
If you think you can have a top-performing site without giving much thought to technical SEO, think again.
Technical SEO forms the foundations of your website's organic performance.

No matter how much unique content you create, nor the number of incredible links you attract, poor technical proficiency will significantly reduce your traffic potential.
But fear not!
In this article, I’ll explore the critical concepts of technical SEO, give you an overview of all the essential facts, and link to key resources for further reading.
What is technical SEO?
Technical SEO is the process of optimizing the technical components of a website; specifically, how search engines crawl, render, and index your content. Improving technical SEO helps search engines better understand your site and is essential as it impacts all other aspects of SEO.
Poor technical website foundations result in lessened content and link building benefit as search engines cannot fundamentally understand or access your website.
Technical SEO encompasses various SEO concepts, such as:
Structured data
Index bloat
Site structure
Crawl budget wastage
JavaScript best practices
Technical mobile SEO
Technical SEO vs. on-page SEO
The first thing to know is that SEO is the umbrella term of three main areas:
Technical SEO
On-Page SEO
Off-Page SEO

So while this article focuses on technical SEO's importance, on- and off-page are still essential. Make sure to incorporate each area into your overall SEO strategy.
What's the difference between on-page and technical SEO?
With on-page SEO, content and keyword optimization are the focus. Technical SEO helps ensure search engines can efficiently access and index the content you want.
Crawling, rendering, and indexing
Throughout the rest of this article, you’ll see me referring to these three key concepts. Before we go on, it’s crucial to understand what each one means.
If you’re a beginner, Google’s content on how search works is a great resource.
Crawling
Crawling is the process of a search engine bot accessing a URL and all of its content on your website. There are different ways for bots to discover URLs:
Access one page, look at the available links, and queue those up to crawl next.
Use an XML sitemap to find a list of URLs you want indexed on your site (more on these later).
Refresh (recrawl) content that has previously been discovered and indexed.
Rendering
In general, rendering is the act of taking all the website code (like HTML, CSS, and JavaScript) and turning it into pages that a user can read and interact with.
A browser does this for a user, but a search engine bot also renders the page to access and understand the content on the site. Coding problems can make it difficult for the bots (and users) to get to this content.

Historically, you would find most content on a webpage within the HTML sent by a server. Now, sites more commonly inject content into HTML via JavaScript, often using popular JavaScript frameworks like React or Vue JS (although this isn’t a requirement!). In these situations, the browser does the heavy lifting of creating the HTML rather than the server.
The practice of injecting content into a page is called client-side rendering.
What’s important to understand with client-side rendering is that if a bot cannot render your page, it cannot see the content, resulting in content not being seen and internal links not being queued for crawling.
We’ll talk more about how technical SEOs overcome these issues later.
Indexing
Indexing is the process of a search engine taking the content it has crawled and rendered and then storing it for later use.
The point of an index is to store and organize data before a user requests information to speed up the retrieval process.
Imagine the slowness of a search engine if it had to crawl the web to discover content after you searched it; an index prevents the poor user experience this would create.
For Google specifically, their indexing system is called Caffeine.
While I could dedicate an entire article to indexing, some key facts to understand are:
Indexing happens after crawling and rendering, which means preventing indexing does not prevent crawling.
Preventing crawling doesn’t prevent indexing either. If Google collects signals that indicate a page is, they may still index and show it within search results.
Indexing is when Google makes sense of the information. That means extracting things like structured data, meta tags, internal links, and more.
Google pre-applies some ranking signals based upon the content it has indexed.
Further reading
What's included in technical SEO?
Managing search engine crawling
Managing crawling is an integral part of technical SEO for large sites as it ensures search engines are focusing on crawling important content you want to show within search results. It’s important for a few reasons:
Suppose crawlers dedicate resources to areas of your site that aren’t useful for SEO and may be noindexed. In that case, they aren’t crawling important pages or the new content you’re publishing, which can cause delays in how quickly search engines show changes on your site in search results.
Not managing how bots crawl your site could end up with you wasting server resources.
Not managing crawling could cause search engines to access and index pages on your site you don’t want them to.
It’s also essential to understand that crawling doesn’t become an issue for most sites.
A small amount of consideration is required to prevent search engines from crawling pages they shouldn’t, such as your search pages or admin area. But managing crawling to prevent crawl budget wastage doesn’t become something to consider until:
You have 10,000s of pages with content that changes frequently
You have over a million crawlable URLs
I’ve bolded "crawlable" above, as it’s an important consideration. You may look at your site and think you only have 5,000 pages, so monitoring your crawl budget doesn’t apply.
You could be very wrong.
Technical issues with your CMS could generate lots of URLs for Google to crawl, even if you don’t want them to be indexed.
This kind of generation of URLs often happens dynamically from elements practical for user experience but not needed for search results.
A great example of this is faceted navigation, often found on ecommerce or job sites to help you filter and discover the right product or job.
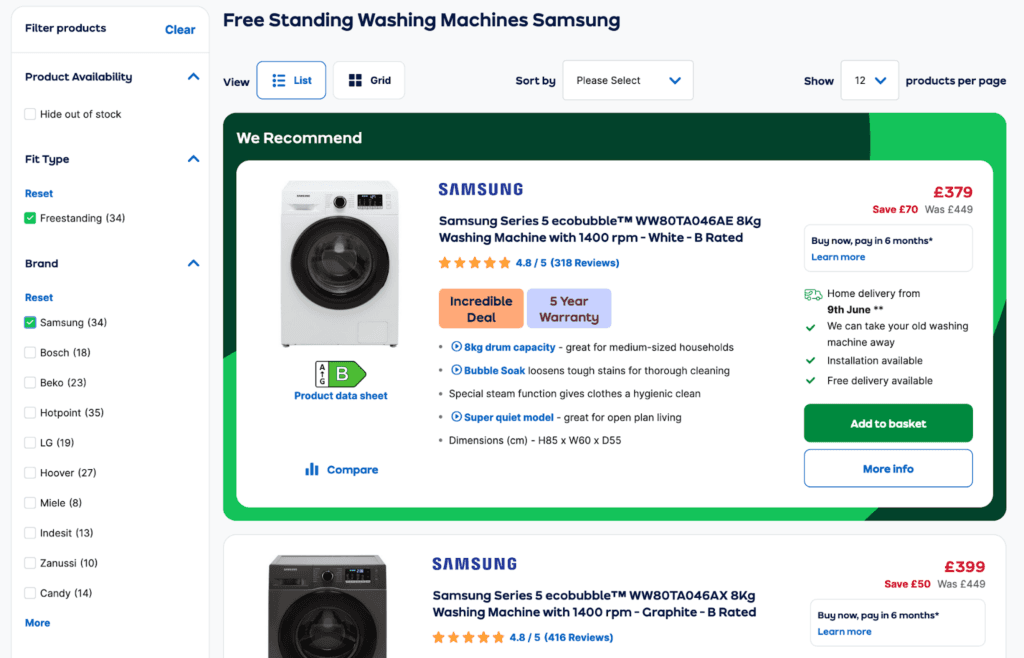
If you select a filter and the URL changes, that could create an infinite number of URLs for Google to crawl as there is a never-ending number of combinations of filters that could be applied.
The rest of this section will explain key ways in which you can manage crawling.
Robots.txt
The robots.txt is a file used to manage how bots crawl your website, it’s a simple text file that you’ll need to create and upload to your server on the root, so it looks just like this:
While it isn’t a requirement for bots to obey it, good bots do.
If you’re using a popular CMS like Shopify or WordPress.org, they’ll already have created a file like this for you, and it’s something you can go in and change.
Search engine bots like Googlebot and Bingbot will use the robots.txt to understand the sections or pages on your website you don’t want them to crawl. It’s the most effective way to manage your crawl budget (the number of resources Google will dedicate to crawling your site).
Using the robots.txt
Here is an example of what a robots.txt looks like:
In this example, we’re telling bots not to crawl files within the directory /v2/. You can do a few more things with robots.txt that make them pretty flexible regarding the rules.
For example, we could disallow /v2/, but allow a images subdirectory:
We could block all URLs containing a specific word using the * wildcard (use caution; this example would block URLs containing words like "latest").
We could create rules specific to Googlebot, rather than all bots with *:
The above would result in Googlebot ignoring any entries into the first group of robots.txt rules and only looking at rules in the second group specific to Googlebot.
We could also group our robots.txt and add comments using the # to let other people working on the site know why we decided to block certain pages.
# Blocks /v2/ for all bots, we only want Google to see this
Some more important things to understand about the robots.txt file:
You have to place it on the root of your site, e.g., domain.com/robots.txt.
You need to format it as a UTF-8 encoded text file.
By default, crawlers will try to access all URLs on your site. The robots.txt is the only way to prevent a crawler from accessing a URL.
The robots.txt is case sensitive.
You shouldn’t use it to block private content. Instead, password protect it with HTTP authentication.
While rare, it's important to know what a UTF-8 BOM is and how it can break your robots.txt (I’ve only found one of these in my eight-year SEO career).
Nofollow
The nofollow tag is another tool for the technical SEO to manage crawling of internal links.

