
Every video you publish is a sign-system. Every cut, every composition choice, every sound and thumbnail encodes meaning through structures that semioticians mapped decades before TikTok existed.
Most video marketers treat these structures as intuition and something creative people "just feel."
That worked when production was expensive. It does not work when Veo 3.1 and Runway Gen-4.5 let anyone generate cinema-grade footage from a text prompt, and the only differentiator left is whether you understand the grammar of what you're making.
This two-part series (accompanied by a glossary) applies film semiotics, multimodal discourse analysis, and narrative semiotics to the video formats dominating digital marketing.
Part one dissects the semiotic grammar of short-form vertical video — TikTok, Reels, Shorts — and builds a content creation framework that extends directly to AI video generation.
Part two (publishing soon) moves to the living room: mid-to-long form YouTube on connected TV, where the migration to the biggest screen in the house restores classical horizontal composition and demands a production grammar most brands have not yet learned.
The theoretical foundations — Metz, Greimas, Barthes, Kress and van Leeuwen, Deleuze — are the same across both.
What changes is how they manifest when the canvas shifts from a phone held vertically at arm's length to a 65-inch screen three meters away. That difference is not cosmetic. It is grammatical.
Part 1: The semiotic grammar of short-form video: a framework for enterprise marketers
Classical semiotics — the formal study of signs and meaning-making — provides the most rigorous and underutilized strategic framework available to enterprise video marketers navigating TikTok, Reels, and Shorts.
While most brands still approach short-form video through intuition and trend-chasing, the theoretical architecture built by Metz, Greimas, Kress, van Leeuwen, Barthes, and Deleuze maps with startling precision onto the compositional, narrative, and engagement decisions that determine whether a 15-second video drives revenue or disappears into the scroll.
This matters now more than ever because generative AI video tools — Veo 3.1, Runway Gen-4.5, Kling 3.0, Pika 2.5 — have made production trivially easy, shifting the competitive advantage from making video to encoding meaning into video.
Semiotic literacy is not an academic luxury; it is becoming the primary skill that separates sophisticated brand storytelling from noise, and in this guide I will synthesize three theoretical domains and three practical application areas into a unified framework.
It draws on academic research from 2020–2026 — including Grzenkowicz and Wildfeuer's multi-level TikTok annotation scheme (2025), Cusnir's semiotic technology analysis of TikTok's interface (2025), and the first pilot studies on micro-narratives across platforms, alongside practitioner frameworks from commercial semioticians like Laura Oswald, Malcolm Evans, and Alex Gordon.
The goal is a working system that enterprise teams can deploy immediately while AI video generation reshapes the entire production landscape.
Film semiotics reveals the hidden editing grammar of every TikTok
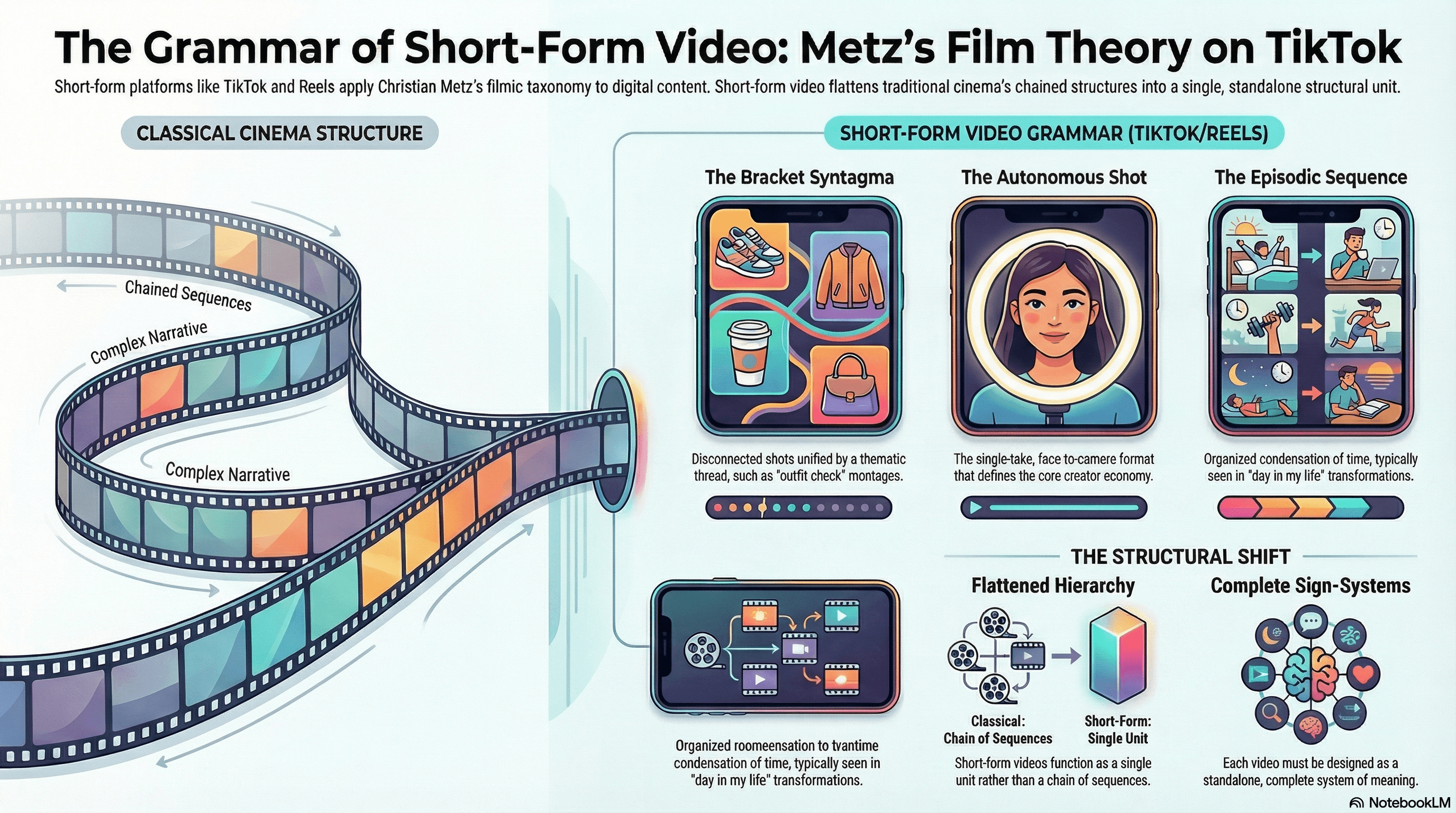
Christian Metz's grande syntagmatique, published in 1966 and expanded in Film Language: A Semiotics of Cinema (1974), identified eight autonomous segment types that constitute the deep structure of narrative cinema.
These range from the autonomous shot (a single continuous take conveying a complete narrative unit) to complex constructions like the alternating syntagma (cross-cutting between simultaneous events) and the episodic sequence (condensing extended time into a montage).
Metz argued that films build meaning through specific combinations of these segment types, which are a grammar of editing as structured and rule-governed as verbal language.
No published academic work has directly applied Metz's taxonomy to TikTok, Reels, or Shorts, being this a significant gap that represents a genuine opportunity for original contribution.
However, the mapping is both natural and revealing.
The bracket syntagma — defined by Metz as "a series of very brief scenes" with no temporal or spatial relationships, unified by a thematic "common thread" — is arguably the dominant complex syntagmatic type on TikTok.
Every "outfit check" montage, "things I love about" compilation, and "aesthetic" mood reel operates as a bracket syntagma: disconnected shots bound by conceptual rather than narrative logic.
The autonomous shot maps directly to the single-take face-to-camera format that launched TikTok's creator economy.
The episodic sequence — Metz's term for organized condensation of diegetic time, exemplified by the breakfast montage in Citizen Kane — finds its short-form equivalent in "day in my life" and before/after transformation content.
What the compressed format fundamentally changes is the syntagmatic hierarchy itself.
Where cinema builds sequences from combinations of syntagmatic types, a single short-form video typically is one syntagmatic unit rather than a chain of them.
The grammar flattens: deep structure becomes surface structure.
This insight has direct strategic implications, because it means each video must be designed as a single, complete sign-system rather than a segment within a larger flow.
Gilles Deleuze's philosophical cinema taxonomy offers an equally productive lens. His movement-image — subdivided into perception-images, affection-images, and action-images — maps with remarkable precision onto short-form content categories.
