing grammar.
Classical film semiotics meets the YouTube essay film
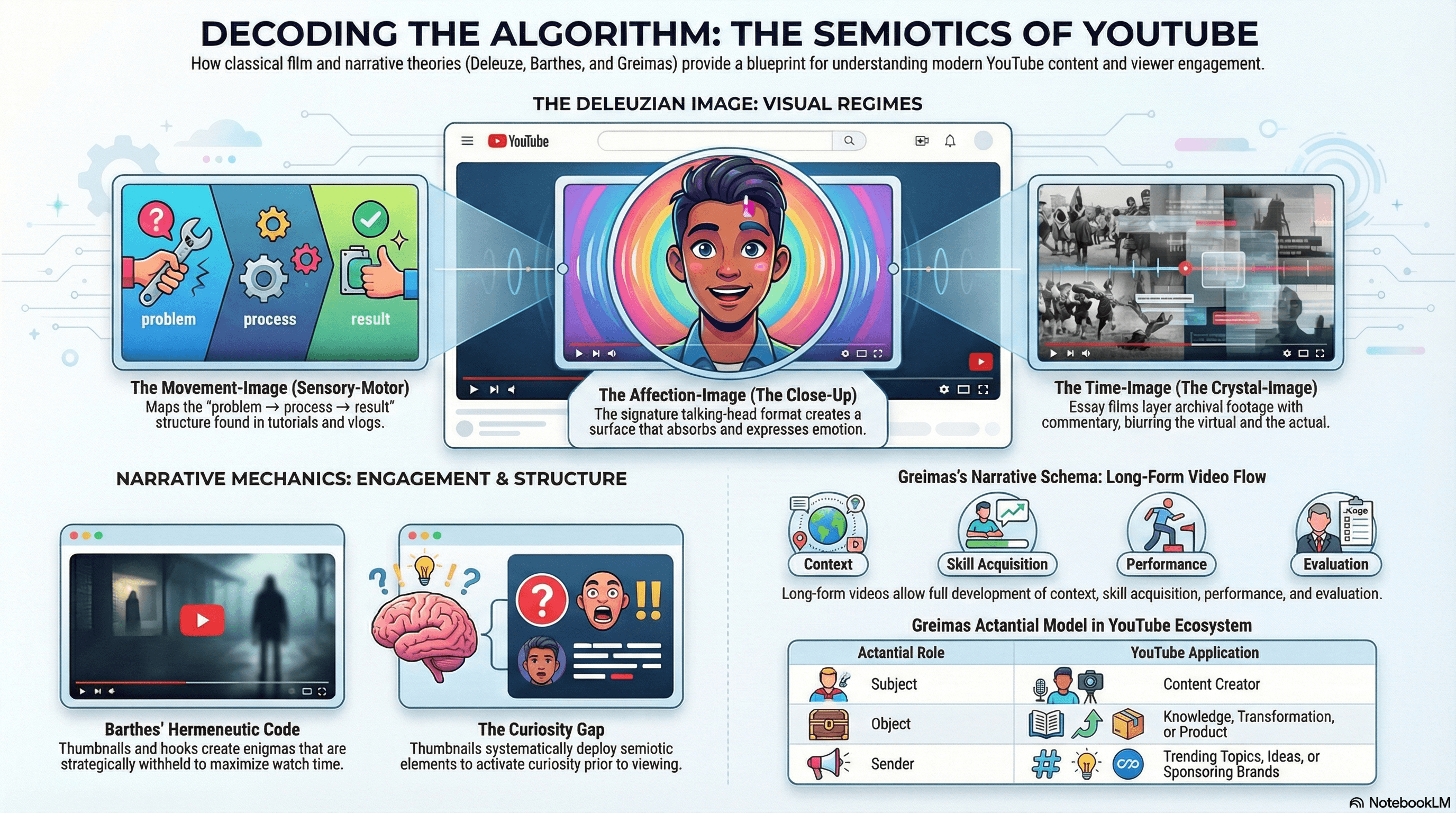
The application of Gilles Deleuze's cinema philosophy to YouTube reveals both productive continuities and generative ruptures.
Deleuze's movement-image — comprising perception-image, action-image, and affection-image — describes the dominant image regime of mainstream YouTube content.
Tutorial content, challenge videos, travel vlogs, and gaming content all operate through sensory-motor schemas where perception leads to affect leads to action. The "situation → action → changed situation" structure that Deleuze identifies in classical American cinema maps directly to the YouTube formula of problem → process → result.
YouTube's signature close-up talking-head format is structurally equivalent to Deleuze's affection-image: the face filling the frame becomes what Deleuze, via Bergson, calls a "reflecting and reflected unity" — a surface that simultaneously expresses and absorbs affect.
