
Avoid the SEO Spider Trap: How to Get Out of a Sticky Situation
As an SEO consultant, I hear all manner of concerns relating to site ranking. However, one of the last to be mentioned, if at all, is the 'spider trap.' With so much focus given to great content, acquiring links and creating a dynamic social network, the importance of the web crawler is often overlooked.
It is often a complex web to untangle (pun intended); however, identifying and fixing spider traps is possible and a necessary step to making sure your website is receiving the attention it deserves.
What is a spider trap?
A spider trap (or crawler trap) is a set of web pages that may intentionally or unintentionally be used to cause a web crawler to make an infinite number of requests or cause a poorly constructed crawler to crash.
It occurs when a site creates a system that produces unlimited URLs or ‘junk’ pages. This structural problem will cause a web crawler to get stuck or trapped in your ‘junk’ pages.
We know that these ‘spiders’ or ‘robots’ are essential for crawling our sites, indexing our content and ultimately displaying it to our target audiences. So, if a website doesn’t allow a spider to move through it seamlessly, the spider will reach its allocated bandwidth allowance and move on to the next website.
In this case, the site will be deemed ‘less than optimal’ and be downgraded under a competitor’s rankings. If the problem is extensive, certain pages of a site might never make it to the SERPs and will therefore never be seen.
What does a spider trap look like?
There are four main types of common spider traps - each one looks different and requires varying methods of identification. They include:
Never-Ending URL: infinite different URLs that point to the same page with duplicated content.
Mix and Match Trap: the same information presented in endless different ways (e.g. millions of different ways to sort and filter a list of 1000’s of products).
Calendar Trap: pages that are technically unique, but provide no useful information (e.g. an event calendar that goes thousands of years into the future).
Session ID Trap: near-duplicates with pages that differ by some infinite detail.
The Never-Ending URL
What causes it?
Dealing with The Never-Ending URL trap is as annoying as that schoolyard song. It can be hidden in pretty much any website and is commonly the result of a poorly-formed relative URL or a poorly constructed server-side URL rewrite rules.
How do you identify it?
It’s uncommon to see the results of this trap within a web browser, as it’s buried deep within a site’s navigation pages. However, to locate it you will need a website crawler. If the site has this particular issue when the crawler-based tool is in use, the following will happen:
The crawl will momentarily run normally as the spider trap is invisible until the crawler reaches the ‘junk’ pages on the sites.
At some point, the list of crawled URLs will start to take a strange form, where each new URL is just a more extended version of the previous one.
As the crawl continues, the URL will get longer and longer because ‘it just goes on and on my friend…” (you get my point).
For Example:
http://yourdomain.com/yourpage.php
http://yourdomain.com/abcd/yourpage.php
http://yourdomain.com/abcd/abcd/yourpage.php
http://yourdomain.com/abcd/abcd/abcd/yourpage.php
http://yourdomain.com/abcd/abcd/abcd/abcd/yourpage.php
http://yourdomain.com/abcd/abcd/abcd/abcd/abcd/yourpage.php
http://yourdomain.com/abcd/abcd/abcd/abcd/abcd/abcd/yourpage.php
http://yourdomain/abcd/abcd/abcd/abcd/abcd/abcd/abcd/yourpage.php…
How do you fix it?
Using the crawler tool used to locate the trap, set the functionality tool to sort by URL length. After doing this, select the longest URL and you’ll find the root of the problem. Following this, it’s important to sift through the source codes of the page in question looking for any further anomalies.
If you are knowledgeable in programming, there is a technical solution to solving the issue. Disallow the offending parameter within the robot.txt file or add server-side rules which ensure the URL string doesn’t exceed the maximum limit.
Mix and Match Trap
What causes it?
This trap occurs when a site has a number of items that are sorted and filtered in a myriad of ways.
When it becomes evident to a spider that it is possible to mix, match and combine various filter types, it will be sent on an infinite, never-ending loop through a series of filters as a result of all the options available to it.
The use of common filters such as color, size, price, or a number of products per page are some of the many tags that can create issues for a crawler.
How do you identify it?
Look for elongated URL strings and various recurring filtering tags. A never-ending loop within a crawler tool is again a red flag highlighting that your site might not be configured to handle faceted navigation in an SEO-friendly manner.
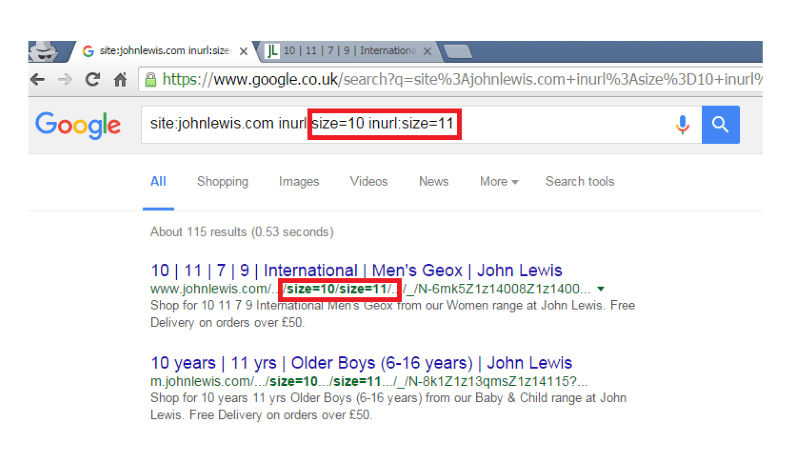
Notice how this spider trap has caused filtered pages to be indexed which could dilute the site’s ranking potential.