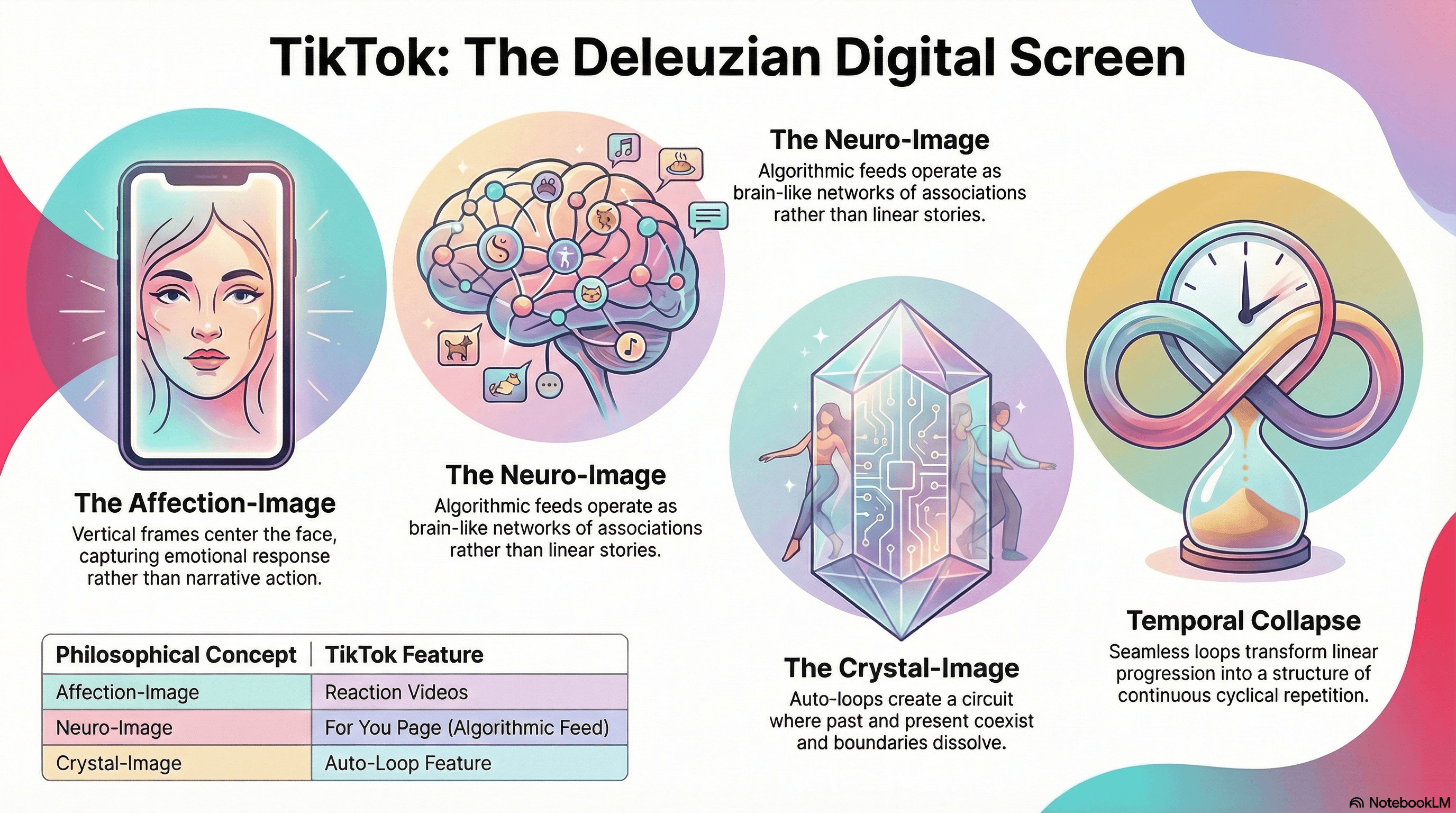
The affection-image, which Deleuze defined as the close-up of the face expressing pure potential and quality before action is taken, is the dominant image-type of TikTok. The vertical frame centers the face as its primary visual unit; reaction videos are pure affection-image, aka the registration of emotional response without narrative action.
Generating semiotically sophisticated video content is only half the equation. The other half is understanding whether those narrative and compositional choices actually translate into discoverability.
Advanced Web Ranking helps you connect creative experimentation with measurable ranking and AI visibility outcomes across search ecosystems.
Start a free trial and track how your AI-assisted video content strategies perform in real search environments.
Patricia Pisters extended Deleuze's framework with the concept of the "neuro-image" (The Neuro-Image, Stanford UP, 2012), arguing that digital screen culture creates a third image type where viewers move through mental landscapes and database logic rather than linear narrative.
TikTok's algorithmic feed — a brain-like network of associations served by recommendation engines — operates closer to Pisters's neuro-image than to either of Deleuze's original categories.
Perhaps most intriguing is how TikTok's auto-loop creates what Deleuze would recognize as a crystal-image, aka the point where actual and virtual become indiscernible, where past and present coexist in a circuit.
When a video seamlessly loops, its temporal boundaries dissolve. The ending becomes the beginning, linear time collapses into cyclical repetition.
This is not merely a platform feature but a genuinely novel temporal structure that Deleuze's framework helps us theorize and, crucially, design for.
Vertical video reorganizes the entire grammar of visual composition
Gunther Kress and Theo van Leeuwen's Reading Images: The Grammar of Visual Design (1996, 3rd ed. 2020) established that visual composition communicates through three interrelated systems:
Information value (where elements are placed).
Salience (what attracts attention).
Framing (what connects or separates elements).
Their framework, built on Halliday's Systemic Functional Linguistics, treats images as structured meaning-making systems governed by grammar-like rules, and not random aesthetic choices.
The shift from 16:9 horizontal to 9:16 vertical fundamentally reorganizes how these systems operate.
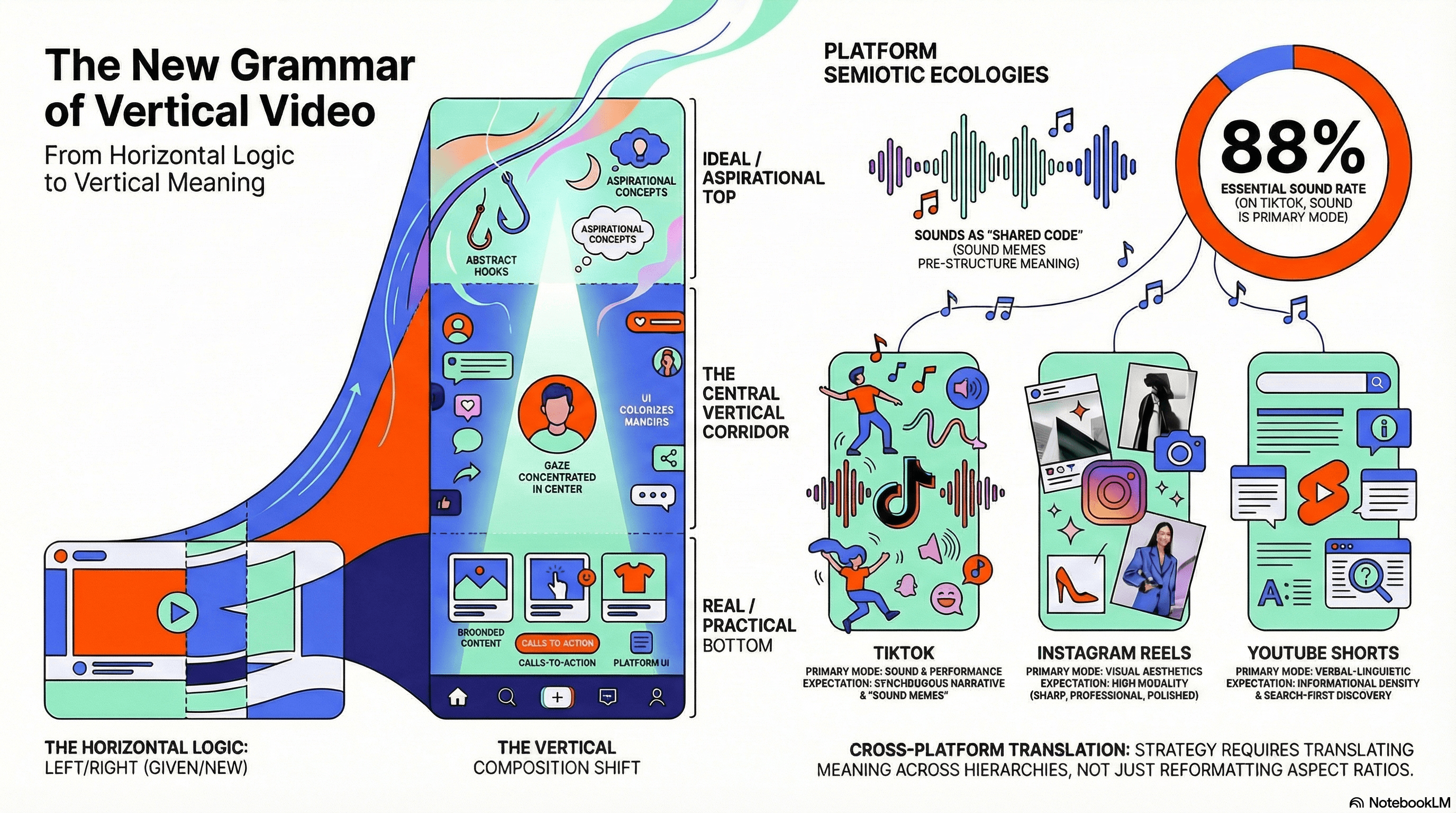
Kress and van Leeuwen's Given/New axis (left = familiar, agreed-upon; right = unfamiliar, requiring attention) loses much of its communicative power in a narrow vertical frame.