The nofollow tag is used with external links to tell Google not to pass PageRank and not associate your site with the linked site.
Using the nofollow tag isn’t a surefire way to prevent Google from crawling an internal URL like the robots.txt is, but Google sees it as a sign the page you’re linking to isn’t important and Google doesn’t need to crawl it, as confirmed by John Mueller.
“....we will continue to use these internal nofollow links as a sign that you’re telling us:
These pages are not as interesting
Google doesn’t need to crawl them
They don’t need to be used for ranking, for indexing.”
Why use an internal nofollow?
If a robots.txt is a directive, and the nofollow is a hint, you’d think the obvious choice is the robots.txt.
Even Google suggests as much in their documentation.
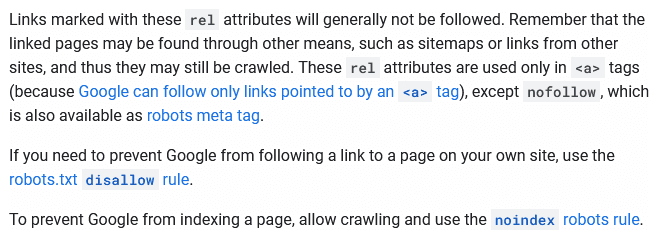
That’s true in many cases, but in some scenarios, the robots.txt can be a challenging tool for managing crawling.
It’s something I raised in a Twitter thread.
The use case is to signal to Google to not crawl an internal link when blocking via URL patterns in the robots.txt isn't straightforward.
I get the advice is to 'just use the robots.txt', but there aren't always patterns in the URL that make creating those rules easy. — Sam Underwood 🇬🇧 (@SamUnderwoodUK) July 6, 2021
The robots.txt becomes incredibly difficult to use on sites that generate millions of URLs with no identifiable URL patterns for preventing crawling.
For example, say we have filters on ecommerce categories that create 10,000s of URLs with a /colour/ directory for color facets.
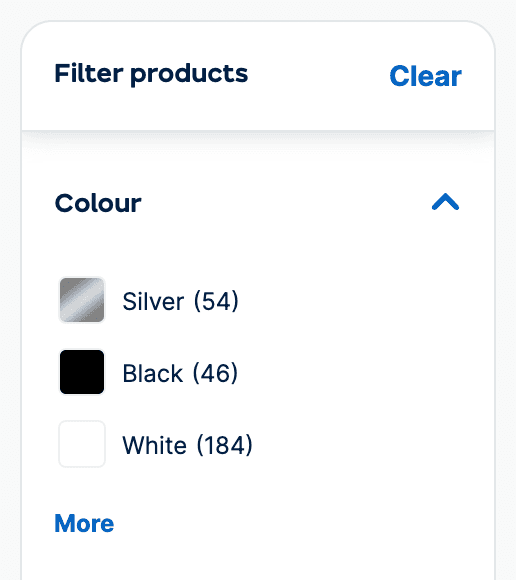
We could prevent this directory from being crawled in robots.txt using:
But what if 2,000 pages within the directory are helpful for search, so we want crawlers to be able to access them?
Unless there is a clear URL pattern for us to identify, we’d need to define "Allow:" rules for the page we wanted to be indexed. Such as:
Now scale that problem across all the colors, categories, and facets you want to allow crawling of; your robots.txt will get long and complex quickly.
Developing a solution to automatically add an internal nofollow to the links pointing toward content that isn't useful for search can help solve the crawling problem. However, it's at Google’s discretion whether to obey your instructions.
Managing indexing
Now we’ve explained managing crawling; the next step is to understand managing indexing.
For most sites, managing what search engines index is a higher priority than managing how search engines crawl their site.
Why?
Search engines evaluate your site based on the pages they index, which directly impacts how your site performs in search results.
Here is a clip of John Mueller explaining this in a Webmaster Hangout.
You'll hopefully realize that ensuring Google only indexes high-quality content is essential.
Despite this, indexing issues are prevalent for most sites, negatively impacting Google’s view of the site’s quality.
There are two causes of Google indexing low-quality pages:
Low-quality content, which is more within the realm of on-page optimization
Index bloat; Something a technical SEO will solve
Index bloat
Index bloat is when a search engine has pages indexed that aren’t useful for search results. Common examples of these types of pages include:
Duplicate pages, such as content is available in two places, such as example.com/this-is-a-blog-post and example.com/blog/this-is-a-blog-post
Internal search pages
URLs with parameters (often for tracking)
URLs created for filtering (faceted navigation)
A quick and easy way to spot index bloat is by using Google Search Console. Simply head to the coverage reports, check "valid" URLs, and you’ll find a table summarizing the URLs Google has indexed on the site.
One handy feature of this report is if you’ve uploaded an XML sitemap (more on those later), you’ll get a comparison between the URLs you’ve submitted to Google and the URLs you haven’t.
You can quickly spot index bloat if you’ve uploaded an accurate XML sitemap by comparing these two rows.
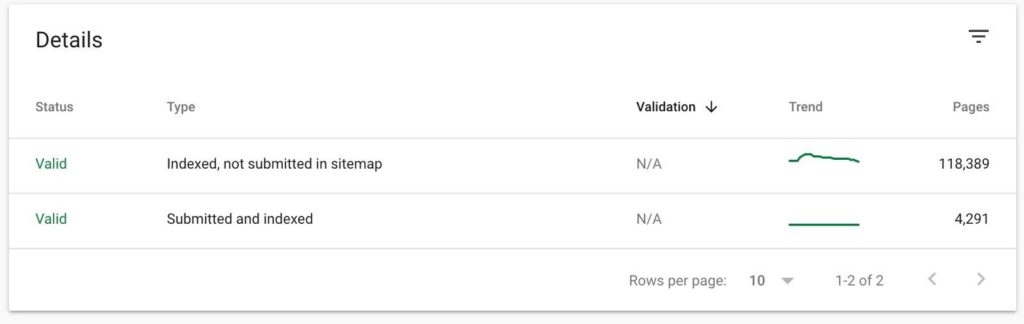
The site above has some obvious index bloat issues that need resolving (evident due to the large difference between indexed and not submitted URLs vs. submitted and indexed).
But how do you resolve index bloat? There are two ways to do that. I’ll explain them both and then give you some tips on when to use what.
Noindex
The noindex tag is a directive that tells Google not to index the content they’ve found via crawling.
It’s best to use this tag if the content isn’t a duplicate of another page and isn’t useful for users on search engines. Common examples of these types of pages may be a search results page or a low-value page your CMS creates, like how WordPress creates image attachment URLs.
You can implement a noindex in two ways.
Meta tag
The first option is via a meta tag that looks like this:
Simply add the above to the <head> of your site.
HTTP header
The other option is via an HTTP header like the below:
Most sites opt for the meta tag as it’s usually a bit easier to implement, but both options will do the same job. It’s best to go with the one that you can implement easily with your current setup.
Canonical tag
You can use a canonical tag to consolidate duplicate URLs.
That means you can only use it to manage indexing for URLs that have the same content or similar content as each other. If you want to prevent indexing of a URL that isn’t a duplicate, a canonical tag isn’t the correct method.
The benefit of a canonical tag is that it consolidates ranking signals into whatever you specify as the canonical URL. This results in no loss in benefit from external links or other ranking signals associated with a non-canonical URL, as long as you’ve implemented the canonical tag correctly.
There are two ways to implement a canonical tag.
Meta tag
Like a noindex, you can add a canonical tag within the <head> of a page like this:
Say you had a duplicate variant of that page like the below examples:
https://www.example.com/example-url (with www)
https://example.com/example-url?sessionid=1241224 (with a tracking parameter)
https://example.com/example-url/ (with a trailing slash)
For those URLs, you’d have a canonical tag on each that points toward the primary version of the page you want to be indexed e.g.
You can also have canonical tags on content on external domains that point to your domain; useful if you’re syndicating the same piece of content on multiple platforms to increase its reach.
HTTP header
If you can’t implement the canonical tag in the <head> of a page, you can also implement it via an HTTP header like the below:
Link: <https://example.com/example-url>; rel="canonical"
While this is rarer to see across the web, an obvious use case is to consolidate ranking signals on non-HTML documents, such as a PDF file.
Can you prevent indexing via crawling?
Given that I’ve explained crawling happens before indexing, logically, you’d think that Google wouldn’t index if you’ve prevented crawling via the robots.txt.
That isn’t the case.
Even if Google can’t crawl a URL as you’ve blocked it with the robots.txt, if Google thinks the blocked content is helpful for search, they may still index and show it.
Some key signals to Google to still index content blocked from crawling includes:
Internal links to the URL
External links to the URL
If you have a URL that suddenly starts getting lots of referring domains, but you’ve blocked it with the robots.txt, Google may decide that it has value for search and index it.