First-person POV content (GoPro footage, drone videos, walking tours) embodies the perception-image, while the ubiquitous "any-space-whatever" — Deleuze's espace quelconque, the disconnected, desingularized space of post-war cinema — finds remarkable resonance in YouTube vlogs that transpire in generic hotel rooms, airports, and interchangeable studio backdrops defined not by specificity but by pure potentiality.
The time-image emerges in YouTube's essay film tradition. Channels like Every Frame a Painting, Nerdwriter, and Philosophy Tube produce what Deleuze would recognize as crystal-images: layering archival footage, film clips, and original commentary until the virtual (remembered, referenced) and the actual (present commentary) become indiscernible.
The migration of YouTube to connected TV fundamentally changes how discoverability works. Long-form video is no longer competing only inside YouTube’s recommendation system, but across Google Search, AI Overviews, multimodal search engines, and living-room browsing interfaces.
Advanced Web Ranking helps you monitor this evolving visibility landscape across both traditional rankings and AI-generated discovery experiences.
Try AWR free to understand how your video content appears across modern search environments.
Patricia Pisters's The Neuro-Image (Stanford University Press, 2012) extends Deleuze's dyad into digital screen culture, proposing a third image-type suited to networked, database-driven media that operates through what she describes as moving through a character's brain or mental landscape rather than looking through their eyes.
Her framework explicitly addresses the "spirit of Web 2.0" and the "remixability of contemporary digital culture," making it the most theoretically developed bridge between Deleuzian cinema philosophy and platform video.
Roland Barthes's five narrative codes from S/Z provide perhaps the most directly operational semiotic framework for understanding YouTube engagement mechanics.
The hermeneutic code — the sequential process of enigma thematization, promise of answer, suspended answer, partial answer, and disclosure — is the primary mechanism sustaining viewer engagement across 20-minute-plus videos:
YouTube titles and thumbnails activate hermeneutic codes before viewing: "I Spent 100 Days in Minecraft Hardcore" thematizes an enigma.
The opening hook promises an answer.
Strategic withholding throughout the video ("But before we get to that...") suspends the answer.
Progressive disclosure through chapters reveals portions of the answer, sustaining hermeneutic tension.
The payoff is placed late to maximize watch time.
A 2024 study published on ResearchGate — "Decoding the Visual Language: A Semiotic Analysis of YouTube Thumbnails" — confirmed that thumbnails systematically deploy semiotic elements to activate curiosity prior to viewing.
The creator economy's "curiosity gap" technique is essentially Barthes's hermeneutic code operationalized for algorithmic distribution.
Greimas’s canonical narrative schema benefits from the temporal expansion available in long-form content:
The manipulation/contract phase (one to five minutes of backstory, context-setting, and stake establishment) can be fully developed rather than compressed.
The competence phase (acquisition of resources, skills, evidence) extends through research, interviews, and evidence-gathering.
The performance phase unfolds in real-time detail.
The sanction phase includes YouTube's convention of ending with a call-to-action that adds a meta-level evaluation from the audience.
The actantial model maps cleanly to YouTube narrative structures:
Creator as Subject.
Knowledge or transformation as Object.
Idea or trending topic as Sender.
Audience as explicit Receiver
Tools and collaborators as Helpers
Obstacles or misinformation as Opponents.
Brand-sponsored content follows this schema with particular precision: the brand (Sender) commissions the creator (Subject) to demonstrate the product (Object) for the audience (Receiver).
Thumbnails as paratextual signs in the living room

YouTube thumbnails function as what Gérard Genette would classify as peritext or, in other words, paratextual elements within the same "volume" that frame the primary text.
On CTV, this paratextual system undergoes a significant semiotic shift. Thumbnails render at full 1,280×720 resolution on television interfaces, making every compositional detail — and every flaw — visible.
Yet they are viewed from living room distances, creating a perceptual context closer to poster design than mobile app browsing.
Remote-control navigation creates slower, more deliberate browsing with longer dwell time per impression compared to mobile's sub-two-second decision window.
The visual grammar of effective thumbnails has been empirically mapped:
Videos with human faces receive, on average, 921,000 more views than those without (source).
Expressive faces increase click-through rates by 20–30%.
Thumbnails with more than three distinct visual elements experience 23% lower CTR (source).
High-contrast color combinations (red/blue, yellow/purple, orange/teal) outperform muted palettes (source).
The platform-wide normal CTR range is 2–10%, with even half-percentage-point differences proving statistically significant over millions of impressions.