There simply is not enough horizontal space to establish meaningful left/right polarity.
Instead, the Ideal/Real axis (top = aspirational, abstract; bottom = specific, practical, grounded) becomes dominant.
The vertical frame's upper third becomes prime territory for "Ideal" content — aspirational hooks, contextual text overlays, brand messaging — while the lower third is occupied by "Real" content and, critically, colonized by platform UI elements (usernames, captions, interaction buttons).
The Centre/Margin structure intensifies as the narrow frame concentrates attention on a central vertical corridor, with platform chrome creating a forced margin around creator content.
Herasymiuk's 2025 study in The American Journal of Engineering and Technology confirmed this empirically, finding that "the central vertical axis of the frame serves as the path of least resistance for gaze and interaction" and that "vertical split-screen significantly increases retention."
For enterprise video teams, this means composition decisions in vertical video are not aesthetic preferences, but semiotic choices that position meaning along the Ideal/Real axis and must account for platform UI as part of the compositional grammar.
The interaction between semiotic modes in short-form video creates meaning through what Terry Royce termed intersemiotic complementarity or, in other words, modes that "complement each other in the ways that they project meaning."
On TikTok, this takes a distinctive form. Text overlays function as a semi-independent semiotic layer that often provides narrative commentary, ironic counterpoint, or contextual framing that cannot be derived from the visual alone. This creates synchronous intersemiotic relations where text, image, and sound operate simultaneously within the video stream.
Contrast this with YouTube's thumbnail-plus-title system, which creates asynchronous intersemiotic relations: a static multimodal composition functioning as a paratextual "promise" that precedes the video itself.
Trending sounds on TikTok, then, represent an entirely novel semiotic phenomenon.
A sound clip carries meaning accumulated across thousands of prior uses, becoming what researchers have called "sound memes."
When a creator uses "Oh No" by The Shangri-Las, they invoke a semiotic template where the visual content must depict something going wrong.
The sound pre-structures the video's meaning.
This is Saussurean langue in action; a shared code system that constrains and enables individual expression.
As Dr. Lena Patel of NYU observed, "if a sound makes people laugh, cry, or cringe in unison, it becomes a social signal." For brands, choosing a trending sound is not a creative whim but a semiotic commitment that aligns content with an existing field of meaning.
Generating semiotically sophisticated video content is only half the equation. The other half is understanding whether those narrative and compositional choices actually translate into discoverability.
Advanced Web Ranking helps you connect creative experimentation with measurable ranking and AI visibility outcomes across search ecosystems.
Start a free trial and track how your AI-assisted video content strategies perform in real search environments.
Kress's concept of modal affordance — "the potentials and limitations of specific modes for the purposes of making signs" — helps explain why the same brand message requires fundamentally different semiotic strategies on each platform.
TikTok privileges sound and bodily performance, with its 88% of users reporting sound as essential.
Instagram Reels privileges visual aesthetics inherited from its photo-sharing heritage, where high modality markers (sharp, professionally lit, color-coordinated) are semiotically expected.
YouTube Shorts privileges informational density and verbal-linguistic modes, given its search-first discovery architecture.
Each platform constitutes a distinct semiotic ecology with its own modal hierarchies, and effective cross-platform strategy requires translating meaning across these ecologies rather than simply reformatting the same content.
Greimas provides the narrative architecture that hooks and holds attention
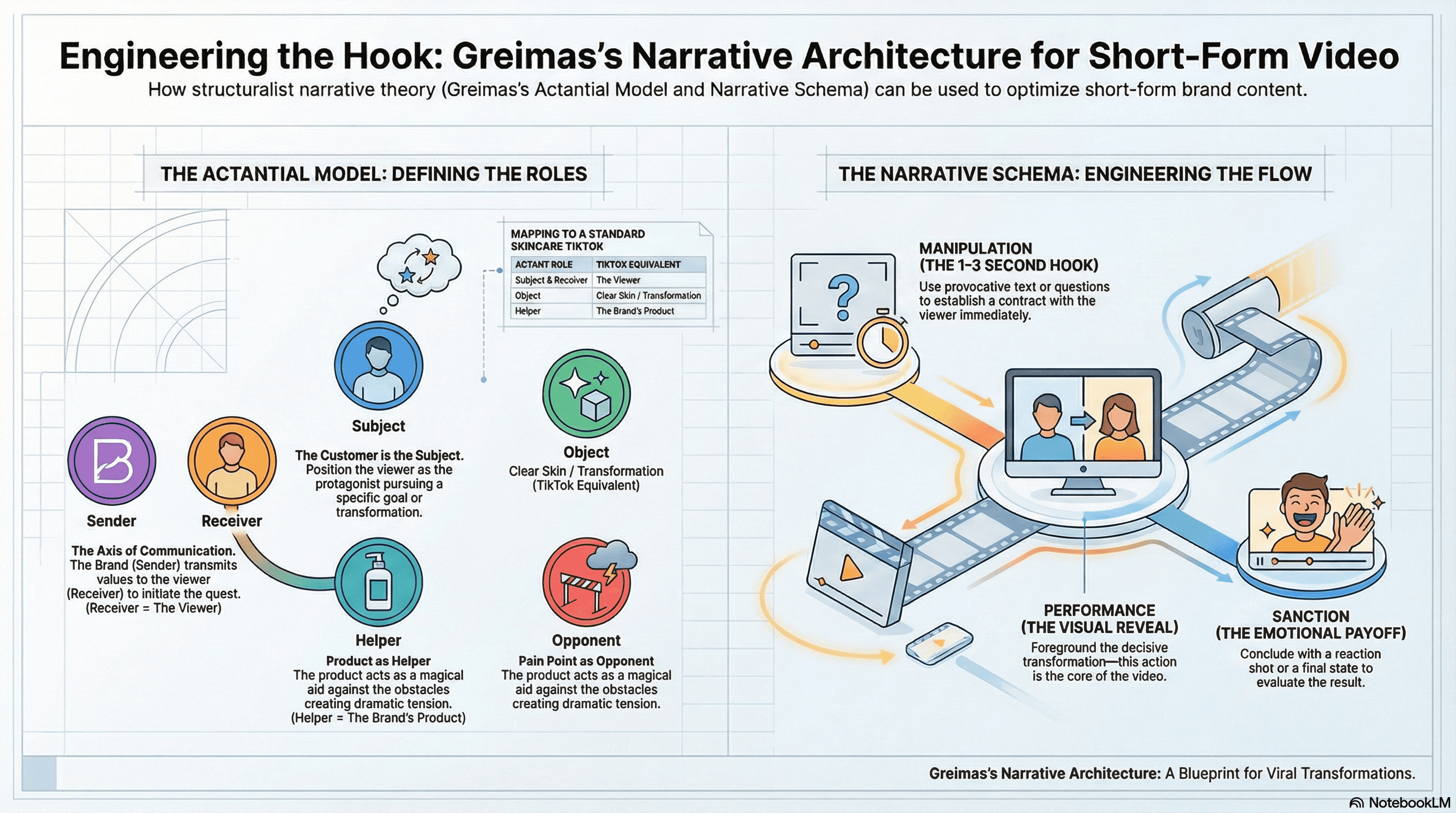
A.J. Greimas's actantial model, developed in Sémantique structurale (1966), identifies six functional roles organized along three binary axes:
The axis of desire (Subject pursuing Object).
The axis of power (Helper versus Opponent).
The axis of communication (Sender transmitting to Receiver).
This is not character theory but the deep syntax of narrative itself, and it maps onto brand storytelling with surgical precision.
In short-form video brand content, the most effective mapping positions the customer as Subject (the protagonist with a desire), the product or service as Helper (the magical aid enabling success), the customer's goal as Object (the transformation or solution they seek), the brand as Sender (communicating values and initiating the quest), and the pain point or competitor as Opponent (the obstacle creating dramatic tension).
A 30-second skincare TikTok implicitly deploys all six actants:
The viewer (1: Subject) wants clear skin (2: Object).
Acne or sensitivity (3: Opponent) blocks them
The brand (4: Sender) introduces its product (5: Helper).
The viewer (also 6: Receiver) experiences the transformation shown in the before/after reveal.
Understanding this structure allows enterprise teams to diagnose exactly why certain content underperforms, often because actants are misconfigured, typically by placing the brand as Subject rather than Helper.
Greimas's canonical narrative schema describes how these actants move through four phases:
Manipulation (establishing the contract/desire).
Competence (acquiring the means to act).
Performance (the decisive transformation).
Sanction (evaluation of the result).
Generating semiotically sophisticated video content is only half the equation. The other half is understanding whether those narrative and compositional choices actually translate into discoverability.
Advanced Web Ranking helps you connect creative experimentation with measurable ranking and AI visibility outcomes across search ecosystems.
Start a free trial and track how your AI-assisted video content strategies perform in real search environments.