Additionally, if you’ve blocked a URL from being crawled but the URL is already indexed, Google won’t be able to access the page and see any markup you’ve added, such as a canonical tag or noindex.
The result is that if you don’t want the URL indexed, you’d have to add a noindex tag to the page (if you haven’t already) and then allow Google to crawl the page so they can see the tag and then remove it from their index.

Implement structured data
Rich results are pretty much the norm for most SERPs now. They come in many flavors, but you can quickly identify them by the additional information provided outside of the classic ten blue links of the past. Here is an example one:
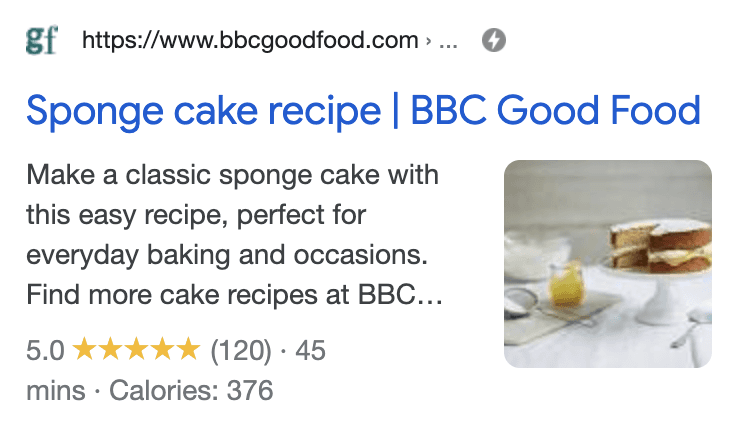
Essentially, it’s a result that’s a bit more visually engaging and usually increases the organic click through rate of your page in the SERP.
To acquire rich results, you’ll need to implement structured data or use the Data Highlighter tool.
Structured data uses a vocabulary (described at Schema.org), which you implement via code (preferably JSON-LD) that search engines use to understand your content better.
Getting started with structured data
There are many great resources on structured data; you can find most of them within Google’s documentation.
Here are some suggested reads:
The Search Gallery: A gallery of all the rich results you’ll find on a SERP, alongside documentation on how to acquire them.
A Practical Introduction to Structured Data for SEO: Sitebulb has many great articles about structured data; their intro guide is a great place to start.
Rich Snippets: Simple Guide to Boosting CTR in SERPs: A beginner's guide I’ve written on rich results, the benefits, and how to get them.
Structured data testing tool: A tool to validate your structured data implementation.
Understand how structured data works: Google’s intro guide to structured data.
Does structured data improve your rankings?
Structured data does not directly impact your rank, but it can help Google understand targeting and relevancy, as confirmed by John Mueller.
There's no generic ranking boost for SD usage. That's the same as far as I remember. However, SD can make it easier to understand what the page is about, which can make it easier to show where it's relevant (improves targeting, maybe ranking for the right terms). (not new, imo)
— 🧀 John 🧀 (@JohnMu) April 2, 2018
In other words, don’t expect structured data to improve rankings, but if your page is a little ambiguous as to what you’re talking about, it could help.
Use the correct status codes
You're familiar with visiting a particular page, only to be met with a message saying you can’t view that page.
A page may be inaccessible for many reasons, and there’s a status code to go with each one.
Common things that status codes tell browsers/bots include:
A page doesn’t exist
A piece of content has moved to a new URL
The requested URL is password protected
The content is currently unavailable (and will be back soon)
You can add and see status codes within the HTTP headers, which are vital for SEO. Search engines use these headers to understand critical information about the current and future availability of the content on your site.
Status codes are generally added via the server. However, these can usually be configured without the need of a backend developer thanks to plugins (like this one for WordPress) or server admin panels (like cPanel).
Here are some common header response codes and what they mean.
200 status code
A 200 status code indicates that the request is a success and the content found on the URL will be sent within the response body.
If a search engine crawler sees a 200 status code, they’ll treat it as indexable content, unless you tell them not to with a noindex or the content isn’t valuable for search.