MrBeast reportedly designs 20–30 thumbnail variations before publishing, and his influence has driven the entire creator ecosystem toward systematic A/B optimization — a practice now supported natively by YouTube's "Test & Compare" feature, which launched broadly in June 2024 and expanded to title testing by December 2025.
The thumbnail-title-channel name triad operates as a unified sign system governed by the principle of complementarity rather than duplication:
The thumbnail provides the emotional and visual promise.
The title provides the semantic and informational frame.
The channel name provides the authorial trust signal.
Jonathan Gray's expansion of Genette for media contexts, in Show Sold Separately, argued that paratexts are not secondary to the text but part of it. On YouTube, this is especially true: a viewer's entire understanding of a video is shaped by the paratextual sign system before they ever press play.
On CTV specifically, where video descriptions are effectively inaccessible through the browse interface and text is less prominent relative to images, the thumbnail bears even greater semiotic weight.
The system becomes more visual and less textual than on mobile, and the browsing context (lean-back, potentially multi-viewer, entertainment-oriented) shifts reception away from information-seeking and toward what Kress and van Leeuwen would identify as a sensory rather than naturalistic coding orientation.
Sound, silence, and the dual-screen semiotic environment

Sound design operates as a parallel semiotic system in long-form YouTube, governed by conventions distinct from both cinema and broadcast television.
The royalty-free music ecosystem has created a recognizable "YouTube sound": clean, mood-specific instrumental tracks serving as emotional architecture rather than foreground content.
Music functions structurally:
Track changes signal narrative shifts.
Tempo matches pacing (60–80 BPM for teaching, 100–120 BPM for builds and challenges).
Volume calibration maintains voice dominance at five to twenty-five decibels below the speaker.
Sound effects operate as punctuation marks in YouTube's editing grammar:
Whooshes mark transitions and add weight to motion.
Dings emphasize important text reveals.
Pops accompany graphic appearances.
Risers build tension before reveals.
These function as a conventional semiotic system legible to platform-native audiences, aka a vocabulary of audio signs that would be foreign to cinema but is instantly recognizable within YouTube's discursive community.
Musical silence — the deliberate dropping of background music before a major reveal — exploits absence as a rhetorical device, creating anticipatory weight through the contrast with the perpetual musical backdrop that viewers have learned to expect.
These audio semiotic resources operate within an increasingly fragmented attention environment. Research consistently shows that 86% of internet users employ a second screen while watching television, with smartphones being the preferred device for 70–79% of dual-screeners.
Only 7% use their second screen for content directly related to what is playing on the main screen.
This creates what can be theorized as a split-attention semiotic environment:
The television provides a primarily audio-visual stream (with audio doing the heavier lifting during moments of visual inattention).
The phone provides a text-and-image stream for social media, messaging, or browsing.
An old but still actual Ipsos eye-tracking study found that during 55% of TV advertising time viewers were not looking at the screen.
YouTube has responded strategically: "pause-vertising" (ads displayed when users pause content), branded QR codes bridging TV and mobile, and a developing second-screen experience allowing phone-based interaction with TV-playing content.
The migration of YouTube to connected TV fundamentally changes how discoverability works. Long-form video is no longer competing only inside YouTube’s recommendation system, but across Google Search, AI Overviews, multimodal search engines, and living-room browsing interfaces.
Advanced Web Ranking helps you monitor this evolving visibility landscape across both traditional rankings and AI-generated discovery experiences.
Try AWR free to understand how your video content appears across modern search environments.
For brands and creators structuring information for the CTV environment, this dual-screen reality means that audio must carry the primary narrative thread during sustained viewing, while visual elements serve to recapture wandering attention through pattern interrupts, high-salience moments, and compositional shifts. Information architecture must be designed so that the core message is receivable through either audio or visual channels independently — a principle that parallels the multimodal redundancy strategies identified in Kress and van Leeuwen's social semiotic framework.
How brands are adapting to the TV-quality imperative
The CTV migration has elevated production value expectations for brand content on YouTube.
4K video uploads rose 35% in 2024 as creators invested in higher production quality for television viewing.
YouTube's CTV-specific advertising products — including Masthead on CTV (full-screen homepage takeovers), YouTube Select CTV (premium creator and sports content buys), Shoppable CTV (remote-control-navigable product browsing), and Peak Points (Gemini AI-powered emotional moment targeting) — position the platform as a direct competitor to traditional television advertising in a market where digital video was on track to capture nearly 70% of all U.S. TV/video ad spend in 2025.
Red Bull represents the gold standard for brand long-form YouTube strategy, with over 27 million subscribers and a Media House employing more than 400 people globally producing content that rivals professional media companies.
Red Bull achieves approximately three to five times more organic views than Monster Energy, despite a narrow market share difference (Red Bull’s ~43% vs. Monster’s ~39% in the US).