In 15–60 second video, these phases undergo radical compression.
Manipulation compresses into the first 1–3 seconds: the “hook.” A text overlay reading "You've been doing this wrong" or a provocative opening question establishes the contract in its most efficient possible form.
Competence is typically implied or shown retrospectively; tutorial content foregrounds it, but most viral content skips or abbreviates it.
Performance is almost always foregrounded, aka it’s the dramatic transformation, the decisive action, the visual reveal is the video.
Sanction compresses into immediate emotional payoff (the reaction shot, the final state, the call to action.)
Many viral formats invert the entire schema, opening with sanction (showing the result) and looping back through performance, exploiting curiosity to drive watch-through.
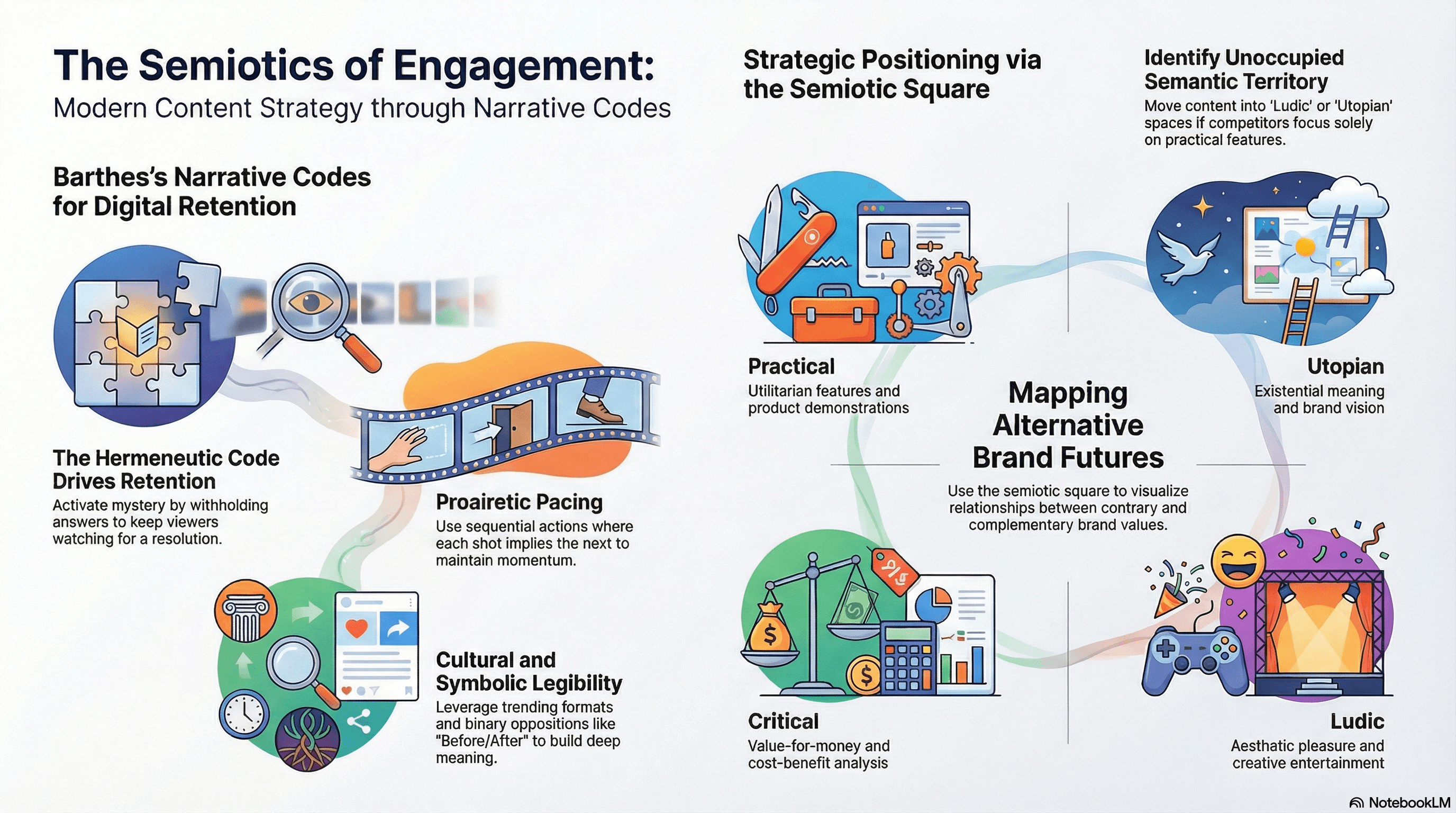
Roland Barthes's five narrative codes from S/Z (1970) provide a complementary engagement framework.
The hermeneutic code — elements that create mystery, pose questions, withhold answers — is the single most powerful driver of watch-time retention. Every "wait for it" video, every opening that shows an unexplained result, every text overlay posing a question without immediate resolution activates the hermeneutic code.
The proairetic code (sequential actions implying consequences) governs pacing, which means that each shot must imply the next to maintain momentum within the 2–3 second editing rhythm that TikTok's attention economy demands.
The cultural/referential code (shared cultural knowledge) explains why trend participation works: using a trending format activates shared interpretive frames that ensure legibility and reward algorithmic distribution.
The symbolic code (binary oppositions) structures the deeper meaning of transformation content — before/after, chaos/order, constraint/freedom — and the semic code (connotative associations) builds brand personality through lighting choices, color palettes, and environmental details without ever stating them explicitly.
Greimas's semiotic square — mapping contrary, contradictory, and complementary relationships within a semantic field — becomes a strategic planning tool when applied to content positioning.
Jean-Marie Floch's four axiologies of consumption, derived from the semiotic square, map practical valuation (utilitarian features) against utopian valuation (existential meaning), generating four consumer value orientations:
Practical.
Utopian.
Critical (value-for-money).
Ludic (aesthetic pleasure).
If competitors cluster in the "practical" corner with feature-demonstration videos, the semiotic square reveals the "ludic" or "utopian" positions as unoccupied semantic territory for differentiated content.
George Rossolatos's 2012 paper in Signs demonstrated that the square functions as "a dynamic modeling device" for "envisioning alternative brand futures", aka not merely analyzing current positioning but identifying where meaning can move.
How to conduct a semiotic audit of your brand's video presence
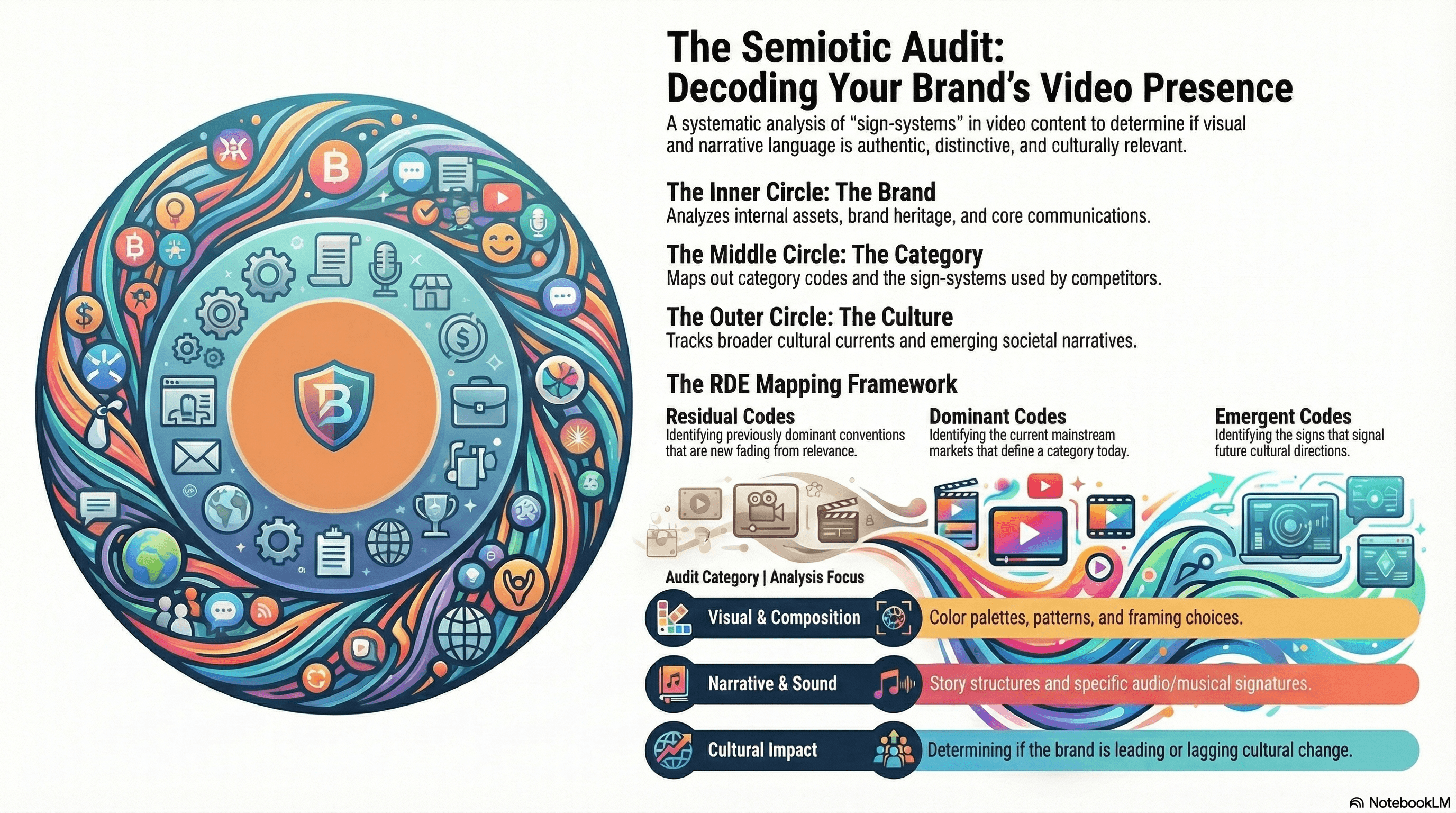
The transition from theory to practice begins with the semiotic audit: a systematic analysis of the sign-systems deployed across a brand's video content.