301 status code
A 301 refers to a permanent redirect; you should use it when the content someone is trying to access has moved to a different URL.

You’ll often use 301 redirects when:
You change the URL slug for a page
You move from HTTP to HTTPS
You change your domain name
You automatically append a trailing slash to all URLs
One page has replaced another page
Search engines use 301s as a strong signal that they can find the URL they are accessing somewhere else, and they should consolidate all ranking signals to the destination URL.
You must use 301 redirects to ensure all the ranking signals you’ve accumulated on a URL don’t get lost.
302 status code
A 302 redirects the user to another page but indicates that the redirect in place is only temporary.

You may choose to use a 302 when you want to send a user to a page, but the original URL they accessed is coming back soon.
For example, you may use a 302 if you’re running an A/B test and want to send some users to the variant URL while the test is running.
Make sure not to use 302s in place of 301s. Historically, Google used to not pass on ranking signals in the same manner as they do for 301s as they do for 302s. Nowadays, they say they’re equivalent to Google.
Still, it’s best to use the correct status code for what you’re trying to do.
404 status code
A 404 status code refers to a page that a server hasn’t found.

Common reasons for a 404 are:
The content has been removed and isn’t coming back.
The page has been moved, and the webmaster forgot to set up a 301 redirect.
It could also result from a simple mistake such as an incorrect link or the user mistyping a URL on their browser.
If you’re using a hosting company, their servers are usually configured to return a 404 for not found content by default.
You can easily test this through using Chrome Dev Tools. Simply visit your domain and enter a slug in the URL for something that doesn’t exist, like this:
Next, open up Chrome Dev Tools (CMD/Ctrl + Shift + I) and head to the Network tab:
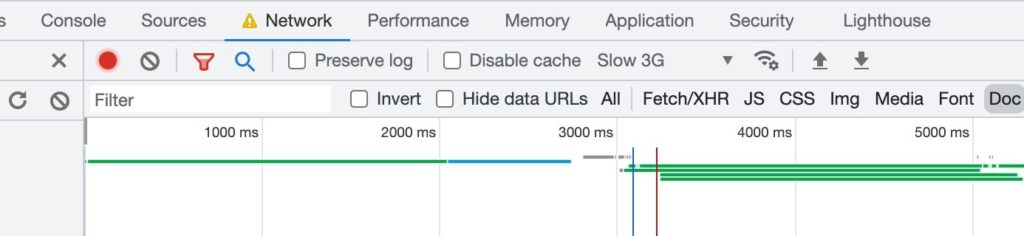
Next, filter for "Doc," and you should see the initial HTML request.
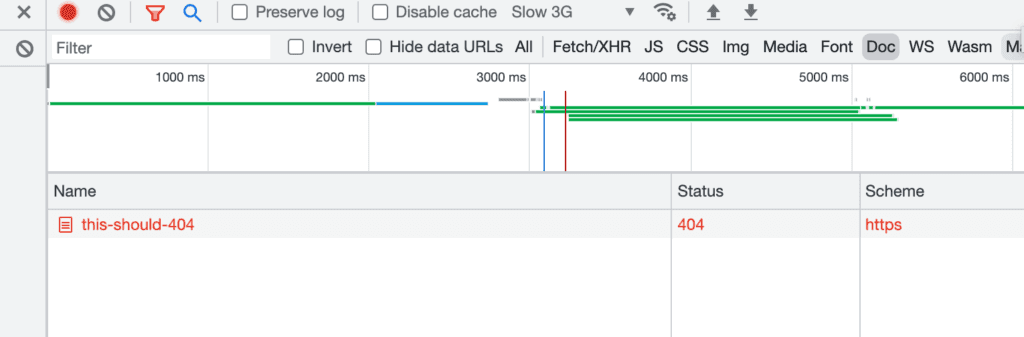
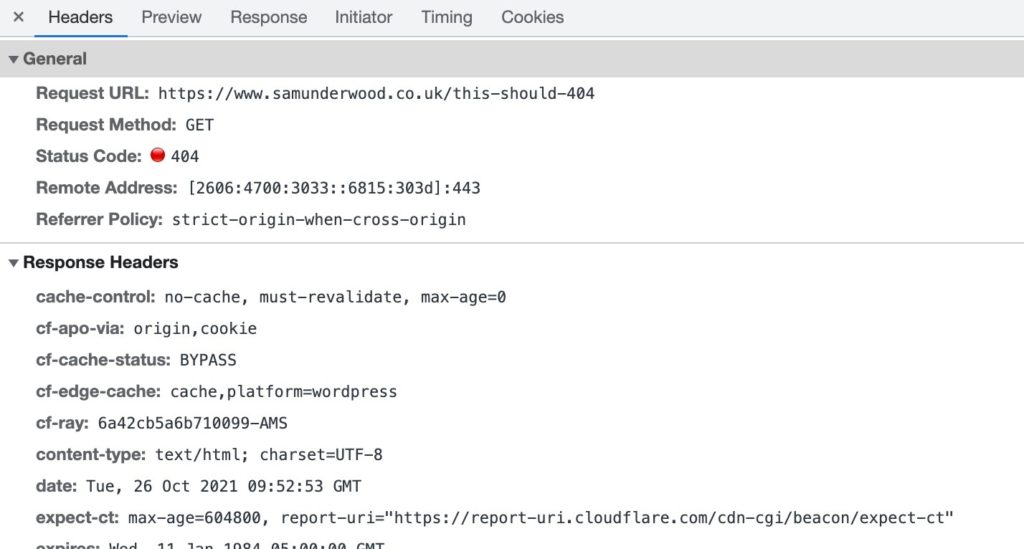
You can see the status code returned is a 404. If you want, you could also check the HTTP headers yourself, just select the row and you’ll see a summary of all the response headers.
When a user comes across a 404, there will be nowhere else for them to go. They’ll have essentially gotten to a dead end. So it’s a best practice for UX to guide the user to a page they may find useful, whether that’s a list of recent blog posts, or simply back to your homepage.
While a 404 page looks different for every site, they usually look something like this:
Whatever the reason, 404 status codes tend to cause users to bounce and provide a poor UX, so you should minimize them.
In addition to a poor UX, 404s on a site wastes crawling resources for search engines, and if a popular URL on your site starts to 404, you will lose any associated ranking signals.
That said, 404s are also entirely normal and something you should use as long as you’re using them as appropriate.
You should use a 404 status code, or a 410 if the content of your page no longer exists and isn’t coming back. When you do this, Google will de-index the content.
However, if there is similar content located elsewhere on the site, instead use a 301. By doing this, users are sent to content that fulfills whatever requirement they had, and search engines will associate ranking signals with the URL you redirected to.
Different auditing tools enable you to keep your eye on potential 404s; the most accessible one is Google Search Console.
In your Google Search Console account, select "Excluded" in the coverage reports.
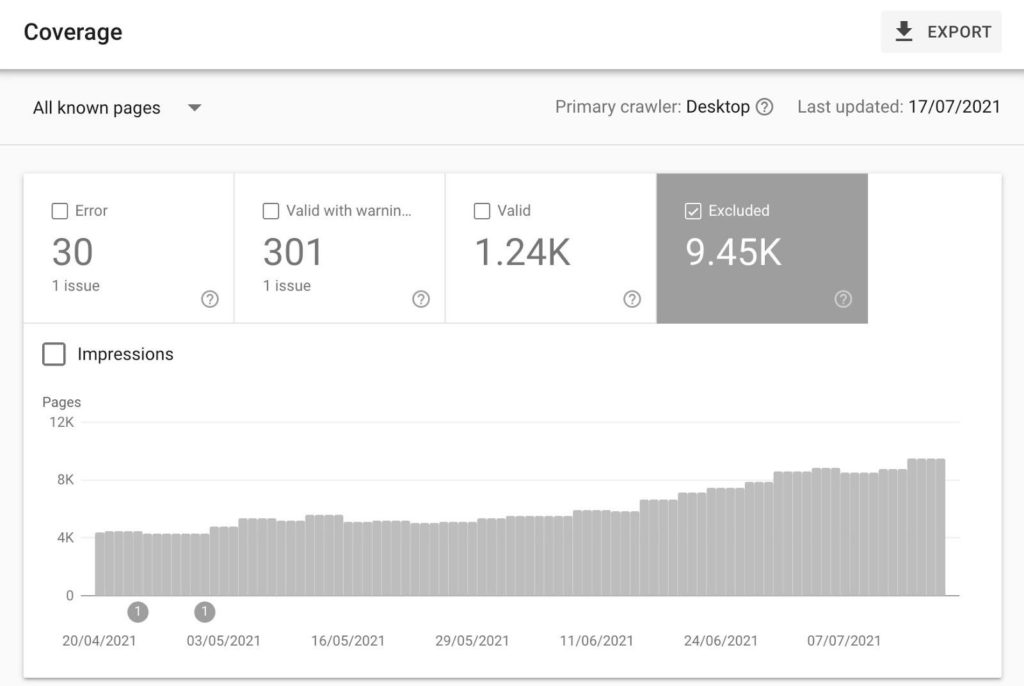
Select "Not Found (404)" in the table below the chart, and you’ll get an overview of all 404s Google has found on your site.
In addition, you can find a list of soft 404s within this report.