How do you fix it?
This is one of the most difficult traps to fix and short of being extremely unhelpful my best advice is to not create the issue in the first place. When setting up your website, try to be restrictive with the number of filters you offer. Some tips include:
Consider implementing the mix and match filtering in JavaScript first.
Limit the extent of the trap by using robots.txt to block pages with too many filters. Be careful to ensure a balance when doing this - block too many and the crawler will no longer be able to find your products.
Calendar Trap
What causes it?
The occurrence of a calendar trap isn’t the result of a technical oversight. Rather, it’s legitimate URLs that relate to time, which as an infinite property can create countless URLs. And as we already know, this can cause significant problems.
How do you identify it?
This is a relatively easy type of spider trap to understand, spot and address. If you have a calendar on your site to enable viewers to navigate and book an event, and it extends all the way to 3016, chances are your site is caught in a calendar trap.
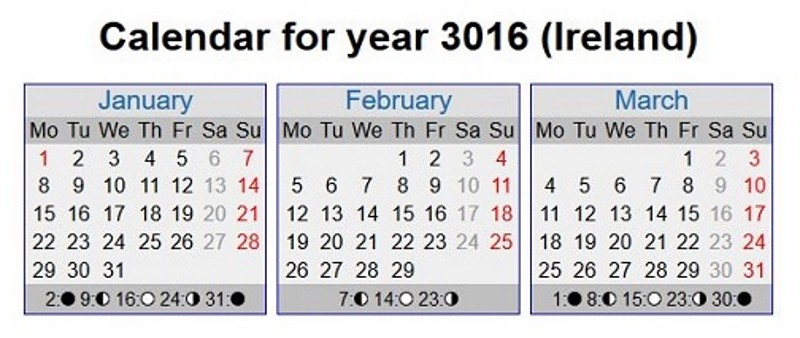
How do you fix it?
Use a ‘noindex, nofollow’ meta tag on ‘beyond reasonable date’ years as an option. Or employ the robots.txt file to disallow any date-specific URLs beyond a specific timeframe. These days, it proves somewhat uncommon, as most website plugins and self-built sites come with these considerations already built into their infrastructure.
Session ID Trap
What causes it?
Session ID Spider traps are common on larger eCommerce sites. They are embedded within the URL of the website and are fundamentally used to track customers as they shop from page to page.
However, the IDs cause problems when they create a vast amount of links for the spider to crawl. The search engine will index the same page over and over with only a small change to the URL.
How do you identify it?
Look out for tags like ‘jsessionid’, ‘sid’, 'affid' or anything similar within the URLs strings as a crawl unfolds, with the same IDs reoccurring beyond a point where the spider can successfully move on the next ID-laden URL string.
http://example.com/somepage?jsessionid=E8B8EA9BACDBEBB5EDECF64F1C3868D3 http://example.com/otherpage?jsessionid=E8B8EA9BACDBEBB5EDECF64F1C3868D3 http://example.com/somepage?jsessionid=3B95930229709341E9D8D7C24510E383 http://example.com/otherpage?jsessionid=3B95930229709341E9D8D7C24510E383 http://example.com/somepage?jsessionid=85931DF798FEC39D18400C5A459A9373 http://example.com/otherpage?jsessionid=85931DF798FEC39D18400C5A459A9373
How do you fix it?
To rectify the issue, it’s crucial to remove the session IDs from all available redirects and links.
What can a spider trap do to your SEO?
A spider trap should be avoided at all costs as it decreases your site’s ability to be crawled and indexed, which in turn will greatly impact your overall organic visibility and rankings.
Spider traps happen due to varying reasons but, they all have the same results on your SEO, including:
Forcing search engines to waste most of their crawl budget loading useless, near-duplicate pages. As a result, the search engines are often so busy with this that they never get around to loading all of the real pages that might otherwise rank well.
If the trap-generated pages are duplicates of a ‘real’ page (e.g. a product page, blog post etc.) then this may prevent the original page from ranking well by diluting link equity.
Quality-ranking algorithms like Google Panda may give the site a bad score because the site appears to consist mostly of low-quality or duplicate pages.
So, there you have it: the complete guide to locating and removing your spider traps. They derive from a variety of causes and vary in their level of severity.
However, they all prove to be a major deterrent to any website’s success. Make sure you do your research before you find yourself caught in this sticky web.
Note: The opinions expressed in this article are the views of the author, and not necessarily the views of Caphyon, its staff, or its partners.

Article by
Fahad Raza
Fahad Raza is a founder of web design agency in Sydney. Started his digital marketing career in 2002. A small business marketing expert who has helped numerous businesses establish and grow their online.



stay in the loop