Commercial semioticians use a concentric circles model described by both Rob Thomas (Practical Semiotics) and Alex Gordon (Sign Salad):
The inner circle examines the brand itself (its assets, heritage, communication).
The middle circle maps the category and competitors (category codes, competitor sign-systems).
The outer circle reads broader culture (emerging cultural currents, societal narratives).
The audit evaluates whether the brand's sign-system is authentic to itself, distinctive from competition, and culturally relevant.
Malcolm Evans, the pioneer who introduced commercial semiotics to market research in 1988, created the Residual, Dominant, Emergent (RDE) mapping framework, which is now the most widely used tool in the field:
Residual codes are previously dominant conventions now fading from cultural relevance.
Dominant codes represent the mainstream markers of a category today.
Emergent codes signal future directions.
For video content, this means systematically cataloguing where a brand's visual language, narrative structures, sound choices, and compositional patterns sit on this continuum, and identifying whether they are leading cultural change or lagging behind it.
Evans's work for Guinness UDV produced a set of 28 universal drinks codes distilled into a card pack, enabling local marketing teams worldwide to decode competitive advertising and identify white spaces. The project won the MRS Paper of the Year Award.
Laura Oswald, founder of Marketing Semiotics LLC and author of Marketing Semiotics: Signs, Strategies, and Brand Value (Oxford University Press, 2012), identifies three brand identities that must be audited:
Visual identity.
Verbal identity.
Behavioral identity.
Her analysis of an instant coffee brand revealed that its advertising mixed codes from mass-market brands (casual social gatherings), luxury brands (pleasure-focused imagery), and gourmet brands (solo connoisseur drinking), resulting in semiotic incoherence that confused consumers and weakened brand equity.
This same diagnostic applies directly to video content: brands whose TikTok presence mixes incompatible semiotic registers (e.g., lo-fi authenticity codes in one video, polished luxury codes in the next, without strategic intent) create the kind of "nail on a blackboard" tension Oswald describes.

The competitive dimension of semiotic analysis maps how different brands within a category deploy sign-systems.
Each platform adds a layer of complexity because platform-specific semiotic conventions function as additional codes that brands must navigate.
TikTok's dominant code privileges low modality markers — unfiltered, handheld, natural lighting — as signs of authenticity.
A smartphone video filmed in a laundry room carries more cultural weight on TikTok than a million-dollar studio production because imperfection indexes honesty. Instagram Reels inherits an aesthetic-first visual grammar from its photo-sharing heritage, where high production value and color coordination are semiotically expected.
YouTube Shorts privileges informational substance within a search-driven discovery framework where titles, descriptions, and tags function as a paratextual semiotic layer largely absent from TikTok and Reels.
Platform-native features constitute their own semiotic resources.
TikTok's Duet creates a dialogic sign where meaning emerges from the relationship between two videos playing simultaneously, and where the original becomes a "text" that the new video "reads" in real-time.
Stitch creates an intertextual sign, where the original clip becomes a premise that new content extends, contradicts, or recontextualizes.
Green Screen superimposes the creator over another image or video, establishing a commentary frame where the creator literally stands "in front of" evidence being decoded.
These are not merely features; they are meaning-making tools with specific semiotic affordances that brands must learn to deploy as fluently as they deploy camera angles and lighting.
Generating semiotically sophisticated video content is only half the equation. The other half is understanding whether those narrative and compositional choices actually translate into discoverability.
Advanced Web Ranking helps you connect creative experimentation with measurable ranking and AI visibility outcomes across search ecosystems.
Start a free trial and track how your AI-assisted video content strategies perform in real search environments.
The semiotic content creation framework: from theory to production decisions
The practical framework integrates all three theoretical domains into a four-layer system that translates semiotic theory into actionable content creation and, critically, extends directly to AI video generation.
Each layer addresses a different dimension of meaning-making, and each one maps to specific decisions that content creators and AI prompt engineers must make.
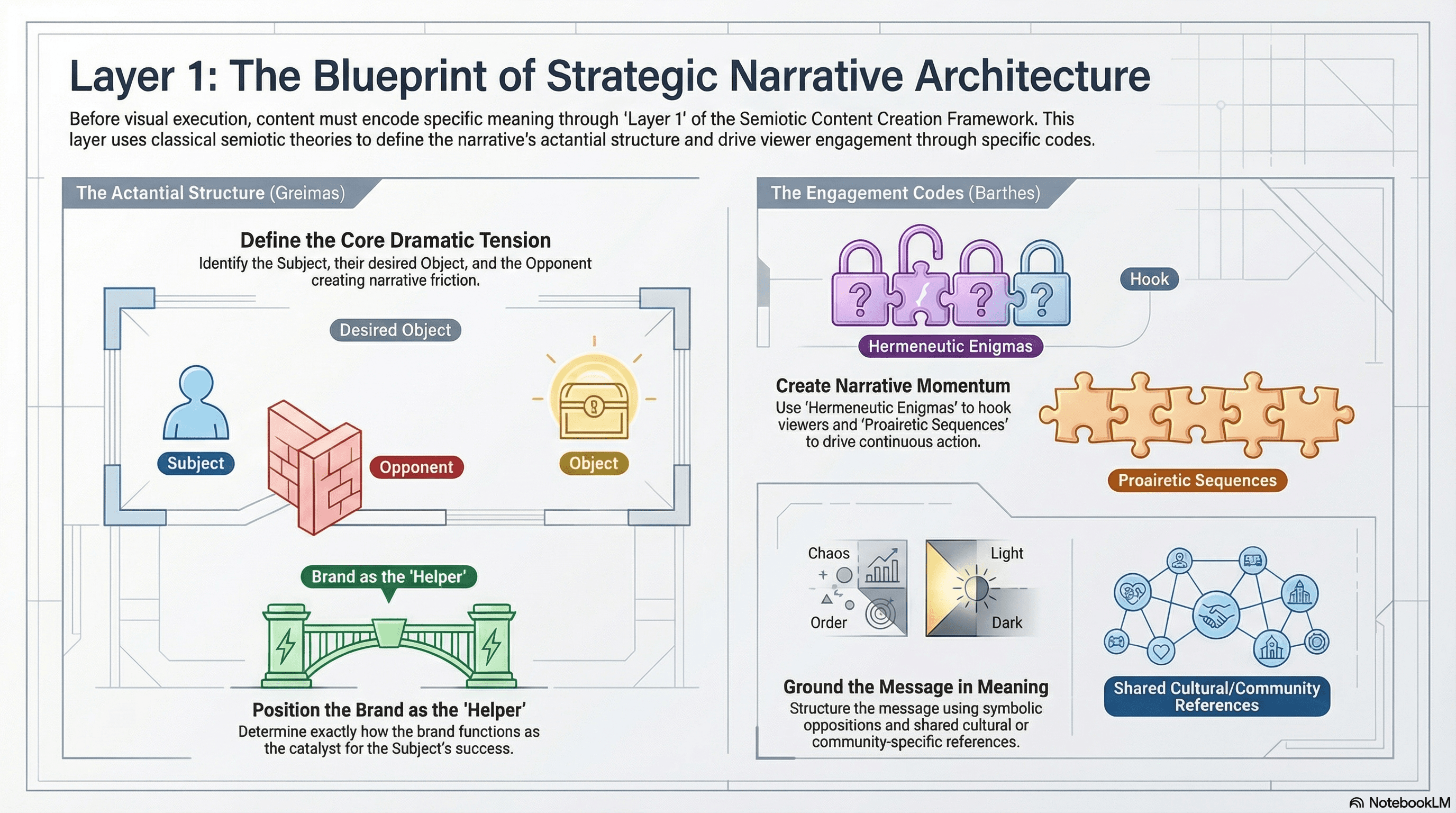
Layer 1 — Strategic narrative architecture (Greimas + Barthes)
Before any visual decisions, define the actantial structure:
Who is the Subject?