A soft 404 is where Google has found a URL that it believes should return a 404 status code, but it hasn’t. This is often caused by messaging on the page that you’ll commonly find a 404 page, such as saying "X has not been found" or "X is unavailable," but the 404 status code hasn’t been reported.
Google will occasionally mistakenly report a soft 404 and begin de-indexing a URL, so it’s important to monitor these reports.
503 status code
A 503 means that the server is unavailable and a message will inform the user to come back later, suggesting that this is temporary.

This could occur when server maintenance occurs or when the server has become overloaded and cannot handle any further activity.
Google understands the 503 status code and will stop crawling the site and check back later to see if it’s available again.
You must use the 503 status code during site maintenance rather than doing something like 404ing each page, which could result in Google removing the site from their index.
XML sitemaps
XML sitemaps allow search engines like Google to easily find URLs on your site ready for crawling and indexing.
More reliable than hoping search engines crawl your content, XML sitemaps provide a list of all the URLs you want crawled and indexed.
The process works in a few steps:
You provide a list of the URLs on your site to be indexed, following the standard sitemap protocol.
You reference your XML sitemap in your robots.txt and link to it from tools like Google Search Console or Bing Webmaster Tools.
Search engines discover URLs in the XML sitemap, then crawl and (hopefully) index them.
Here’s an example of what a sitemap would look like for a single URL:
To add multiple URLs, you’d simply copy and paste contents of the <url> tag and update the values for the <loc> and <lastmod> tags.
The <lastmod> tag is not required, but it’s a great way to upgrade your sitemaps and make them more valuable for search engines. If you keep this <lastmod> value up to date with any HTML changes on the pages of your site, Google and other search engines will use it to understand better when they should crawl a URL and refresh their index with the URLs latest content.
In addition to aiding the discovery of content, Google also uses XML sitemaps as an indication of the canonical URL, making it an additional tool for SEOs to use on sites with duplicate content issues.
Sitemaps aren’t essential for SEO, but it’s well worth creating one if you have a big site with many pages. John Mueller even says XML sitemaps should be a baseline for any serious website, showing their importance.
HTTPS and TLS
HTTP (Hypertext Transfer Protocol) and TLS (Transport Layer Security) were originally two separate protocols put in place to keep your site secure.
But everyone mainly talks about HTTPS.
HTTPS is simply HTTP with data encryption using TLS. If you have yet to implement it, make sure to put that high up on your to-do list.
Not only does HTTPS help keep your site secure, but it’s also essential for many reasons, including:
It’s a trust signal
It’s a small ranking factor
It shows within Chrome and other browsers if a site doesn't have HTTPS
HTTPS protects third parties from intercepting communication between your server and a user’s browser, making it essential for protecting confidential user information.
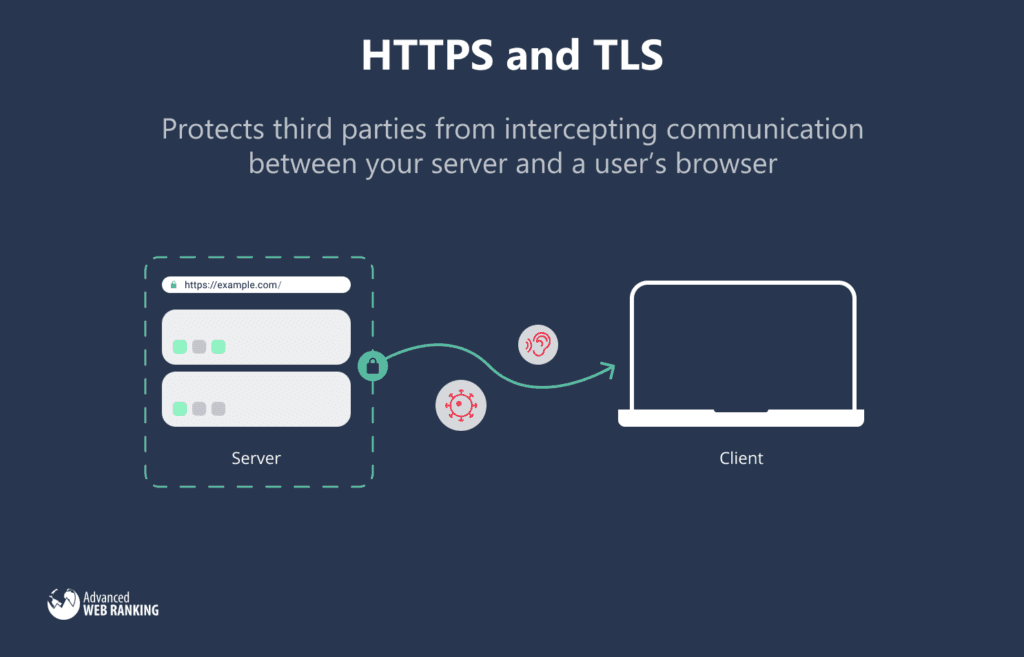
HTTPS is important for all sites, but more so if users share information, especially with ecommerce sites where financial information is shared. Users trust you to keep financial information safe, and not having HTTPS is a big warning sign to users.
International SEO
If you have multiple languages on your site, it adds another level of complexity to technical SEO.
The primary technical consideration you will have is hreflang, which search engines use to ensure they serve the correct URL for each country and language variant you have on your site.
You’ll find hreflang in HTML tags, XML sitemaps, or HTTP headers. It specifies the language and region of the page you're on and where to find page variations for different languages or regions.