This disparity persists because Red Bull operates as a 'Media House' producing substantive long-form documentaries, whereas Monster traditionally focused on 'sponsorship clips', even though Monster has recently pivoted toward longer athlete profiles to close this gap.
The Strategic Insight: From Watch Time to Satisfaction

By 2026, YouTube’s recommendation engine has evolved: while watch time remains a foundation, the primary ranking signal is now 'Viewer Satisfaction' (measured through retention deltas and post-watch surveys).
Long-form content holds a distinct advantage here, as it allows for deeper storytelling that keeps viewers on the platform longer, while chapter timestamps turn a single 20-minute video into dozens of 'Elastic Assets' that the algorithm can serve to satisfy specific, micro-niche search queries.
The SEO and AI Discoverability Layer
The discoverability of long-form content now operates through a sophisticated multimodal ecosystem, one that requires a fundamentally different approach to YouTube SEO than the metadata-first strategies of the mobile-first era:
Key Moments & Search: YouTube chapters are no longer just navigational; they power 'Key Moments' in Google Search, allowing timestamped segments to rank as independent results.
Structured Data (JSON-LD): Implementing VideoObject schema—including Clip and SeekToAction properties—enables rich results like video carousels and featured snippets. For brands embedding these videos, this creates a 'Dual Ranking' effect where the page and the video both occupy premium SERP real estate.
AI-Era Optimization: The critical shift for 2026 is that while AI models like Gemini and GPT-4 are now multimodal (capable of processing frames and audio), they prioritize efficiency. They 'understand' video primarily by parsing the Transcript, Structured Metadata, and Captions.
The migration of YouTube to connected TV fundamentally changes how discoverability works. Long-form video is no longer competing only inside YouTube’s recommendation system, but across Google Search, AI Overviews, multimodal search engines, and living-room browsing interfaces.
Advanced Web Ranking helps you monitor this evolving visibility landscape across both traditional rankings and AI-generated discovery experiences.
Try AWR free to understand how your video content appears across modern search environments.
The Bottom Line for 2026
AI search engines do not just 'watch' but they extract.
A video’s spoken script is now a strategic search asset; if a brand’s transcript is clear, keyword-rich, and human-verified, it becomes the primary source for AI Overviews and generative answers.
In this 'Search-without-Clicks' era, the visible text and metadata are the only way to ensure a brand is cited rather than just watched.
Conclusion
Three insights emerge from this synthesis that extend beyond summary.
First, the CTV migration does not simply make YouTube "more like television", but it creates a hybrid semiotic space where algorithmic distribution logic, participatory culture, and creator-economy incentive structures operate within a viewing context historically governed by broadcast and cinematic conventions. The result is a new grammar that borrows from cinema (composition, syntagmatics, narrative architecture) while remaining structurally distinct (retention editing, chapter navigation, paratextual sign systems, dual-screen attention splitting).
Second, the analytical frameworks most productive for this hybrid space are themselves hybrid. Neither pure film semiotics (Metz, Deleuze) nor pure social semiotics (Kress, van Leeuwen) adequately captures YouTube on CTV alone. The most generative approach combines Metz's syntagmatic taxonomy with YouTube's explicit chapter segmentation, Barthes's hermeneutic code with retention analytics, and Kress and van Leeuwen's compositional metafunction with platform-specific production conventions — treating each classical framework as a lens that illuminates specific aspects of a fundamentally new object.
Third, for brands and creators, the CTV shift demands a production value recalibration.
Content designed for the 6-inch screen at arm's length does not simply scale to the 65-inch screen at three meters.
Composition must exploit the full horizontal frame.
Text must be legible at distance. Audio must carry narrative independently of visual attention.
And the paratextual system — thumbnail, title, chapter structure — must function for lean-back, remote-control-mediated browsing in a discovery-oriented rather than search-oriented mode.
The creators and brands that understand this grammar will own the largest screen in the home. Those that do not will be producing mobile content on a television, and visible in every pixel of their compositional compression.

Article by
Gianluca Fiorelli
With almost 20 years of experience in web marketing, Gianluca Fiorelli is a Strategic and International SEO Consultant who helps businesses improve their visibility and performance on organic search. Gianluca collaborated with clients from various industries and regions, such as Glassdoor, Idealista, Rastreator.com, Outsystems, Chess.com, SIXT Ride, Vegetables by Bayer, Visit California, Gamepix, James Edition and many others.
A very active member of the SEO community, Gianluca daily shares his insights and best practices on SEO, content, Search marketing strategy and the evolution of Search on social media channels such as X, Bluesky and LinkedIn and through the blog on his website: IloveSEO.net.