What Object do they desire?
What Opponent creates tension?
How does the brand function as Helper?
Then design engagement through Barthes's codes:
What hermeneutic enigma opens the video (the visual mystery or question that prevents swiping)?
What proairetic sequence drives forward momentum (each shot implying a next action)?
What symbolic opposition structures the underlying message (before/after, constraint/freedom, chaos/order)?
What cultural references ground the content in shared knowledge (trending formats, seasonal markers, community-specific language)?
This layer determines what meaning the video encodes before addressing how it looks.
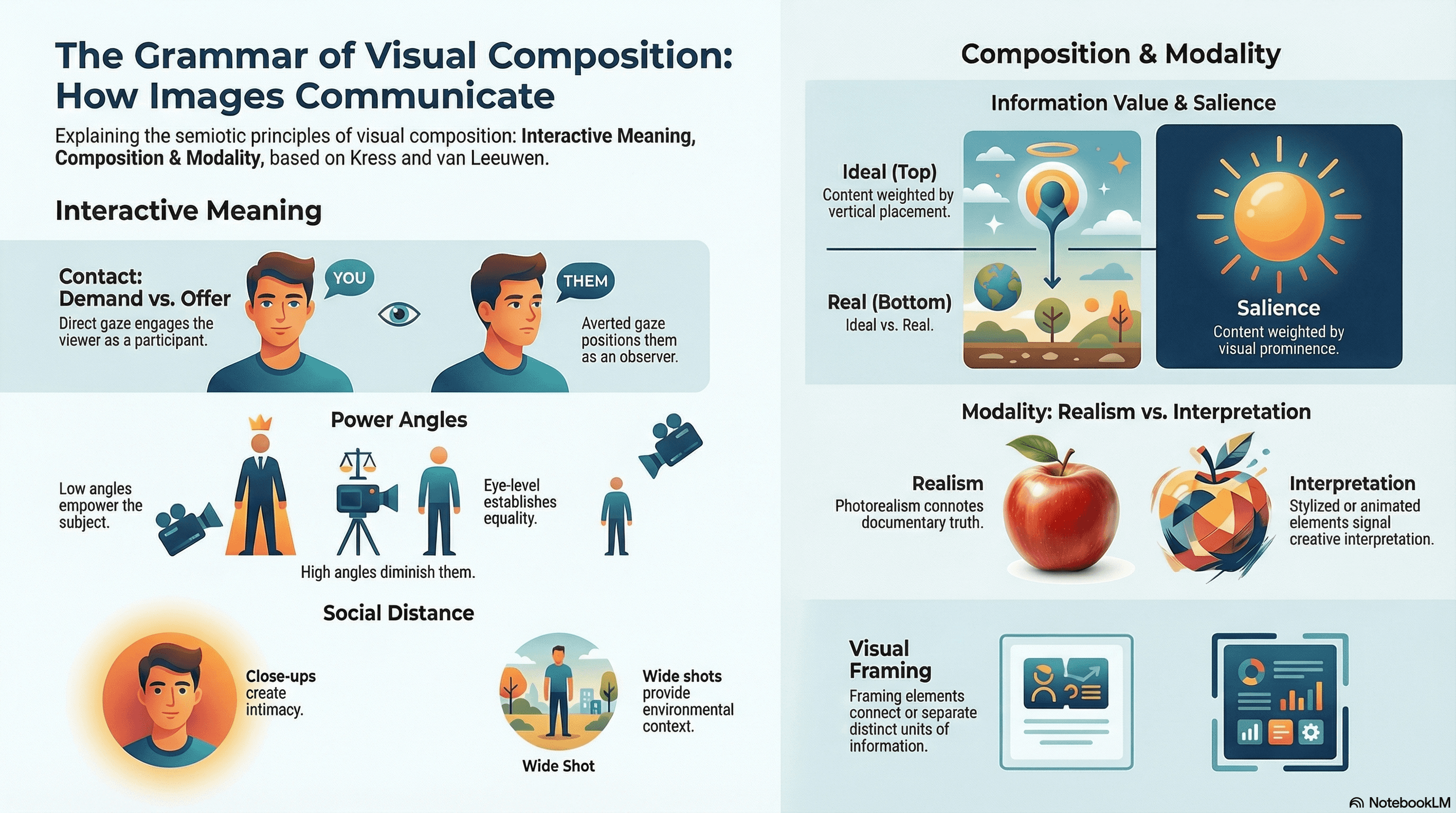
Layer 2 — Visual composition grammar (Kress and van Leeuwen)
For each shot, specify the interactive meaning through:
Social distance (close-up for intimacy, wide shot for context).
Contact type (direct gaze into camera creates "demand" — engaging the viewer as participant; averted gaze creates "offer" — positioning the viewer as observer).
Power angle (low angle empowers the subject; high angle diminishes; eye-level establishes equality).
Then specify compositional meaning through:
Information value (what occupies the Ideal zone at the top of the vertical frame versus the Real zone at the bottom).
Salience (what demands attention through size, contrast, sharpness, color).
Framing (what visual elements connect or separate informational units).
Finally, determine modality aka the degree of realism the content signals:
High modality (photorealistic, detailed, naturalistic lighting) connotes documentary truth.
Reduced modality (stylized color grading, graphic overlays, animated elements) connotes creative interpretation.
Each of these choices carries semiotic weight whether or not the creator is conscious of it.
Layer 3 — Sequential editing logic (Metz)
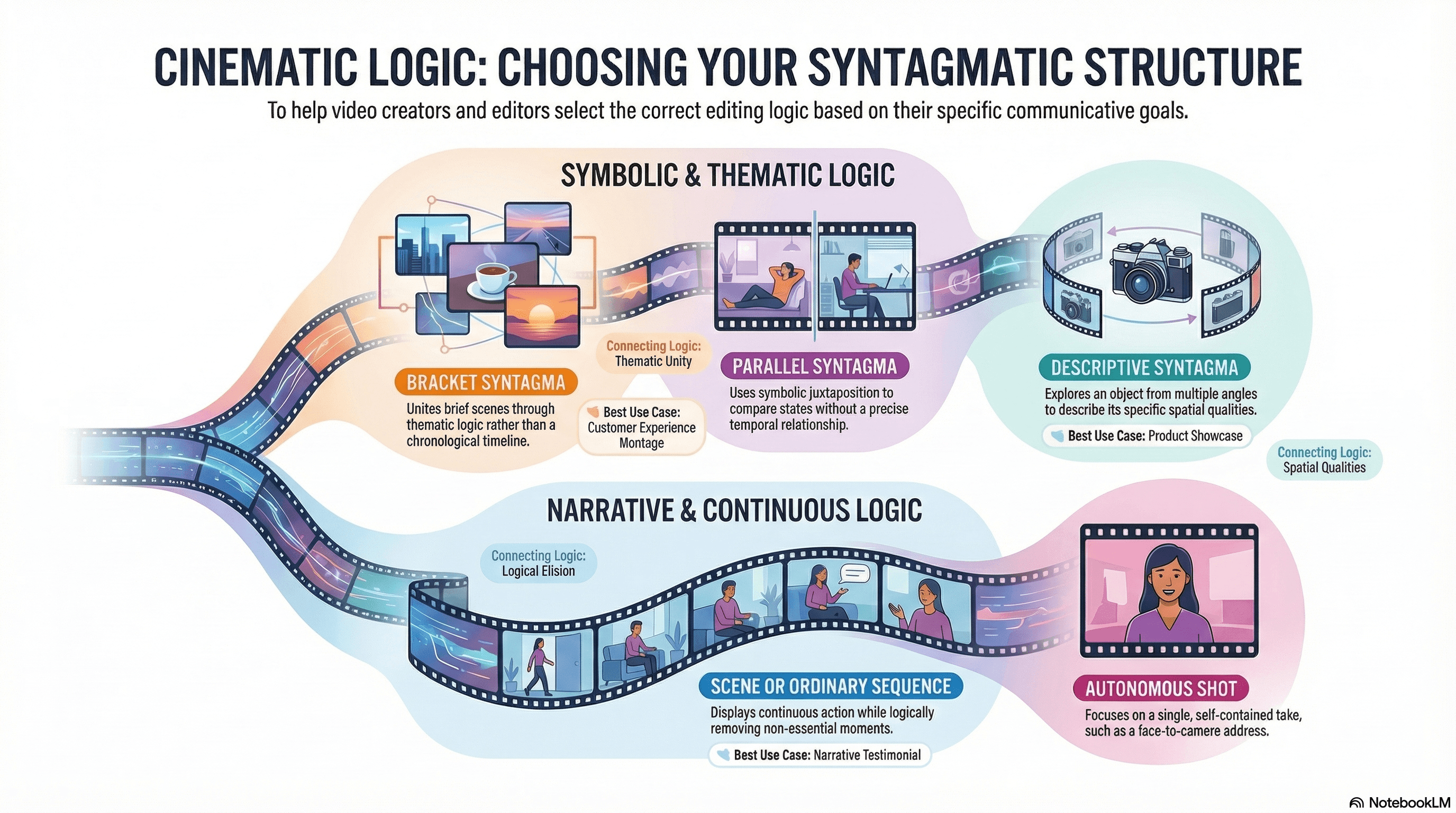
Choose the syntagmatic type that matches the content's communicative purpose.