Hreflang should both be self-referential and point to international variant pages. On an English page with a French variant, it’d look something like this:
You can also optionally specify a region after the language value, so if you had a Canadian French page as well, it’d look something like this:
An important element to understand with hreflang is how it’s reciprocal. If on your English page you pointed an hreflang tag to your French variant, the French variant would have to have an hreflang tag to your English page.
Aside from search engines serving the correct URL on your site to users when you add the above markup, there is another significant benefit.
Weaker pages within a cluster of reciprocal hreflang tags will benefit from the "strongest" URL within the cluster. If your /en/ page performs well, but /fr/ doesn’t, when you add reciprocal hreflang, Google will associate the two and realize the /en/ does well for English-speaking users, so likely the /fr/ version will also be suitable for French-speaking users.
This isn’t a two-way sharing of signals, but rather a "stronger" version of a URL that brings other URLs in a cluster "up to its level."
While hreflang elements are important to implement, a well-thought-out international SEO strategy isn’t complete without:
URL considerations
Localized site structures
And that’s just the technical SEO side.
Want to learn more? I’ve written an in-depth guide for all things international SEO that you can read here. I’d also recommend watching this Q&A with Gary Illyes on hreflang.
Managing pagination
Sites use pagination to break up listings (often products or blog posts) within an archive into a series of pages rather than having one long page with all the listings.
Common types of archive pages you’ll see across the web include:
Ecommerce category pages
Blog category/tag pages
The traditional way a series of archive pages link to each other is via a numbered list that helps you quickly navigate deeper into the site.

New UX patterns have emerged to link to pages in an archive, such as "load more" buttons and infinite scrolling. Developers achieve both of these UX patterns with the use of JavaScript.
Previously, a key consideration for SEO was adding prev/next tags in the <head> to help Google associate paginated URLs. Now, Google is good at understanding pagination without additional help, so it’s no longer a requirement (although other search engines may still use it).
Here are the remaining considerations for pagination:
Ensure you link to pages deeper within pagination archives to aid navigation. This isn’t possible with a load more implementation, which is why most SEOs recommend the traditional numbered links.
Make sure pagination isn’t all JavaScript-based. It needs to have href links to URLs within the sequence, which is often an issue with infinite scrolling.
Canonical tags on paginated URLs should be self-referencing.
Don’t prevent the indexing or crawling of pagination unless there are alternate crawl paths.
JavaScript SEO & client-side rendering
Back in the day, servers either statically delivered HTML to a browser or rendered HTML from languages like PHP, hence "server-side rendering."
However, full client-side rendering is where the browser does all the heavy lifting of generating the page using JavaScript. This practice has been growing in popularity since the mid-2010s.
While this approach has many positives, including reducing server costs, it comes with SEO complications.
Historically, Google hasn’t done a great job of rendering pages that use a lot of JavaScript for important content. Thankfully, with recent developments, Googlebot now uses an up-to-date version of the chromium rendering engine and is far better at discovering content on client-side rendered sites.
Still, not all search engines render JavaScript effectively and relying on them to render correctly is risky and it’s better to simply render JavaScript for them.
There are a few ways in which to do this; here is a brief overview.
Server-side render/statically generate
The recommended best practice is to keep rendering server-side or statically generate HTML to prevent search engines not fully rendering or rendering a page incorrectly.
The two most popular tools for doing this are:
For both of these, you also have the option to "re-hydrate" the page. The result of this is the initial request is server-side rendered, but any subsequent requests are client-side rendered, giving you the best of both.
Dynamically render
There is also the option to dynamically render the page. This is where you’ll continue client-side rendering, but server-side render when a user agent of a search engine crawler is detected.
This can be done by your own server, or you can introduce an intermediary service to render the page for you and then serve the content to those user-agents, like prerender.io.
If you have good reason to continue client-side rendering everything, this is an option.
Common pitfalls
All sites that client-side render have to overcome the same issues. Here are few common issues you’ll need to make sure you get right:
Make sure pages still return status codes, like 301s and 404s.
Use <a> links with the href attribute, rather than relying on JavaScript for navigation.
Do not inject content on click. For example, if you have an accordion, hide and show it with CSS rather than inject the HTML when an element is clicked.
Website structure
Your website structure plays an essential role in helping search engines understand the content on your site.
Website structure also tends to take a lot of effort to change, but can significantly impact your performance within an organic search when improved.
Here are a few technical considerations for structuring your website.
Implement a logical site hierarchy
This is all about the organization of your site’s content.
No one wants to visit a site only to see a mass of different pages that haven’t been logically grouped into parent and child pages.
This is why your site needs structure.
For a travel site, a structure with multiple levels based upon the location gives search engines (and users) a strong understanding of how you’ve organized content.
Home > Spain > Tenerife > [Hotel Name]
Creating parent and child pages based upon a logical taxonomy (like a location in the above example) makes the navigation of a site significantly better and helps users and search engines understand its structure.
It’s key that internal linking is also planned based around this structure. For example, parent pages like Spain would have internal links to islands/cities within the country, like Tenerife.
Use breadcrumbs
Breadcrumbs are a series of internal links that show the user where they are on the site and the way you’ve organized the site to help them navigate around it.

In a hierarchical structure, each page within the breadcrumbs would have subnavigation to the subsequent level. For example, the USA page in the above breadcrumb would link to the New York page, which then links to the "Things to do in New York City" page.
Breadcrumbs don’t just help improve user experience; they also make it easier for Google to understand how you’ve organized the site, especially if you implement breadcrumb structured data.
Use a structured URL
The URL structure refers to directories you have within your URLs. Just like breadcrumbs, it gives users an understanding of the site's organization.
Ideally, the user should understand what the page is about and where it sits within the site hierarchy from the URL.
For example, a URL like this is impossible for a user to understand:
However, the following URL is meaningful to a user:
The previous URL shows:
Where the URL sits within the site hierarchy
What the page is about
How you implement URLs really varies from site to site, depending on the structure.
In general, I recommend implementing URLs in a way that makes the most sense for users. Google mostly uses URLs simply as an identifier for content, they may use URLs to understand structure in some cases, but that will mostly be understood based upon breadcrumbs and how you internally link to content.
Your URL structure should:
Be concise
Be easy to read
Reference what the page is about
Use dashes (-), not underscores (_)
Avoid redundant directories
Avoid too many directories (more than three directories are usually harder to read)
Site speed
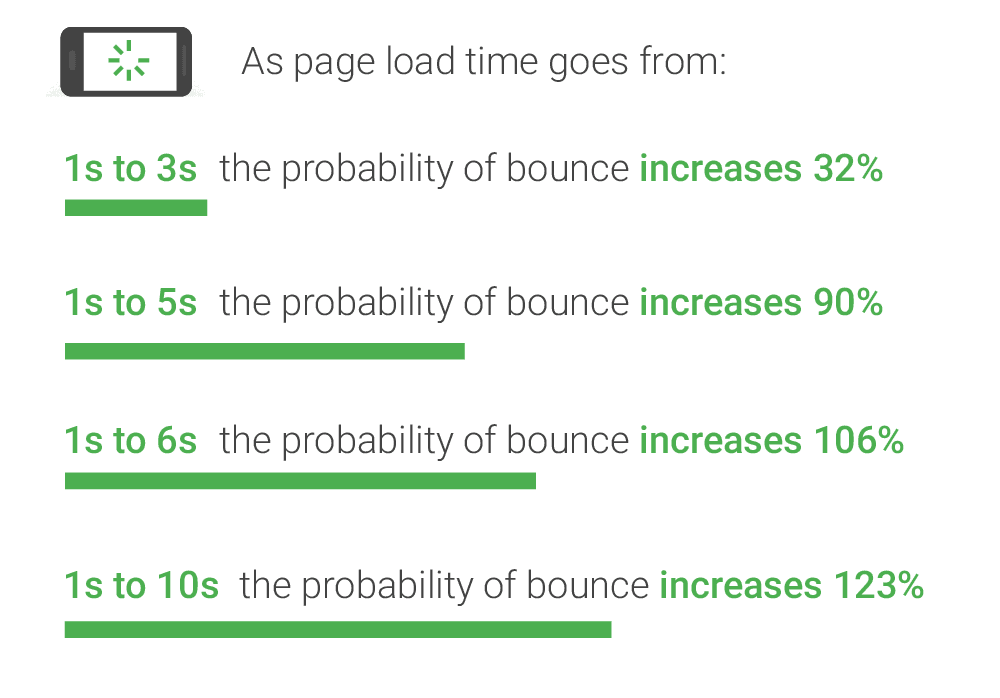
We’re an impatient species, in fact, so impatient that research shows that as page load times increase from 1s to 3s, the probability of a user bouncing goes up by 32%.
Google has released many well-known algorithm updates to reflect this (albeit with a minor impact on your overall SEO performance), including the recent Core Web Vitals update.
Site speed comes under the area of what a technical SEO will look at to improve a site. Thanks to these metrics, there is clear and measurable guidance on what impacts a user’s experience on your site the most.
If you want to see whether site speed is an area of technical SEO worth focusing on, run a test within Google’s PageSpeed Insights.
After you’ve entered the URL in question, you’ll get a summary score out of 100 on how well it performs, and a breakdown of your site's Core Web Vitals for that test.
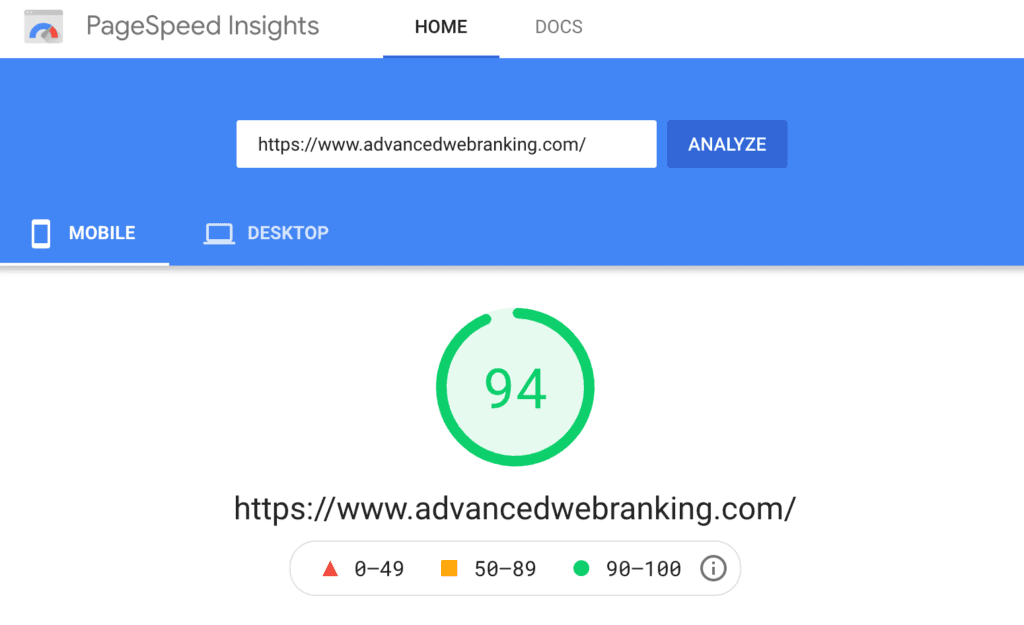
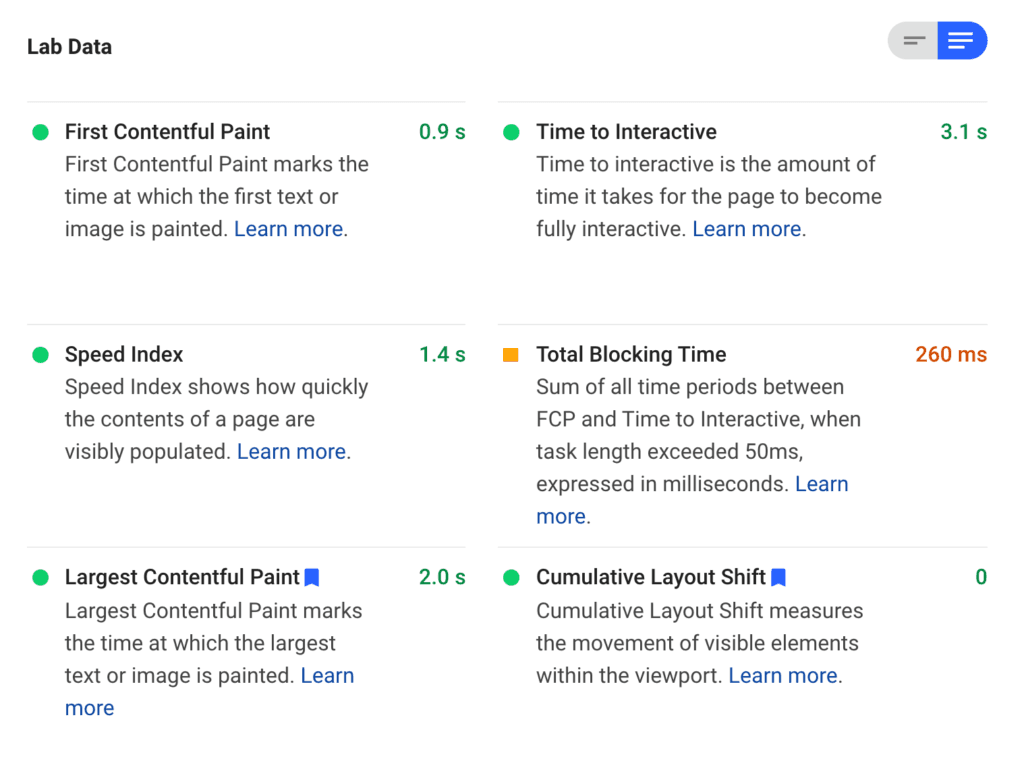
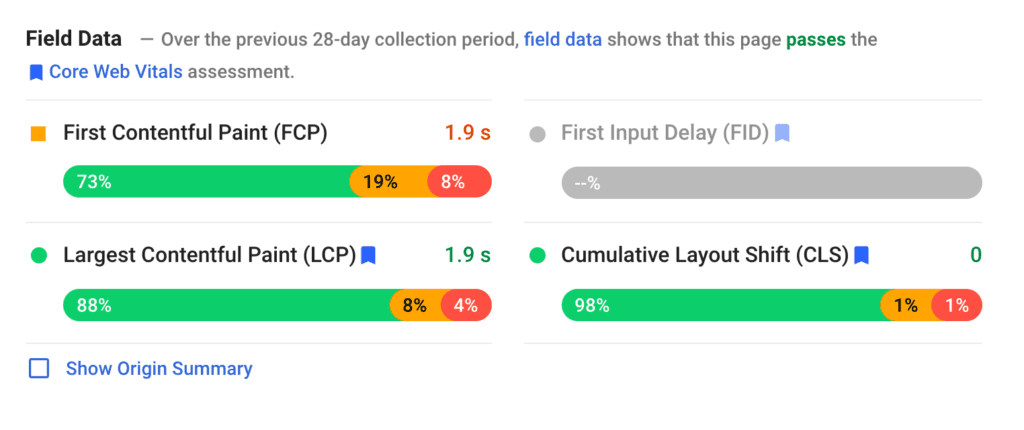
You'll also see how the URL entered has performed for a sample of users within the last 28 days.
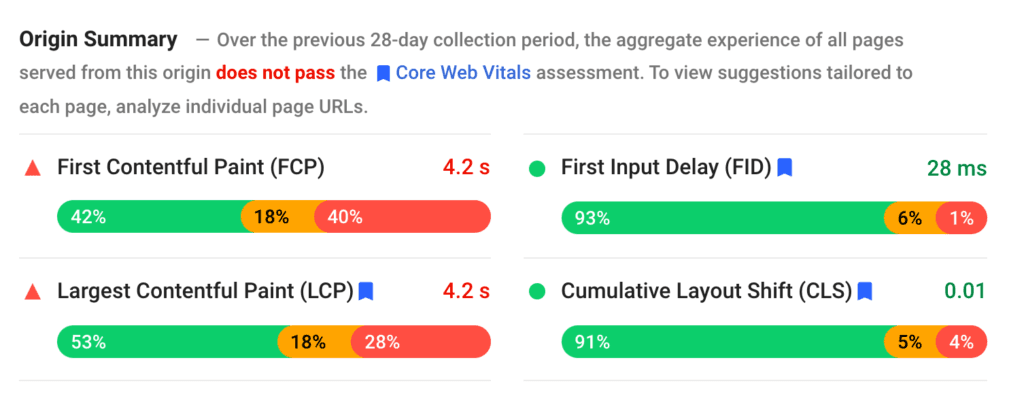
Optionally, if you select Show Origin Summary, you can also see that data for the entire domain.
Improving Core Web Vitals requires a dedicated article, which I’ve written here. If you want an overview of how you can improve these metrics, head to the end of PageSpeed insights.