A product showcase operates as a descriptive syntagma (the same object from multiple angles, describing spatial qualities).
A montage of customer experiences operates as a bracket syntagma (brief scenes united by thematic rather than temporal logic).
A narrative testimonial operates as a scene or ordinary sequence (continuous action with logical elision of non-essential moments).
A comparison between old and new states operates as a parallel syntagma (symbolic juxtaposition without precise temporal relationship).
A single face-to-camera take operates as an autonomous shot.
This choice determines not just editing rhythm but the fundamental logic connecting shots, and different syntagmatic types create fundamentally different viewing experiences.
Layer 4 — Sign inventory (Peirce)
For each visual element, determine whether it functions as:
An icon (signifying through resemblance; literally showing what it represents).
An index (signifying through causal or contextual connection — steam indicating heat, shadows indicating time of day, tears indicating emotion)
A symbol (signifying through convention — a wedding ring meaning commitment, a clock meaning urgency, specific colors carrying culturally learned associations).
The sign inventory ensures every visual element carries intentional meaning and that no semiotic resources are wasted in the compressed timeframe.

AI video generation makes semiotic literacy the essential production skill
The convergence of this framework with generative AI video is not merely interesting, but it is structurally inevitable.
As of March 25, 2026, 4 tools have reached production viability:
Runway Gen-4.5 topped the Artificial Analysis benchmark with an Elo rating of 1,247, beating Google Veo 3.1 and Sora 2 (until it was available, offering cinema-grade realism plus in-video editing through text prompts via its Aleph feature.
Google Veo 3 / 3.1 — announced at Google I/O in May 2025 and updated to 3.1 in October 2025 — is the first major model to natively generate synchronized audio alongside video: dialogue, ambient soundscapes, and sound effects produced in a single pass rather than layered in post-production. It outputs up to 4K resolution in both 16:9 and 9:16 formats, with an "Ingredients to Video" feature allowing up to three reference images for character and object consistency across shots. Available through the Gemini API, Google AI Studio, Vertex AI, and the filmmaking tool Flow.
Kling 3.0 from Kuaishou delivers 4K HDR at 48 FPS with physics simulation (gravity, fabric dynamics, fluid motion) and a Smart Storyboard feature for multi-shot continuity across 5–6 scenes.
Pika 2.5 focuses on creative effects and accessibility, with keyframe transitions, audio-driven face performance, and object manipulation tools designed for social content creation.
Veo 3 is particularly interesting because of the native audio generation, which is a strong semiotic differentiator, not just a technical one.
It means the tool generates intersemiotic relations (visual + audio coherence) natively rather than requiring the human to orchestrate them separately.
Generating semiotically sophisticated video content is only half the equation. The other half is understanding whether those narrative and compositional choices actually translate into discoverability.
Advanced Web Ranking helps you connect creative experimentation with measurable ranking and AI visibility outcomes across search ecosystems.
Start a free trial and track how your AI-assisted video content strategies perform in real search environments.
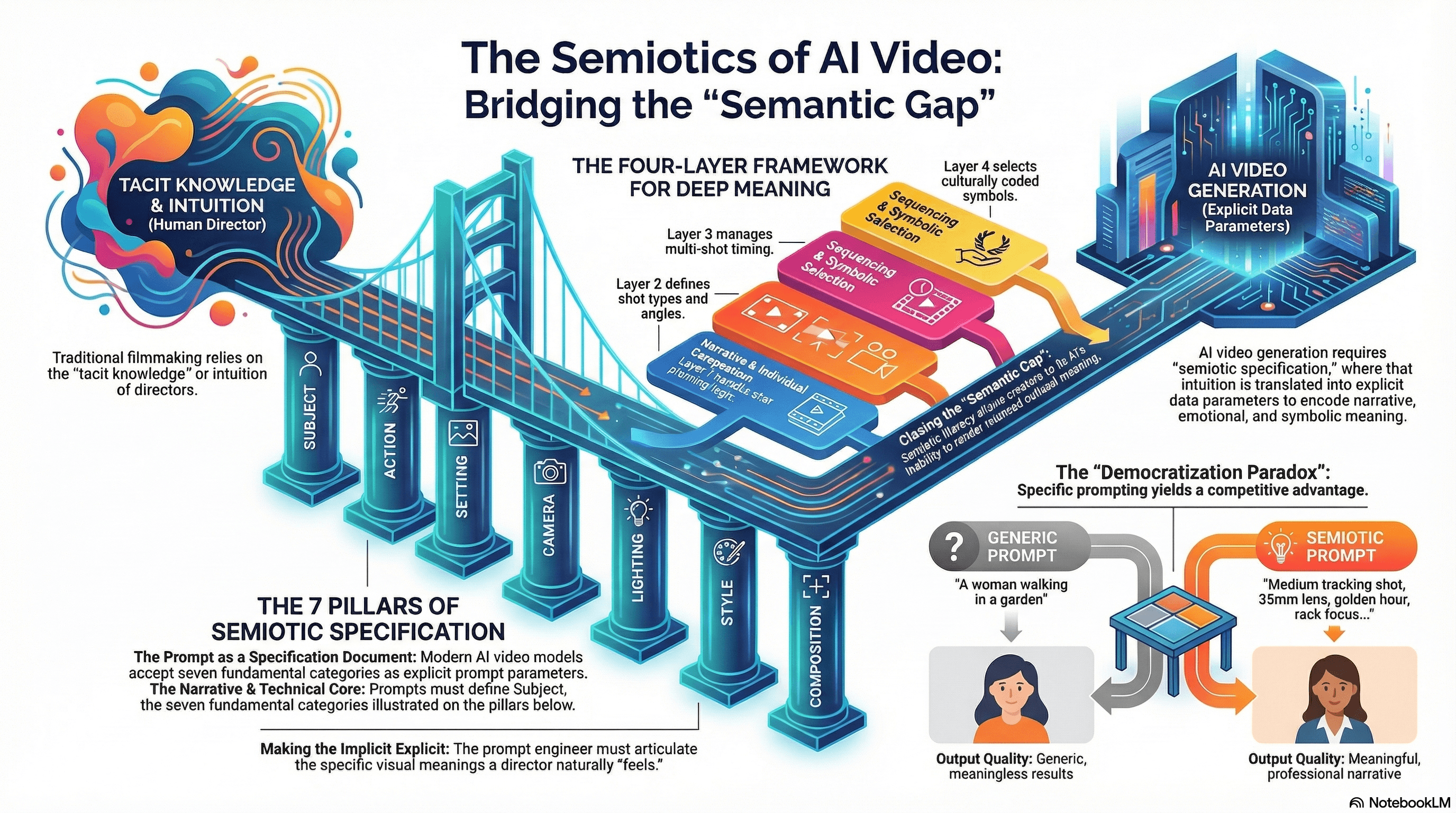
Every one of these tools accepts the same fundamental categories as prompt parameters:
Subject (who/what is in frame).
Action (what happens).
Setting (where and when).
Camera (shot type, movement, lens).
Lighting (quality, direction, color temperature).
Style (aesthetic register, color grading).
Composition (spatial relationships, foreground/background).
These prompt parameters are semiotic categories
A prompt is a semiotic specification document, which means it requires explicit articulation of visual meaning that traditional video production left to the tacit knowledge of directors and cinematographers.
The prompt engineer must articulate what the director felt. This is the fundamental semiotic operation: making implicit meaning explicit through signs.
The four-layer framework translates directly into prompt engineering:
Layer 1 (Greimas + Barthes) → Shot planning: The actantial structure determines what scenes need to exist and what narrative logic connects them. The hermeneutic code determines the opening shot's visual enigma. The symbolic code structures the contrast between scenes.
Layer 2 (Kress and van Leeuwen) → Individual prompt composition: Social distance becomes shot type specification ("close-up" = intimate). Power angle becomes camera angle ("low angle looking up" = subject authority). Contact type becomes gaze direction ("looking directly at camera" = demand/engagement). Modality becomes style keywords ("photorealistic, cinematic" versus "stylized, animated").
Layer 3 (Metz) → Multi-shot sequencing: The syntagmatic type determines whether to use consistent character references across prompts (scene/sequence) or thematically unified but visually disconnected prompts (bracket syntagma). It determines whether temporal cues connect shots (ordinary sequence) or symbolic juxtaposition does (parallel syntagma).
Layer 4 (Peirce) → Element selection: Icons are literal visual elements that resemble what they represent. Indices are environmental cues that point to meaning through causal connection (golden light = warmth, rain = melancholy). Symbols are culturally coded objects that carry conventional meaning (ladders = ambition, clocks = urgency).
Academic work is already formalizing this connection.
The FRESCO framework (Morra et al., 2024) bridges computer vision and visual semiotics by analyzing images across three semiotic levels:
The plastic level (fundamental visual features like lines and colors — mapping to prompt parameters like lighting and color grading).
The figurative level (specific entities and concepts — mapping to subject and object specifications).
The enunciation level (point of view and spectator construction — mapping to camera angle, framing, and composition).
A 2023 paper in PMC/NIH analyzed generative adversarial networks through Greimas's actantial framework itself, positioning the generator as an actant that "aims to make appear" (pass as true) while the discriminator "aims to unmask as false."
Oxford's AVLIF framework identified a critical "Semantic Gap" — AI's inability to render nuanced symbolic, cultural, and emotional meaning — that is precisely where semiotic literacy fills the void.
The democratization paradox is stark. When anyone can generate professional-looking video for pennies, surface-level prompts ("a woman walking in a garden") produce generic, meaningless results.
Semiotically sophisticated prompts ("medium tracking shot of a woman in a flowing red dress walking through a sunlit Victorian garden, 35mm lens, golden hour lighting, shallow depth of field, rack focus from foreground flowers to her contemplative expression") produce content that encodes specific meaning at every level: compositional, narrative, emotional, and symbolic.
The gap between these two prompts is semiotic literacy, and it is the only sustainable competitive advantage in an era of zero-cost production.
Connecting semiotic coherence to discoverability and algorithm performance
For enterprise SEOs, the semiotic framework connects directly to discoverability mechanics.
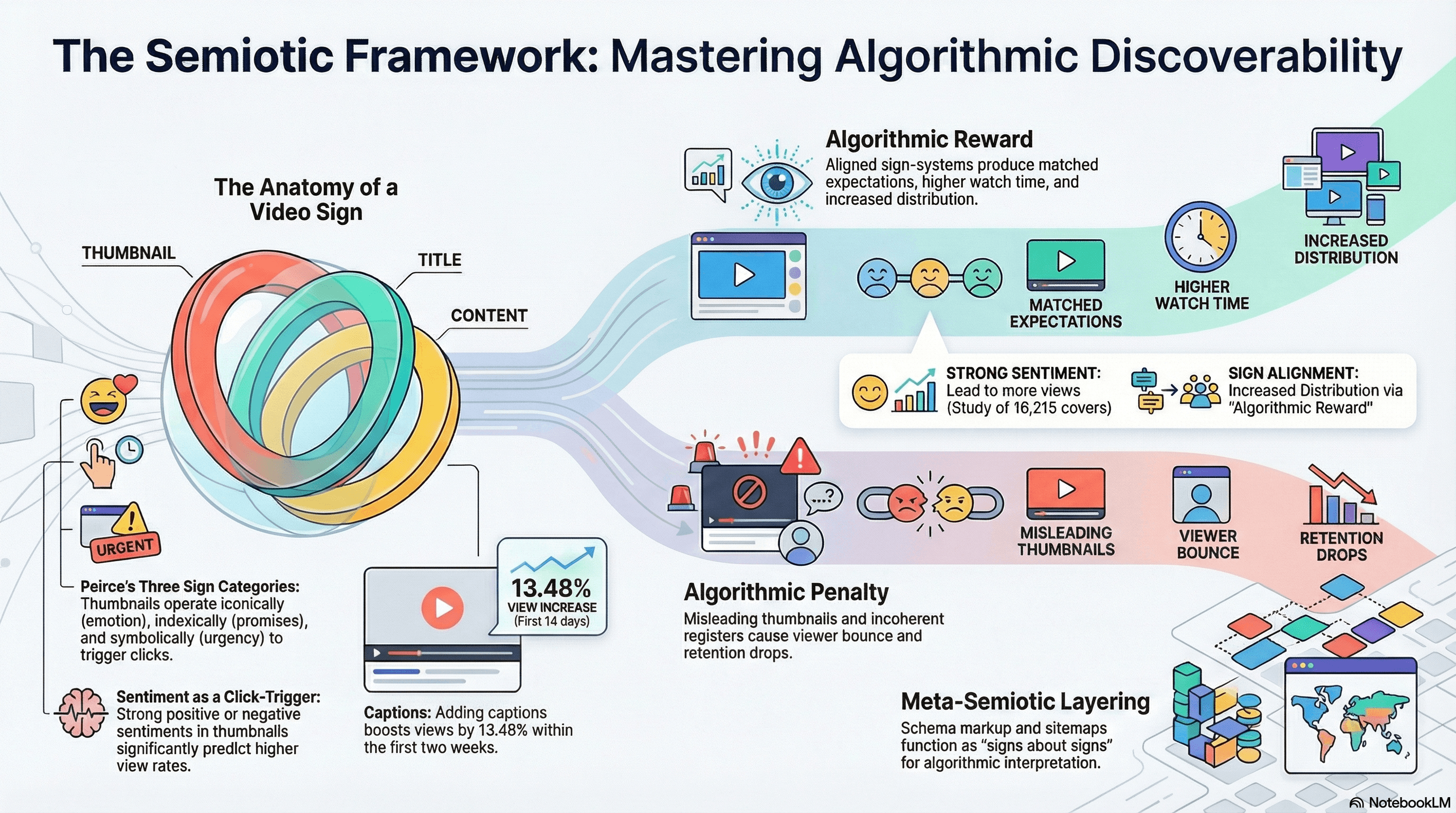
YouTube thumbnails function as complex multimodal signs operating across all three of Peirce's categories simultaneously: iconically (a face expressing surprise = emotional content), indexically (a before/after comparison = transformation promise), and symbolically (red text = urgency, question marks = curiosity gap).
Research analyzing 3,745 marketing videos found that thumbnail design elements significantly predicted view-through rates, while a study of 16,215 YouTube video covers confirmed that "strong sentiments in thumbnails, whether positive or negative, lead to more views". In other words, emotional signs in thumbnails function as click-triggers.
Generating semiotically sophisticated video content is only half the equation. The other half is understanding whether those narrative and compositional choices actually translate into discoverability.
Advanced Web Ranking helps you connect creative experimentation with measurable ranking and AI visibility outcomes across search ecosystems.
Start a free trial and track how your AI-assisted video content strategies perform in real search environments.
More fundamentally, semiotic coherence — the alignment between thumbnail, title, and video content — directly drives the algorithm signals that determine distribution.
A coherent sign-system where thumbnail promises match content delivery produces matched viewer expectations, higher watch time, and algorithmic reward.
An incoherent sign-system (misleading thumbnails, mixed modal registers) produces viewer bounce, retention drops, and algorithmic penalty.
This mirrors Oswald's insight about brand semiotic incoherence at the advertising level, now operationalized as an algorithm-facing signal.
Video captions and transcripts create additional indexable semiotic resources.
Digital Discovery Networks found captions boosted views 13.48% in the first two weeks, with captioned videos ranking for keyword phrases appearing only in captions.
Structured data (schema markup, video sitemaps) functions as a meta-semiotic layer: signs about signs that enable algorithmic interpretation.
Conclusion: the meaning advantage
The research landscape reveals a striking asymmetry.
From one side, academic semiotics has developed extraordinarily powerful frameworks for analyzing how visual meaning works: frameworks with decades of theoretical refinement and empirical validation.
From the other, the short-form video industry has developed extraordinarily powerful distribution mechanisms that reward meaningful content with reach.
Yet almost no published work bridges the two.
The first pilot study explicitly combining narratology and semiotics for short-form platform analysis appeared only in 2025. Grzenkowicz and Wildfeuer's multi-level TikTok annotation scheme, published in Digital Scholarship in the Humanities that same year, noted that "systematic approaches to the analysis of these meanings are still scarce" and "comprehensive frameworks for this particular purpose are not easily available."
This gap is the opportunity. Enterprise teams that adopt semiotic frameworks gain three distinct advantages:
Diagnostic precision or the ability to identify exactly why content underperforms (misconfigured actants, incoherent modality markers, missing hermeneutic hooks) rather than guessing.
Systematic differentiation or tools like the semiotic square and RDE mapping that reveal unoccupied semantic territories competitors have not claimed.
AI-native production capability; because every AI video prompt is a semiotic specification, teams with semiotic vocabulary can articulate visual meaning that teams without it cannot even conceive, let alone generate.
The production barrier that once made video expensive also made semiotic precision optional and talented directors encoded meaning intuitively, now is gone.
What remains is meaning itself. The brands that master its grammar will own the next decade of visual communication.

Article by
Gianluca Fiorelli
With almost 20 years of experience in web marketing, Gianluca Fiorelli is a Strategic and International SEO Consultant who helps businesses improve their visibility and performance on organic search. Gianluca collaborated with clients from various industries and regions, such as Glassdoor, Idealista, Rastreator.com, Outsystems, Chess.com, SIXT Ride, Vegetables by Bayer, Visit California, Gamepix, James Edition and many others.
A very active member of the SEO community, Gianluca daily shares his insights and best practices on SEO, content, Search marketing strategy and the evolution of Search on social media channels such as X, Bluesky and LinkedIn and through the blog on his website: IloveSEO.net.