You’ll get a list of "Opportunities" for improvements alongside the estimated savings in load times. You can also filter the opportunities section to see how each suggested improvement impacts different Core Web Vital metrics.
Mobile friendly
Making a mobile-friendly website has been important for SEOs since the mobile-friendly update way back in 2015. Since then, there have been further mobile SEO considerations due to Google moving over to mobile-first indexing.
If you’re not familiar with mobile-first indexing, it means Google will usually crawl the mobile version of a site and use the mobile version of Googlebot when crawling. The mobile version of the content is most often used for indexing and ranking, rather than the desktop version.
While I recommend reading my complete mobile SEO guide, the key is building responsive sites is the preferred option.
While you can dynamically serve based upon user agent or have a separate mobile subdomain, you’ll have to ensure parity between the desktop and mobile version, which is hard to upkeep.
If you opt for the responsive site route, the extent of mobile SEO is ensuring the site passes the mobile-friendly test and you have a meta viewport tag to inform browsers that the content of the page adapts to screen size:
Thanks to the same HTML being used for mobile/desktop with this setup, the technical complications are minimal.
Wrapping up
As you can see, learning technical SEO is no small task. This article summarizes many of the key concepts, but it still leaves the minutiae of technical SEO to be explored, and should be a great start to building a technically proficient site upon which you can create the rest of your SEO strategy.

